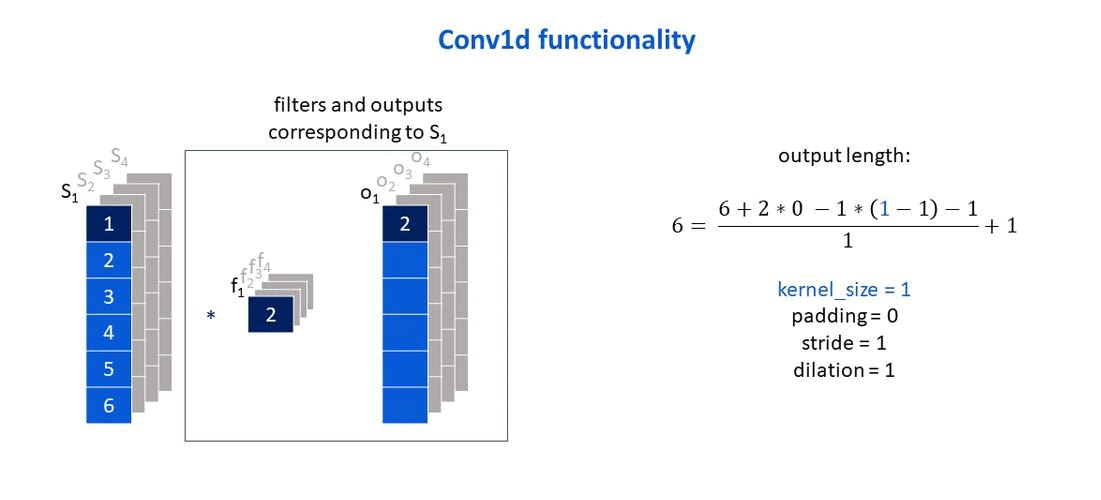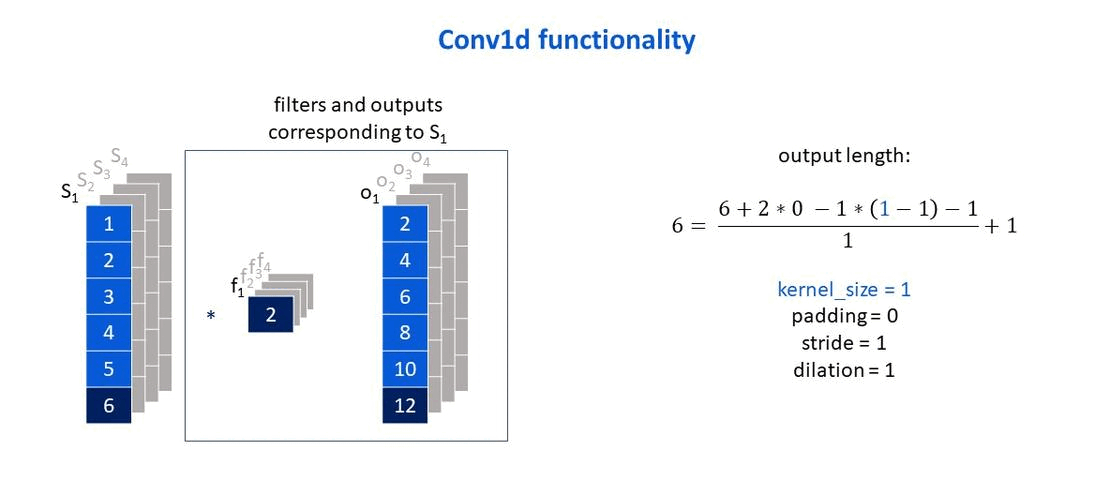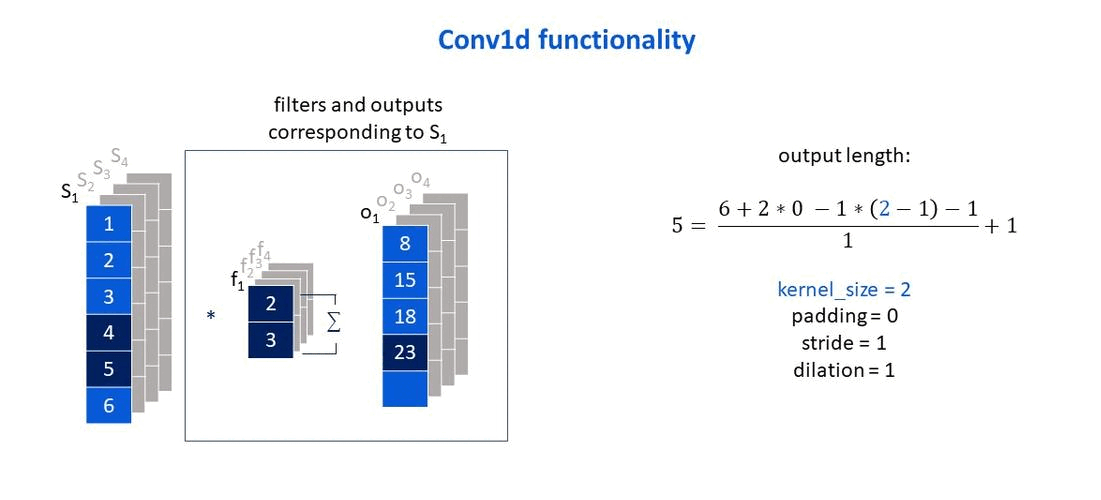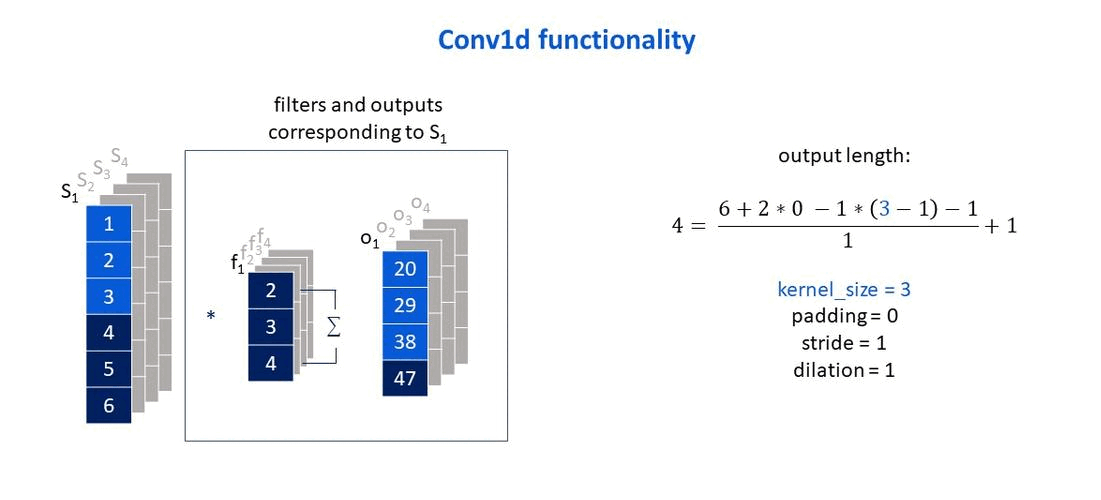

Taken from: Deep learning with R by Chollet and Allaire (2018).

