pak::pkg_deps_tree("tibble")
#> tibble 3.1.8 ✨
#> ├─fansi 1.0.3 ✨
#> ├─lifecycle 1.0.3 ✨
#> │ ├─cli 3.4.1 ✨ ⬇ (1.28 MB)
#> │ ├─glue 1.6.2 ✨
#> │ └─rlang 1.0.6 ✨ ⬇ (1.81 MB)
#> ├─magrittr 2.0.3 ✨
#> ├─pillar 1.8.1 ✨ ⬇ (673.95 kB)
#> │ ├─cli
#> │ ├─fansi
#> │ ├─glue
#> │ ├─lifecycle
#> │ ├─rlang
#> │ ├─utf8 1.2.2 ✨
#> │ └─vctrs 0.5.1 ✨ ⬇ (1.82 MB)
#> │ ├─cli
#> │ ├─glue
#> │ ├─lifecycle
#> │ └─rlang
#> ├─pkgconfig 2.0.3 ✨
#> ├─rlang
#> └─vctrs
#>
#> Key: ✨ new | ⬇ download
pak::pkg_deps_explain("tibble", "rlang")
#> tibble -> lifecycle -> rlang
#> tibble -> pillar -> lifecycle -> rlang
#> tibble -> pillar -> rlang
#> tibble -> pillar -> vctrs -> lifecycle -> rlang
#> tibble -> pillar -> vctrs -> rlang
#> tibble -> rlang
#> tibble -> vctrs -> lifecycle -> rlang
#> tibble -> vctrs -> rlang10 Dependencias: mentalidad y antecedentes
Toma una dependencia cuando su paquete usa la funcionalidad de otro paquete (u otra herramienta externa). En Sección 9.6, explicamos cómo declarar una dependencia en otro paquete incluyéndolo en DESCRIPTION, generalmente en Imports o Suggests. Pero eso todavía te deja muchas cuestiones en las que pensar:
¿Cuándo se debe tomar una dependencia? ¿Cuáles son los riesgos y las recompensas? En Sección 10.1 proporcionamos un marco para decidir si una dependencia vale la pena. Este capítulo también incluye secciones específicas para decidir entre
ImportsySuggests(Sección 10.1.4) y entreImportsyDepends(Sección 10.4.1).¿Cómo deberías utilizar diferentes tipos de dependencias en diferentes contextos? Es decir, paquetes importados versus paquetes sugeridos, usados dentro de sus funciones versus pruebas versus documentación. Tenemos que posponer esto para el próximo capítulo (Capítulo 11), porque la justificación de esas recomendaciones se basa en algunos antecedentes técnicos adicionales que desarrollamos aquí.
Un concepto clave para comprender cómo deben funcionar juntos los paquetes es el de un espacio de nombres (Sección 10.2). Aunque puede resultar un poco confuso, el sistema de espacio de nombres de R es vital para el ecosistema de paquetes. Es lo que garantiza que otros paquetes no interfieran con su código, que su código no interfiera con otros paquetes y que su paquete funcione independientemente del entorno en el que se ejecute. Mostraremos cómo funciona el sistema de espacio de nombres junto con la ruta de búsqueda del usuario (Sección 10.3) y en conjunto con ella.
Este capítulo contiene material que podrías omitir (o pasar por alto) al hacer tu primer paquete, cuando probablemente estés contento con hacer un paquete que funcione. Pero querrás revisar el material de este capítulo a medida que tus paquetes se vuelvan más ambiciosos y sofisticados.
10.1 ¿Cuándo deberías tomar una dependencia?
Esta sección está adaptada de “It Depende” publicación de blog y discusión escrito por Jim Hester.
Las dependencias de software son un arma de doble filo. Por un lado, le permiten aprovechar el trabajo de otros, dándole a su software nuevas capacidades y haciendo que su comportamiento e interfaz sean más consistentes con otros paquetes. Al utilizar una solución preexistente, evita volver a implementar la funcionalidad, lo que elimina muchas oportunidades de introducir errores. Por otro lado, es probable que sus dependencias cambien con el tiempo, lo que podría requerir que realice cambios en su paquete, lo que podría aumentar su carga de mantenimiento. Sus dependencias también pueden aumentar el tiempo y el espacio en disco necesarios cuando los usuarios instalan su paquete. Estas desventajas han llevado a algunos a sugerir una mentalidad de “dependencia cero”. Creemos que este es un mal consejo para la mayoría de los proyectos y es probable que conduzca a una menor funcionalidad, un mayor mantenimiento y nuevos errores.
