Para el modelado estadístico en R, la representación preferida para datos categóricos o nominales es un factor, que es una variable que puede tomar un número limitado de valores diferentes; internamente, los factores se almacenan como un vector de valores enteros junto con un conjunto de etiquetas de texto.1 En Sección 8.4.1 introdujimos enfoques de ingeniería de características para codificar o transformar datos cualitativos o nominales en una representación más adecuada para la mayoría de los algoritmos modelo. Discutimos cómo transformar una variable categórica, como Bldg_Type en nuestros datos de vivienda de Ames (con niveles OneFam, TwoFmCon, Duplex, Twnhs, and TwnhsE), en un conjunto de Variables ficticias o indicadoras como las que se muestran en Tabla 17.1.
Tabla 17.1: Codificaciones de variables ficticias o indicadoras para el predictor de tipo de edificio en el conjunto de entrenamiento de Ames.
Raw Data
TwoFmCon
Duplex
Twnhs
TwnhsE
OneFam
0
0
0
0
TwoFmCon
1
0
0
0
Duplex
0
1
0
0
Twnhs
0
0
1
0
TwnhsE
0
0
0
1
Muchas implementaciones de modelos requieren dicha transformación a una representación numérica para datos categóricos.
Apéndice A presenta una tabla de técnicas de preprocesamiento recomendadas para diferentes modelos; observe cuántos de los modelos de la tabla requieren una codificación numérica para todos los predictores.
Sin embargo, para algunos conjuntos de datos realistas, las variables ficticias sencillas no son una buena opción. Esto sucede a menudo porque hay demasiadas categorías o hay categorías nuevas en el momento de la predicción. En este capítulo, analizamos opciones más sofisticadas para codificar predictores categóricos que abordan estos problemas. Estas opciones están disponibles como pasos de recetas de tidymodels en embed y textrecipes paquetes.
17.1 ¿Es Necesaria Una Codificación?
Una minoría de modelos, como los basados en árboles o reglas, pueden manejar datos categóricos de forma nativa y no requieren codificación ni transformación de este tipo de características. Un modelo basado en árbol puede dividir de forma nativa una variable como Bldg_Type en grupos de niveles de factores, tal vez OneFam solo en un grupo y Duplex y Twnhs juntos en otro grupo. Los modelos Naive Bayes son otro ejemplo en el que la estructura del modelo puede tratar variables categóricas de forma nativa; las distribuciones se calculan dentro de cada nivel, por ejemplo, para todos los diferentes tipos de Bldg_Type en el conjunto de datos.
Estos modelos que pueden manejar características categóricas de forma nativa también pueden manejar características numéricas continuas, lo que hace que la transformación o codificación de dichas variables sea opcional. ¿Esto ayuda de alguna manera, quizás con el rendimiento del modelo o con el tiempo para entrenar modelos? Normalmente no, como muestra la Sección 5.7 de Kuhn y Johnson (2020) utilizando conjuntos de datos de referencia con variables factoriales no transformadas en comparación con variables ficticias transformadas para esas mismas características. En resumen, el uso de codificaciones ficticias normalmente no daba como resultado un mejor rendimiento del modelo, pero a menudo requería más tiempo para entrenar los modelos.
Recomendamos comenzar con variables categóricas no transformadas cuando un modelo lo permita; tenga en cuenta que las codificaciones más complejas a menudo no dan como resultado un mejor rendimiento para dichos modelos.
17.2 Codificación De Predictores Ordinales
A veces, las columnas cualitativas se pueden ordenar, como “baja”, “media” y “alta”. En base R, la estrategia de codificación predeterminada es crear nuevas columnas numéricas que sean expansiones polinómicas de los datos. Para las columnas que tienen cinco valores ordinales, como el ejemplo que se muestra en Tabla 17.2, la columna de factores se reemplaza con columnas para términos lineales, cuadráticos, cúbicos y cuárticos:
Tabla 17.2: Polynominal expansions for encoding an ordered variable.