Taken from: Deep learning with R by Chollet and Allaire (2018).

Taken from: Topic 14: neural networks of Larrañaga (2007).
Own elaboration: Elaborated from Jing (2020). Shows how the size of the output vector changes according to the size of the filter that is used.
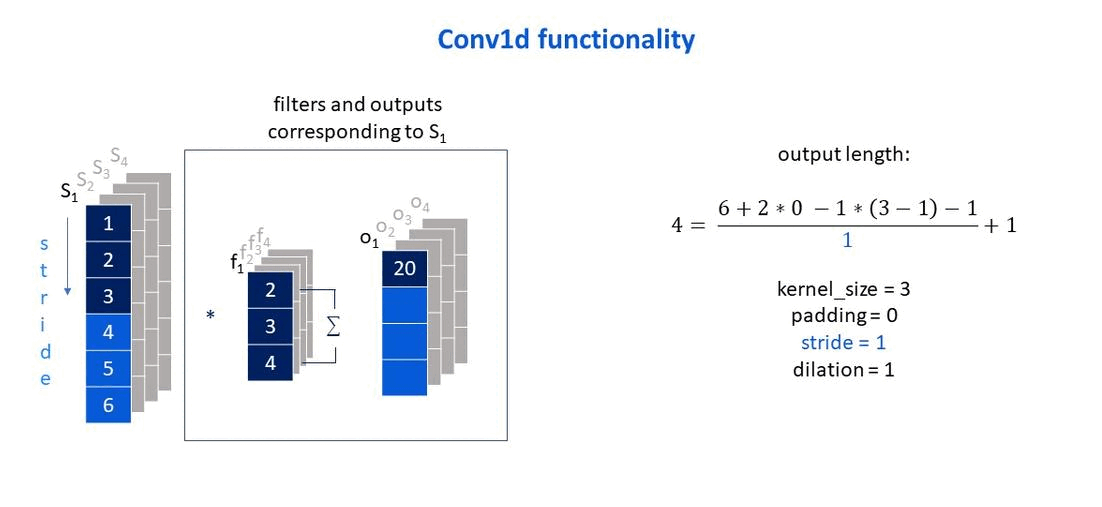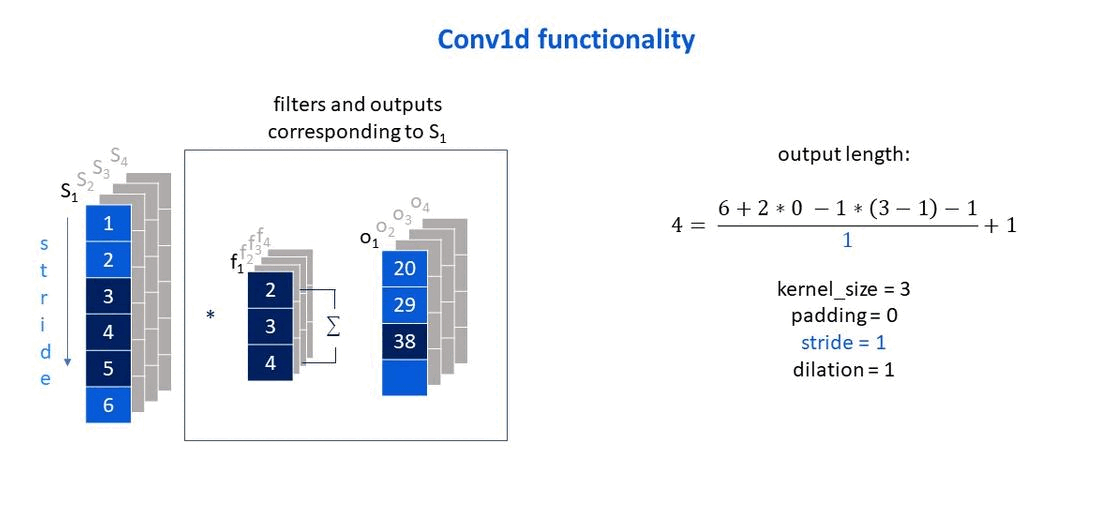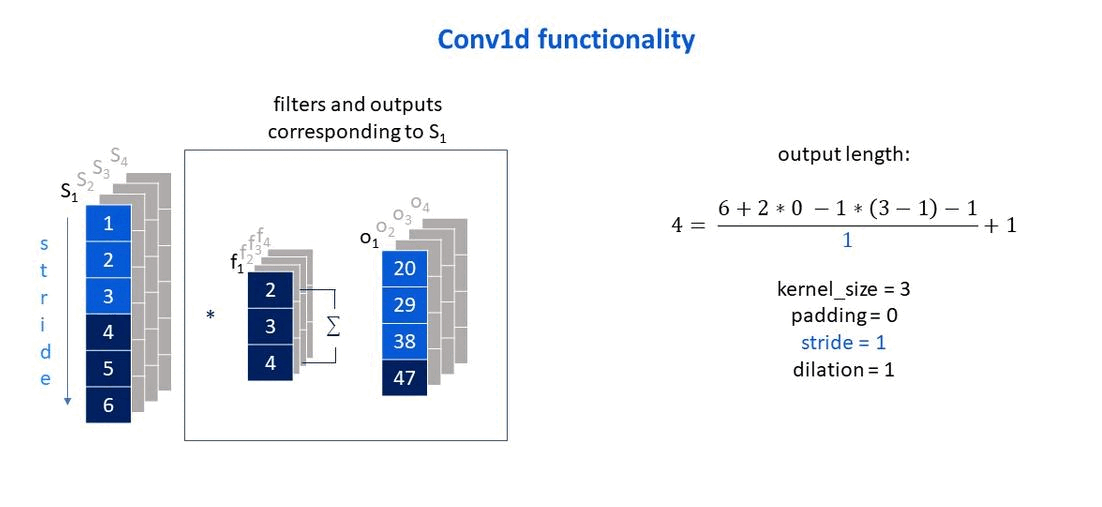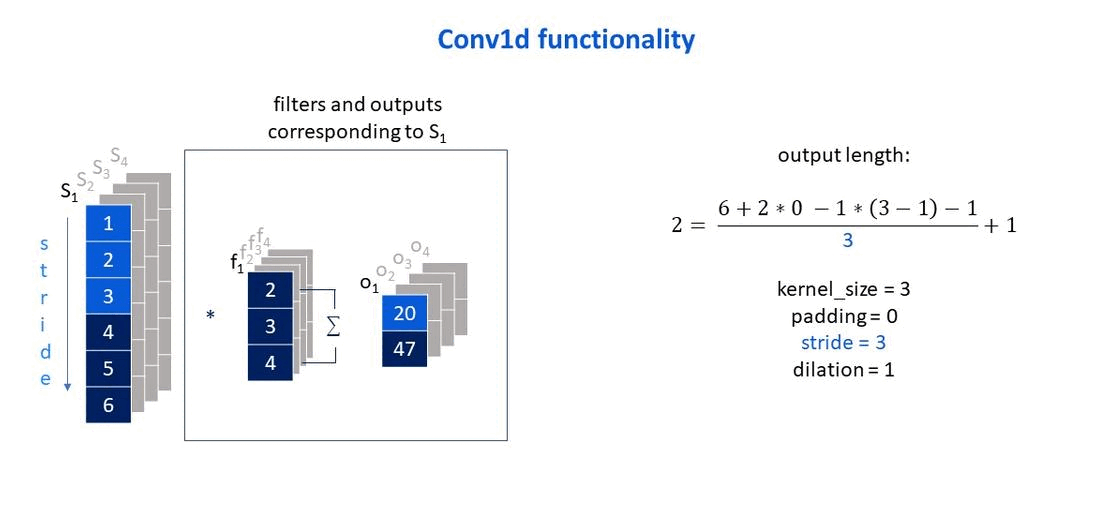
Own elaboration: Elaborated from Jing (2020). Shows how the stride parameter affects the size of the output vector.
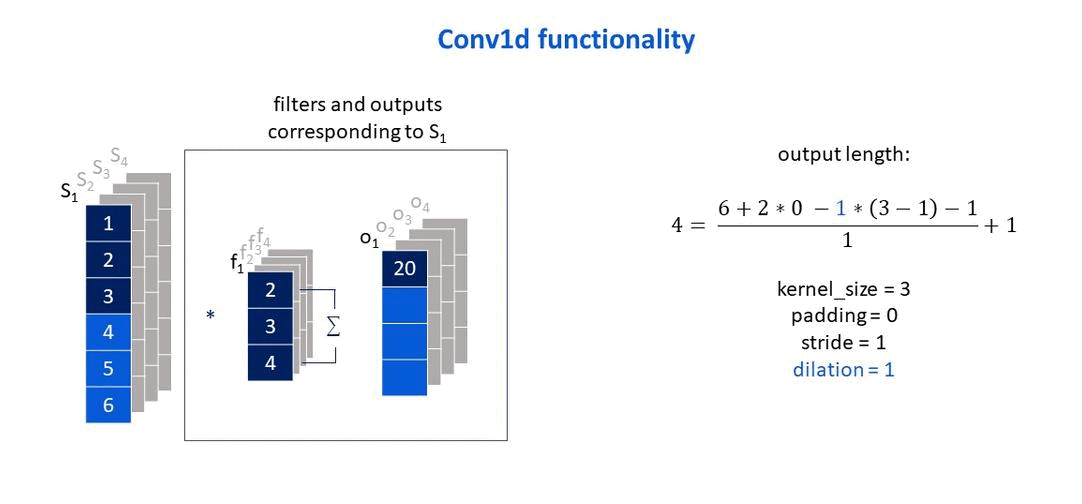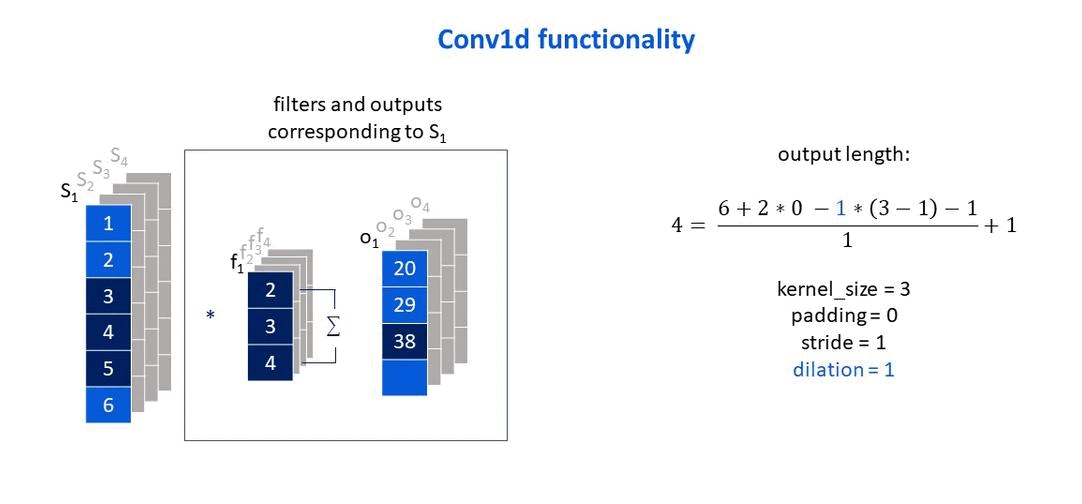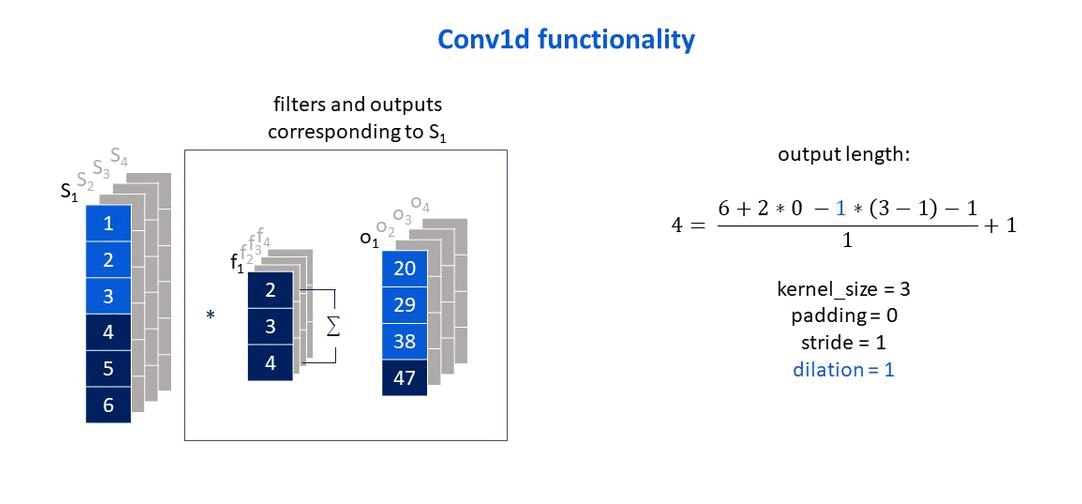