Raw Data
Linear
Quadratic
Cubic
Quartic
none
-0.63
0.53
-0.32
0.12
a little
-0.32
-0.27
0.63
-0.48
some
0.00
-0.53
0.00
0.72
a bunch
0.32
-0.27
-0.63
-0.48
copious amounts
0.63
0.53
0.32
0.12
Si bien esto no es descabellado, no es un enfoque que la gente tienda a encontrar útil. Por ejemplo, un polinomio de 11 grados probablemente no sea la forma más eficaz de codificar un factor ordinal para los meses del año. En su lugar, considere probar pasos de recetas relacionados con factores ordenados, como step_unorder(), para convertir a factores regulares, y step_ordinalscore(), que asigna valores numéricos específicos a cada nivel de factor.
17.3 Uso Del Resultado Para Codificar Predictores
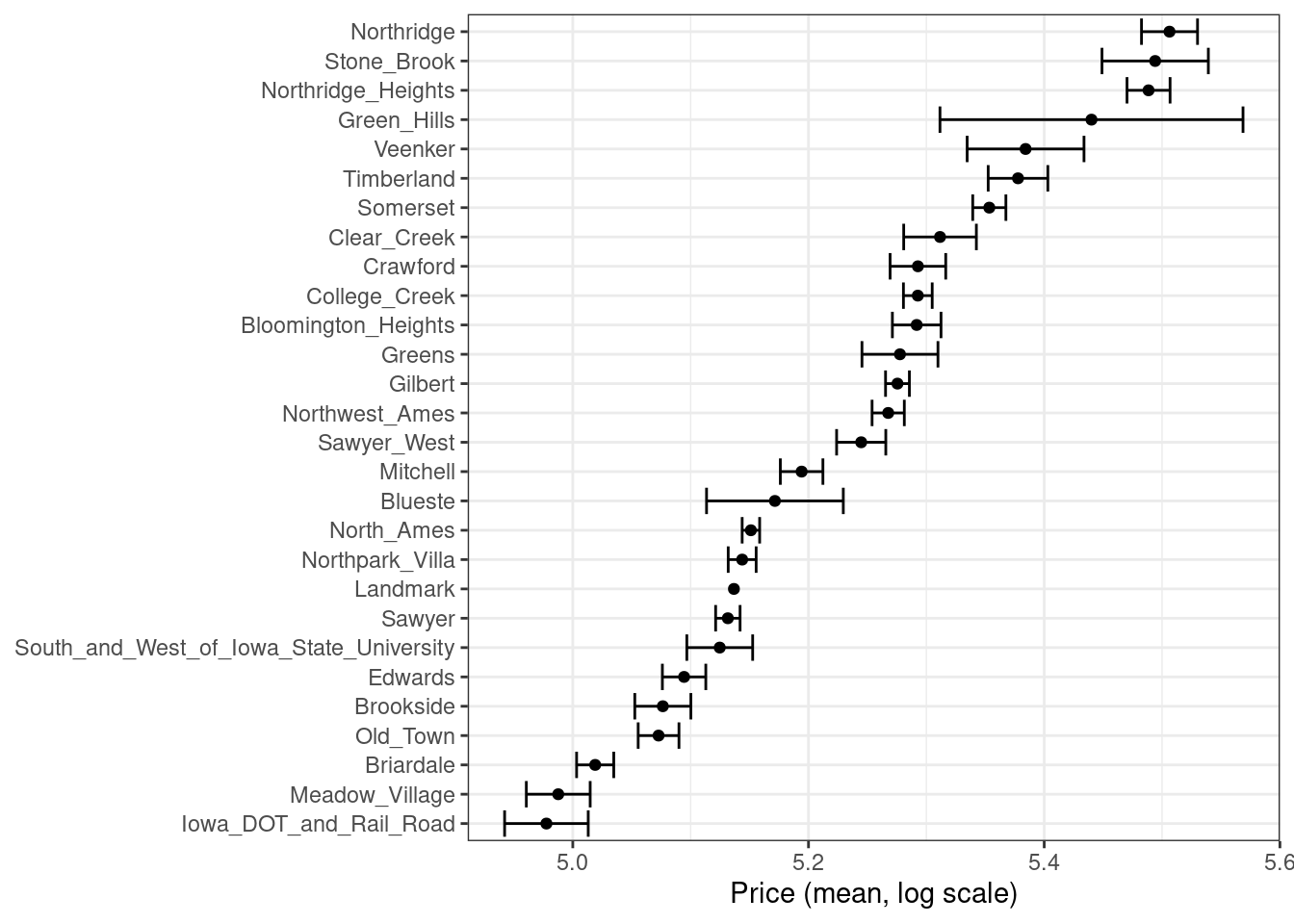
Existen múltiples opciones para codificaciones más complejas que las variables ficticias o indicadoras. Un método llamado efecto o codificaciones de probabilidad reemplaza las variables categóricas originales con una sola columna numérica que mide el efecto de esos datos (Micci-Barreca 2001; Zumel y Mount 2019). Por ejemplo, para el predictor de vecindario en los datos de vivienda de Ames, podemos calcular el precio de venta medio o mediano para cada vecindario (como se muestra en Figura 17.1) y sustituir estos medios por los valores de los datos originales:
ames_train%>%group_by(Neighborhood)%>%summarize(mean =mean(Sale_Price), std_err =sd(Sale_Price)/sqrt(length(Sale_Price)))%>%ggplot(aes(y =reorder(Neighborhood, mean), x =mean))+geom_point()+geom_errorbar(aes(xmin =mean-1.64*std_err, xmax =mean+1.64*std_err))+labs(y =NULL, x ="Price (mean, log scale)")
Figura 17.1: Precio medio de la vivienda para vecindarios en el conjunto de entrenamiento de Ames, que puede usarse como codificación de efecto para esta variable categórica
Este tipo de codificación de efectos funciona bien cuando su variable categórica tiene muchos niveles. En tidymodels, el paquete embed incluye varias funciones de pasos de recetas para diferentes tipos de codificaciones de efectos, como step_lencode_glm(), step_lencode_mixed() y step_lencode_bayes(). Estos pasos utilizan un modelo lineal generalizado para estimar el efecto de cada nivel en un predictor categórico sobre el resultado. Cuando utilice un paso de receta como step_lencode_glm(), especifique primero la variable que se codifica y luego el resultado usando vars():
library(embed)ames_glm<-recipe(Sale_Price~Neighborhood+Gr_Liv_Area+Year_Built+Bldg_Type+Latitude+Longitude, data =ames_train)%>%step_log(Gr_Liv_Area, base =10)%>%step_lencode_glm(Neighborhood, outcome =vars(Sale_Price))%>%step_dummy(all_nominal_predictors())%>%step_interact(~Gr_Liv_Area:starts_with("Bldg_Type_"))%>%step_ns(Latitude, Longitude, deg_free =20)ames_glm## ## ── Recipe ───────────────────────────────────────────────────────────────────────────## ## ── Inputs## Number of variables by role## outcome: 1## predictor: 6## ## ── Operations## • Log transformation on: Gr_Liv_Area## • Linear embedding for factors via GLM for: Neighborhood## • Dummy variables from: all_nominal_predictors()## • Interactions with: Gr_Liv_Area:starts_with("Bldg_Type_")## • Natural splines on: Latitude and Longitude
Como se detalla en Sección 16.4, podemos preparar, prep(), nuestra receta para ajustar o estimar parámetros para las transformaciones de preprocesamiento utilizando datos de entrenamiento. Luego podemos tidy() esta receta preparada para ver los resultados:
Cuando utilizamos la variable numérica Neighborhood recién codificada creada mediante este método, sustituimos el nivel original (como "North_Ames") con la estimación de Sale_Price del GLM.
Los métodos de codificación de efectos como este también pueden manejar sin problemas situaciones en las que se encuentra un nivel de factor novedoso en los datos. Este “valor” es el precio previsto por el GLM cuando no tenemos ninguna información específica del vecindario:
glm_estimates%>%filter(level=="..new")## # A tibble: 1 × 4## level value terms id ## <chr> <dbl> <chr> <chr> ## 1 ..new 5.23 Neighborhood lencode_glm_ZsXdy
Las codificaciones de efectos pueden ser poderosas, pero deben usarse con cuidado. Los efectos deben calcularse a partir del conjunto de entrenamiento, después de dividir los datos. Este tipo de preprocesamiento supervisado debe remuestrearse rigurosamente para evitar el sobreajuste (consulte el Capítulo 10).