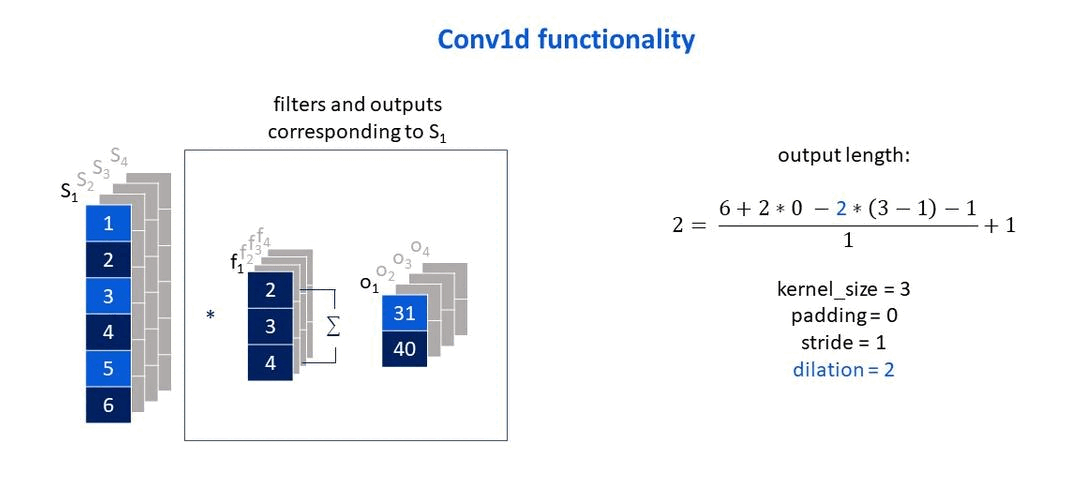
Own elaboration: Elaborated from Jing (2020). Show how the dilation parameter affects the size of the output vector.