Cuando crea una codificación de efecto para su variable categórica, efectivamente está superponiendo un minimodelo dentro de su modelo real. La posibilidad de sobreajustar con codificaciones de efectos es un ejemplo representativo de por qué la ingeniería de características debe considerarse parte del proceso del modelo, como se describe en el Capítulo 7, y por qué la ingeniería de características debe estimarse junto con los parámetros del modelo dentro del remuestreo. .
17.3.1 Codificaciones de efectos con agrupación parcial
La creación de una codificación de efecto con step_lencode_glm() estima el efecto por separado para cada nivel de factor (en este ejemplo, vecindad). Sin embargo, algunos de estos vecindarios tienen muchas casas y otros tienen solo unas pocas. Hay mucha más incertidumbre en nuestra medición del precio para el conjunto de entrenamiento único que se encuentra en el vecindario Landmark que en el 354 casas de entrenamiento en North Ames. Podemos utilizar agrupación parcial para ajustar estas estimaciones de modo que los niveles con tamaños de muestra pequeños se reduzcan hacia la media general. Los efectos para cada nivel se modelan todos a la vez utilizando un modelo lineal generalizado mixto o jerárquico:
ames_mixed<-recipe(Sale_Price~Neighborhood+Gr_Liv_Area+Year_Built+Bldg_Type+Latitude+Longitude, data =ames_train)%>%step_log(Gr_Liv_Area, base =10)%>%step_lencode_mixed(Neighborhood, outcome =vars(Sale_Price))%>%step_dummy(all_nominal_predictors())%>%step_interact(~Gr_Liv_Area:starts_with("Bldg_Type_"))%>%step_ns(Latitude, Longitude, deg_free =20)ames_mixed## ## ── Recipe ───────────────────────────────────────────────────────────────────────────## ## ── Inputs## Number of variables by role## outcome: 1## predictor: 6## ## ── Operations## • Log transformation on: Gr_Liv_Area## • Linear embedding for factors via mixed effects for: Neighborhood## • Dummy variables from: all_nominal_predictors()## • Interactions with: Gr_Liv_Area:starts_with("Bldg_Type_")## • Natural splines on: Latitude and Longitude