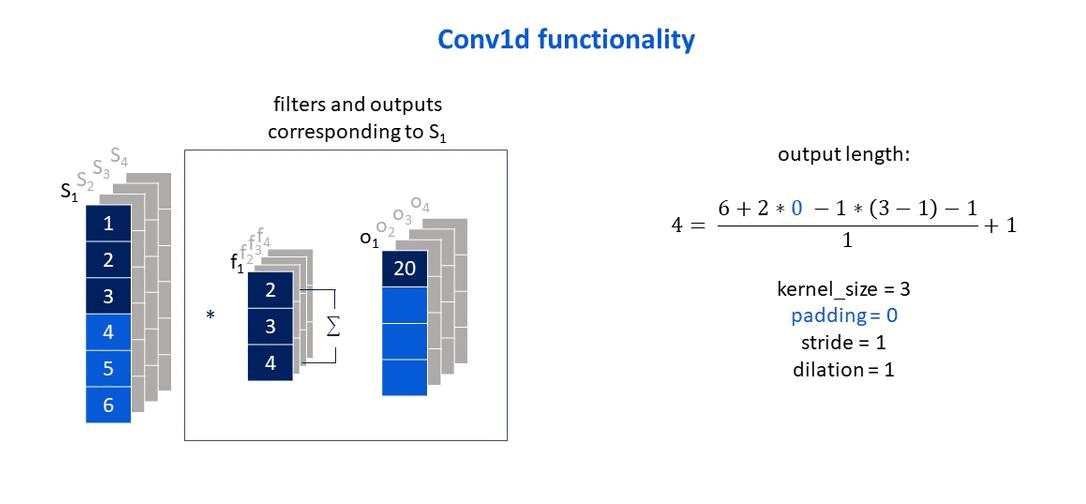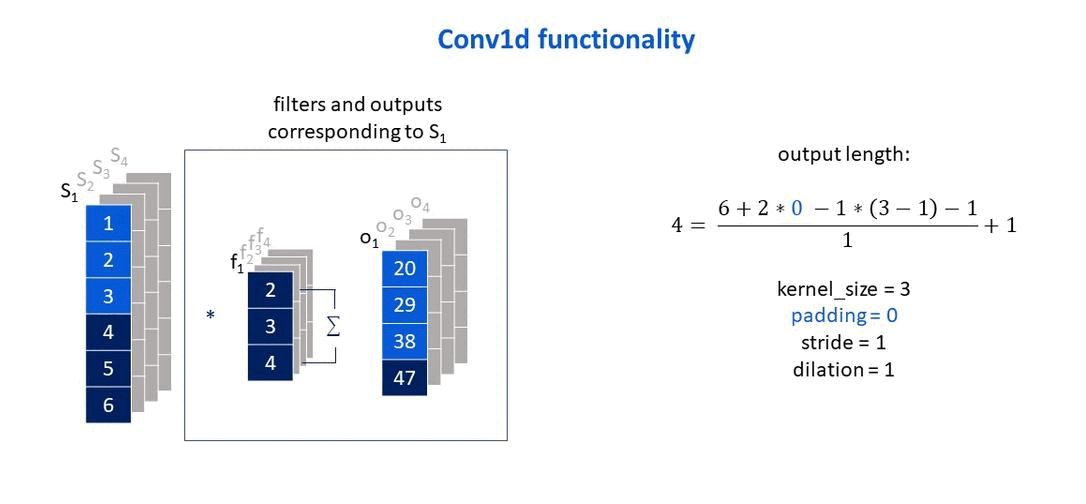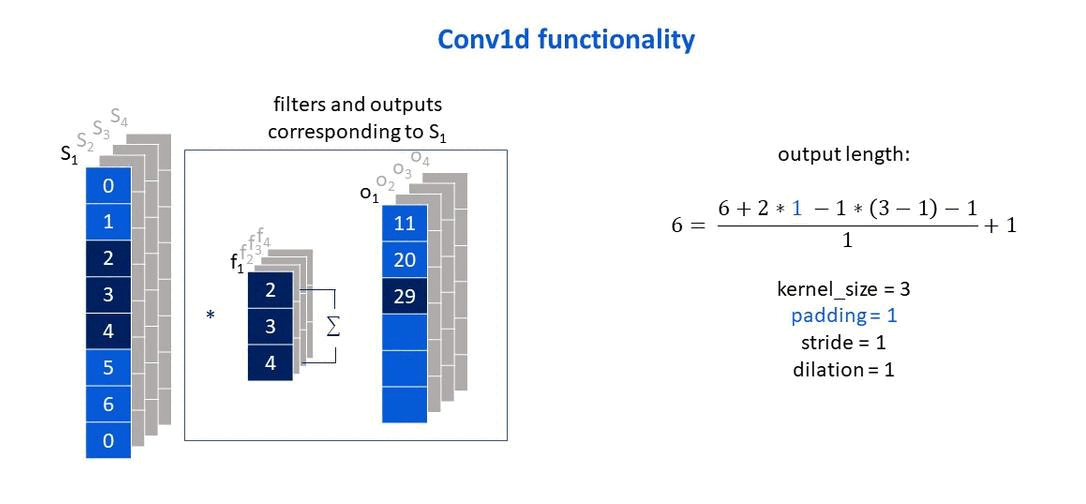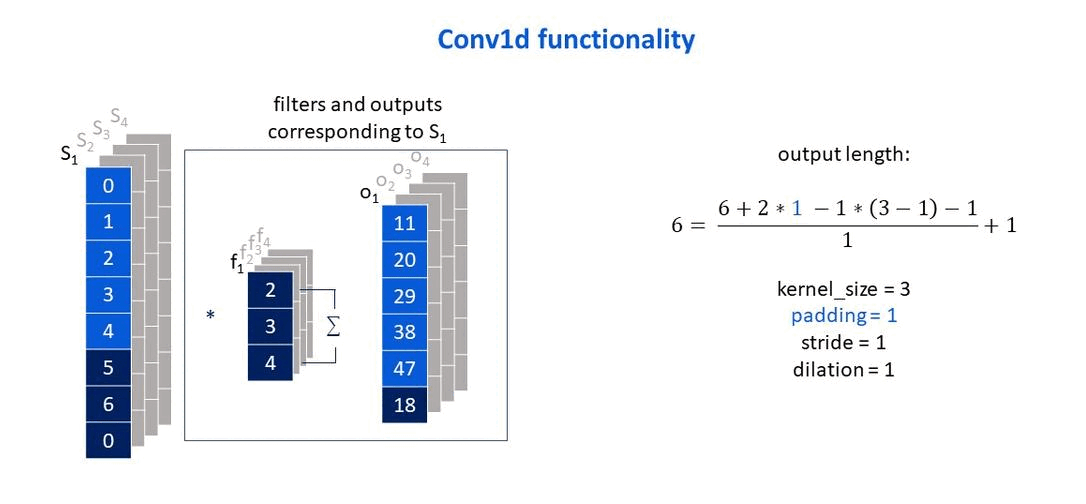
Own elaboration: Elaborated from Jing (2020). Show how the padding parameter affects the size of the output vector.

Taken from: Understanding LSTM networks, Olah (2015).

Taken from: Understanding LSTM networks, Olah (2015).

Taken from: Understanding LSTM networks, Olah (2015).

Taken from: Understanding LSTM networks, Olah (2015).

Taken from: Understanding LSTM networks, Olah (2015).

Taken from: Understanding LSTM networks, Olah (2015).

Taken from: Understanding LSTM networks, Olah (2015).

Taken from: Understanding LSTM networks, Olah (2015).

Own elaboration: Made from an image in Chollet and Allaire (2018). It shows what the three-dimensional input and output vectors for a company’s data look like, if three observations are used to create the input vector.
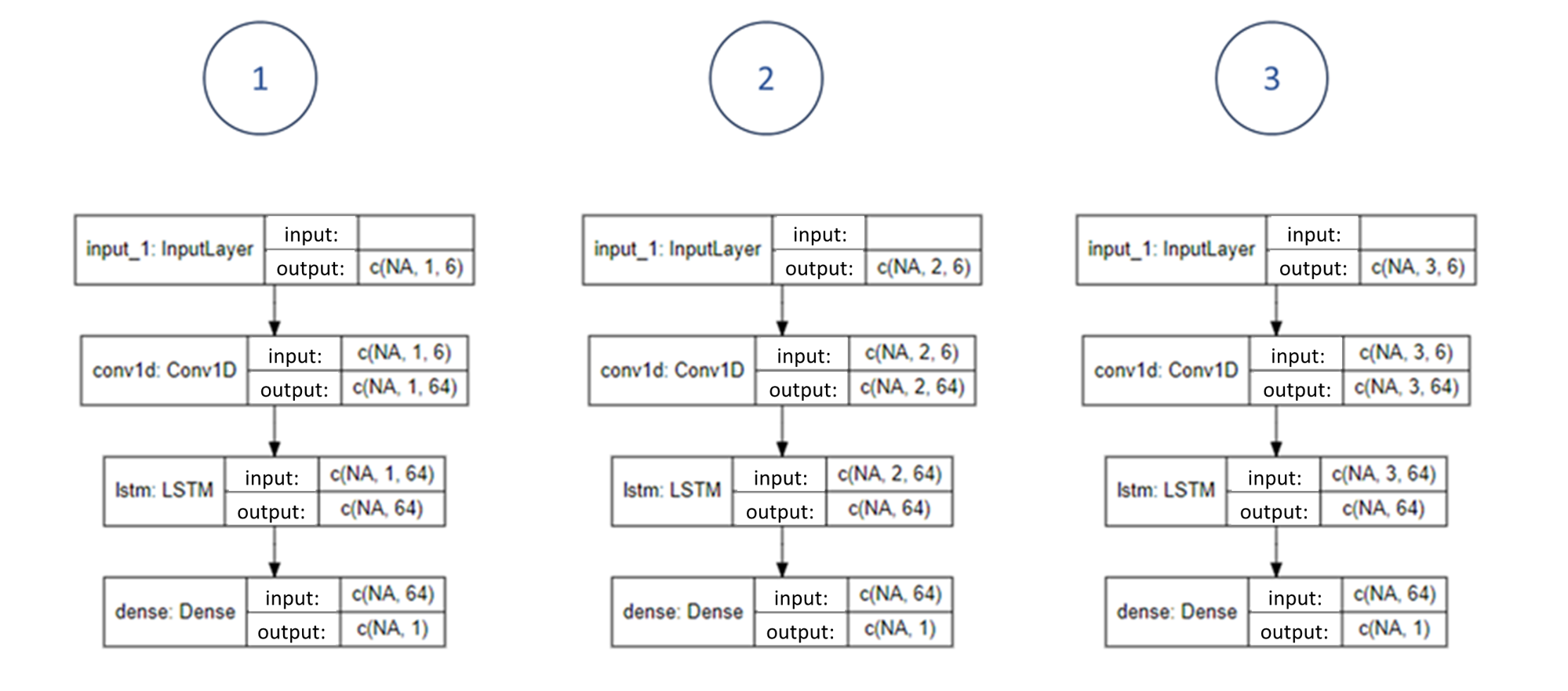
Own elaboration: Elaborated from the different models built using the keras and tensorflow packages in R and were graphed using the Iannone (2023) package.