Vamos a prep() y tidy() esta receta para ver los resultados:
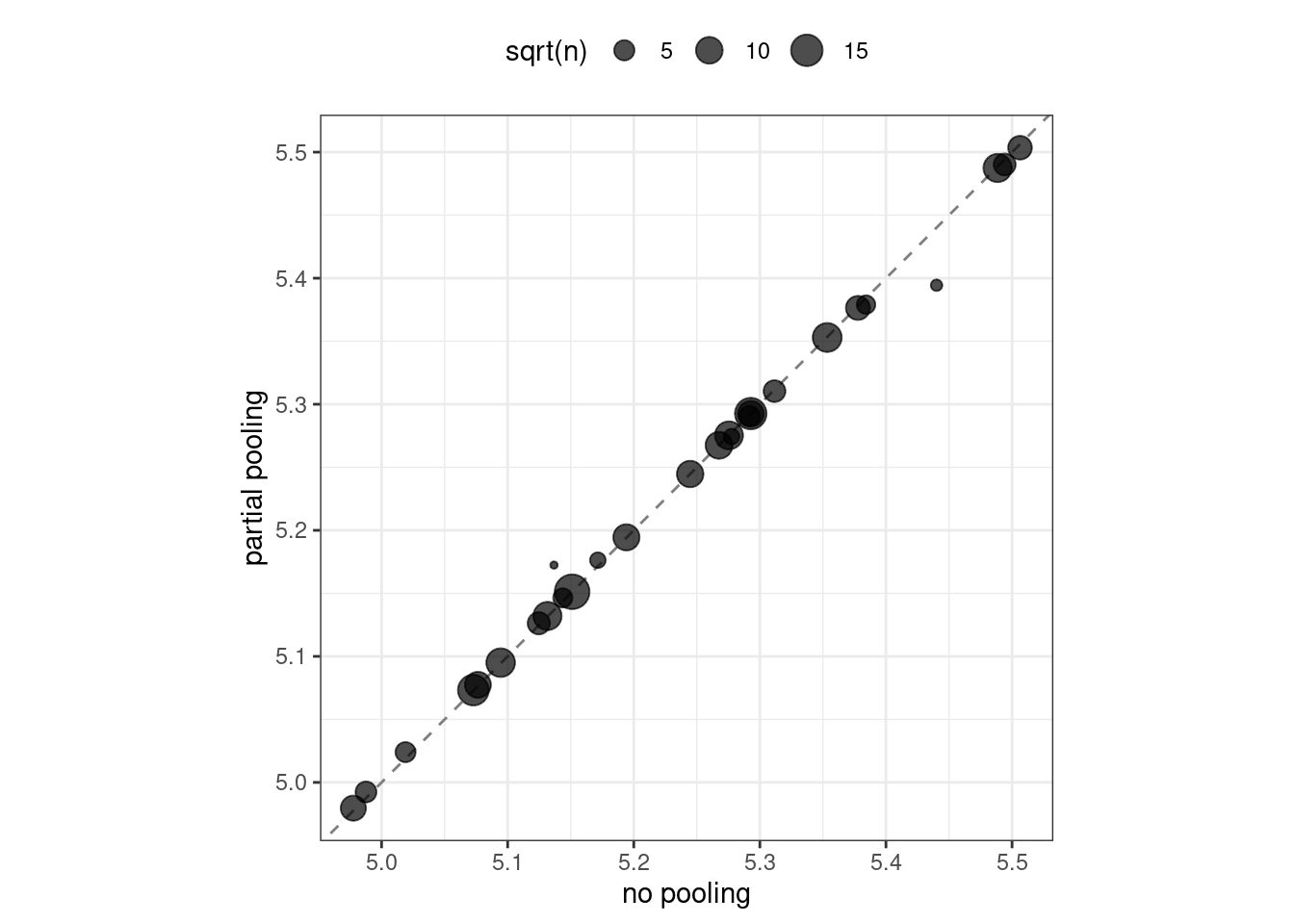
Figura 17.2: Comparación de las codificaciones de efectos para el vecindario estimado sin agrupación con aquellas con agrupación parcial
Observe en Figura 17.2 que la mayoría de las estimaciones de los efectos de vecindad son aproximadamente las mismas cuando comparamos la agrupación con la no agrupación. Sin embargo, los barrios con menos viviendas se han visto arrastrados (ya sea hacia arriba o hacia abajo) hacia el efecto medio. Cuando utilizamos la agrupación, reducimos las estimaciones del efecto hacia la media porque no tenemos tanta evidencia sobre el precio en esos vecindarios.
17.4 Hashing De Características
Las variables ficticias tradicionales, como se describe en Sección 8.4.1, requieren que se conozcan todas las categorías posibles para crear un conjunto completo de características numéricas. Los métodos de hash de funciones(Weinberger et al. 2009) también crean variables ficticias, pero solo consideran el valor de la categoría para asignarla a un grupo predefinido de variables ficticias. Miremos nuevamente los valores de Neighborhood en Ames y usemos la función rlang::hash() para entender más:
Si ingresamos Briardale a esta función hash, siempre obtendremos el mismo resultado. En este caso, las vecindades se denominan “claves”, mientras que las salidas son “hashes”.
Una función hash toma una entrada de tamaño variable y la asigna a una salida de tamaño fijo. Las funciones hash se utilizan comúnmente en criptografía y bases de datos.