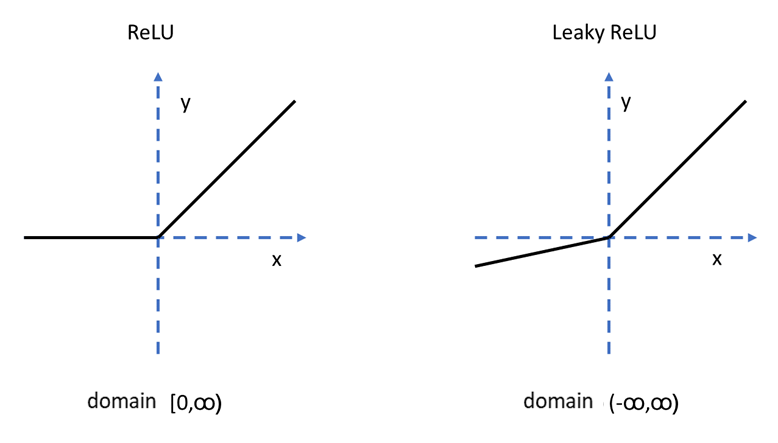
Own elaboration: Elaborated from the images that can be seen in Rallabandi (2023).
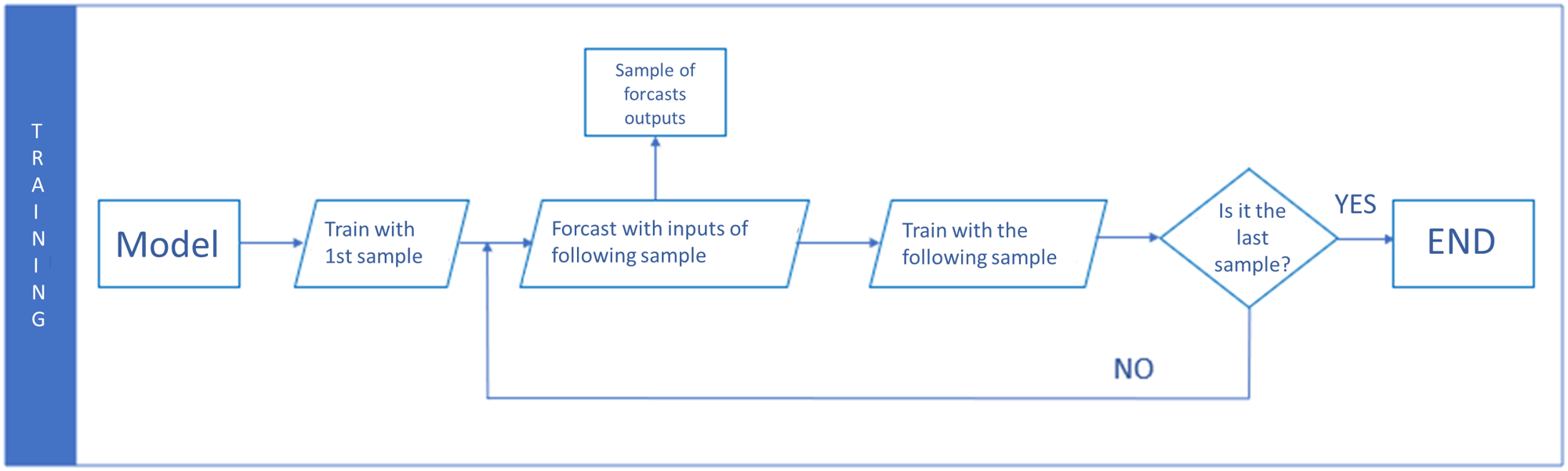
Own elaboration