La función rlang::hash() genera un hash de 128 bits, lo que significa que hay 2^128 valores hash posibles. Esto es excelente para algunas aplicaciones, pero no ayuda con el hash de funciones de variables de alta cardinalidad (variables con muchos niveles). En el hash de características, el número de hashes posibles es un hiperparámetro y lo establece el desarrollador del modelo calculando el módulo de los hashes enteros. Podemos obtener dieciséis valores hash posibles usando Hash %% 16:
ames_hashed%>%## primero haga un hash más pequeño para números enteros que R pueda manejarmutate(Hash =strtoi(substr(Hash, 26, 32), base =16L), ## ahora toma el módulo Hash =Hash%%16)%>%select(Neighborhood, Hash)## # A tibble: 2,342 × 2## Neighborhood Hash## <fct> <dbl>## 1 North_Ames 9## 2 North_Ames 9## 3 Briardale 0## 4 Briardale 0## 5 Northpark_Villa 4## 6 Northpark_Villa 4## # ℹ 2,336 more rows
Ahora, en lugar de los vecindarios 28 en nuestros datos originales o una cantidad increíblemente grande de hashes originales, tenemos dieciséis valores hash. Este método es muy rápido y eficiente en cuanto a memoria, y puede ser una buena estrategia cuando hay una gran cantidad de categorías posibles.
El hash de características es útil para datos de texto, así como para datos categóricos de alta cardinalidad. Consulte la Sección 6.7 de Hvitfeldt y Silge (2021) para ver una demostración de un estudio de caso con predictores de texto.
Podemos implementar hash de características usando un paso de receta tidymodels del paquete textrecipes:
library(textrecipes)ames_hash<-recipe(Sale_Price~Neighborhood+Gr_Liv_Area+Year_Built+Bldg_Type+Latitude+Longitude, data =ames_train)%>%step_log(Gr_Liv_Area, base =10)%>%step_dummy_hash(Neighborhood, signed =FALSE, num_terms =16L)%>%step_dummy(all_nominal_predictors())%>%step_interact(~Gr_Liv_Area:starts_with("Bldg_Type_"))%>%step_ns(Latitude, Longitude, deg_free =20)ames_hash## ## ── Recipe ───────────────────────────────────────────────────────────────────────────## ## ── Inputs## Number of variables by role## outcome: 1## predictor: 6## ## ── Operations## • Log transformation on: Gr_Liv_Area## • Feature hashing with: Neighborhood## • Dummy variables from: all_nominal_predictors()## • Interactions with: Gr_Liv_Area:starts_with("Bldg_Type_")## • Natural splines on: Latitude and Longitude
El hash de funciones es rápido y eficiente, pero tiene algunas desventajas. Por ejemplo, diferentes valores de categorías a menudo se asignan al mismo valor hash. Esto se llama colisión o aliasing. ¿Con qué frecuencia sucedió esto en nuestros vecindarios de Ames? Tabla 17.3 presenta la distribución del número de vecindarios por valor hash.
Tabla 17.3: La cantidad de características hash en cada número de vecindarios.
Número de vecindarios dentro de una característica hash
Numero de incidentes
0
1
1
7
2
4
3
3
4
1
El número de vecindades asignadas a cada valor hash varía entre zero y four. Todos los valores hash mayores que uno son ejemplos de colisiones hash.
¿Cuáles son algunas cosas a considerar al utilizar hash de funciones?
El hash de características no se puede interpretar directamente porque las funciones hash no se pueden revertir. No podemos determinar cuáles eran los niveles de categoría de entrada a partir del valor hash o si ocurrió una colisión.
El número de valores hash es un parámetro de ajuste de esta técnica de preprocesamiento, y debes probar varios valores para determinar cuál es mejor para tu enfoque de modelado particular. Una cantidad menor de valores hash da como resultado más colisiones, pero una cantidad alta puede no ser una mejora con respecto a la variable de cardinalidad alta original.
El hash de características puede manejar nuevos niveles de categorías en el momento de la predicción, ya que no depende de variables ficticias predeterminadas.
Puedes reducir las colisiones de hash con un hash firmado usando signed = TRUE. Esto expande los valores de solo 1 a +1 o -1, según el signo del hash.
Es probable que algunas columnas hash contengan solo ceros, como vemos en este ejemplo. Recomendamos un filtro de variación cero a través de step_zv() para filtrar dichas columnas.
17.5 Más Opciones De Codificación
Hay aún más opciones disponibles para transformar factores a una representación numérica.
Podemos construir un conjunto completo de incrustaciones de entidades(Guo y Berkhahn 2016) para transformar una variable categórica con muchos niveles en un conjunto de vectores de dimensiones inferiores. Este enfoque se adapta mejor a una variable nominal con muchos niveles de categoría, muchos más que el ejemplo que hemos usado con los barrios de Ames.
La idea de incrustaciones de entidades proviene de los métodos utilizados para crear incrustaciones de palabras a partir de datos de texto. Consulte el Capítulo 5 de Hvitfeldt y Silge (2021) para obtener más información sobre la incrustación de palabras.
Las incrustaciones de una variable categórica se pueden aprender a través de una red neuronal TensorFlow con la función step_embed() en embed. Podemos usar el resultado solo o, opcionalmente, el resultado más un conjunto de predictores adicionales. Al igual que en el hashing de funciones, la cantidad de nuevas columnas de codificación que se crearán es un hiperparámetro de la ingeniería de funciones. También debemos tomar decisiones sobre la estructura de la red neuronal (la cantidad de unidades ocultas) y cómo ajustar la red neuronal (cuántas épocas entrenar, cuántos datos usar para la validación en la medición de métricas).
Una opción más disponible para abordar un resultado binario es transformar un conjunto de niveles de categorías en función de su asociación con el resultado binario. Esta transformación de peso de la evidencia (WoE) (Good 1985) utiliza el logaritmo del “factor Bayes” (la relación entre las probabilidades posteriores y las probabilidades anteriores) y crea un diccionario que asigna cada nivel de categoría a un valor WoE. Las codificaciones WoE se pueden determinar con la función step_woe() en embed.
17.6 Resumen Del capítulo
En este capítulo, aprendió a utilizar recetas de preprocesamiento para codificar predictores categóricos. La opción más sencilla para transformar una variable categórica en una representación numérica es crear variables ficticias a partir de los niveles, pero esta opción no funciona bien cuando tienes una variable con alta cardinalidad (demasiados niveles) o cuando puedes ver valores novedosos en tiempo de predicción (nuevos niveles). Una opción en tal situación es crear codificaciones de efectos, un método de codificación supervisado que utiliza el resultado. Las codificaciones de efectos se pueden aprender agrupando o sin las categorías. Otra opción utiliza una función hashing para asignar niveles de categoría a un conjunto nuevo y más pequeño de variables ficticias. El hash de funciones es rápido y ocupa poca memoria. Otras opciones incluyen incorporaciones de entidades (aprendidas a través de una red neuronal) y transformación del peso de la evidencia.
La mayoría de los algoritmos modelo requieren algún tipo de transformación o codificación de este tipo para variables categóricas. Una minoría de modelos, incluidos los basados en árboles y reglas, pueden manejar variables categóricas de forma nativa y no requieren dichas codificaciones.
Good, I. J. 1985. «Weight of evidence: A brief survey». Bayesian Statistics 2: 249-70.
Hvitfeldt, E., y J. Silge. 2021. Supervised Machine Learning for Text Analysis in R. A Chapman & Hall libro. CRC Press. https://smltar.com/.
Kuhn, M, y K Johnson. 2020. Feature engineering and selection: A practical approach for predictive models. CRC Press.
Micci-Barreca, Daniele. 2001. «A Preprocessing Scheme for High-Cardinality Categorical Attributes in Classification and Prediction Problems». SIGKDD Explor. Newsl. 3 (1): 27-32. https://doi.org/10.1145/507533.507538.
Weinberger, K, A Dasgupta, J Langford, A Smola, y J Attenberg. 2009. «Feature hashing for large scale multitask learning». En Proceedings of the 26th Annual International Conference on Machine Learning, 1113-20. ACM.
Esto contrasta con el modelado estadístico en Python, donde las variables categóricas a menudo se representan directamente solo con números enteros, como “0, 1, 2” que representa rojo, azul y verde.↩︎