10.1.1 Las dependencias no son iguales
Un problema de simplemente minimizar el número absoluto de dependencias es que trata todas las dependencias como equivalentes, como si todas tuvieran los mismos costos y beneficios (o incluso costos infinitos y ningún beneficio). Sin embargo, en realidad, esto está lejos de la verdad. Hay muchos ejes en los que pueden diferir las dependencias, pero algunos de los más importantes incluyen:
El tipo de dependencia. Algunas dependencias vienen incluidas con el propio R (por ejemplo, base, utilidades, estadísticas) o son uno de los paquetes “recomendados” (por ejemplo, Matrix, supervivencia). Depender de estos paquetes tiene un costo muy bajo, ya que se instalan (casi) universalmente en los sistemas de todos los usuarios y, en su mayoría, cambian solo con las nuevas versiones de R. Por el contrario, existe un costo más alto para una dependencia que proviene, por ejemplo, de un repositorio que no es CRAN, lo que requiere que los usuarios configuren repositorios adicionales antes de la instalación.
El número de dependencias ascendentes, es decir, dependencias recursivas. Por ejemplo, el paquete rlang se administra intencionalmente como un paquete de bajo nivel y no tiene dependencias ascendentes aparte del propio R. En el otro extremo, hay paquetes en CRAN con ~250 dependencias recursivas.
Dependencias ya cumplidas. Si su paquete depende de dplyr, entonces depender de tibble no cambia la huella de dependencia, ya que dplyr ya depende de tibble. Además, algunos de los paquetes más populares (por ejemplo, ggplot2) ya estarán instalados en la mayoría de las máquinas de los usuarios. Por lo tanto, es poco probable que agregar una dependencia de ggplot2 genere costos de instalación adicionales en la mayoría de los casos.
-
La carga de instalar el paquete. Varios factores hacen que un paquete sea más costoso de instalar, en términos de tiempo, espacio y molestias humanas:
Tiempo de compilación: los paquetes que contienen C/C++ pueden tardar muy diferentes en instalarse dependiendo de la complejidad del código. Por ejemplo, el paquete glue tarda ~5 segundos en compilarse en las máquinas de compilación de CRAN, mientras que el paquete readr tarda ~100 segundos para instalar en las mismas máquinas.
Tamaño del paquete binario: los usuarios que instalan paquetes binarios deben descargarlos, por lo que el tamaño del binario es relevante, especialmente para aquellos con conexiones a Internet lentas. Esto también varía mucho entre paquetes. Los paquetes más pequeños en CRAN tienen un tamaño de alrededor de 1 Kb, mientras que el paquete h2o tiene un tamaño de 170 Mb, ¡y hay archivos binarios de Bioconductor que pesan más de 4 Gb!
Requisitos del sistema: algunos paquetes requieren dependencias adicionales del sistema para poder usarse. Por ejemplo, el paquete rjags requiere una instalación correspondiente de la biblioteca JAGS. Otro ejemplo es rJava que requiere un SDK de Java y también tiene pasos adicionales necesarios para configurar R para la instalación adecuada de Java, lo que ha causado problemas de instalación para mucha gente.
Capacidad de mantenimiento. Es razonable tener mayor confianza en un paquete que está bien establecido y que es mantenido por desarrolladores o equipos con una larga trayectoria y que mantienen muchos otros paquetes. Esto aumenta la probabilidad de que el paquete permanezca en CRAN sin interrupciones y que el mantenedor tenga un enfoque intencional para el ciclo de vida del software (Capítulo 21).
Funcionalidad. Algunos paquetes implementan una funcionalidad crítica que se utiliza en muchos paquetes. En el tidyverse, ampliamente definido, los paquetes rlang, tidyselect, vctrs y tibble son ejemplos de esto. Al utilizar estos paquetes para tareas complicadas como evaluación no estándar o manipulación de vectores y marcos de datos, los autores de paquetes pueden evitar volver a implementar la funcionalidad básica. Es fácil pensar “¿qué tan difícil puede ser escribir mi propia X?” cuando estás enfocado en el Camino Feliz1. Pero una gran parte del valor que aportan paquetes como vctrs o tibble es permitir que otra persona se preocupe por los casos extremos y el manejo de errores2 . También es valioso tener un comportamiento compartido con otros paquetes, por ejemplo, las reglas de tidyverse para reparación de nombres o reciclaje.
Es de esperar que los detalles anteriores dejen en claro que las dependencias de los paquetes no son iguales.
10.1.2 Prefiere un enfoque holístico, equilibrado y cuantitativo
En lugar de esforzarse por lograr un número mínimo de dependencias, recomendamos un enfoque más holístico, equilibrado y cuantitativo.
Un enfoque holístico analiza el proyecto como un todo y pregunta “¿quién es el público principal?”. Si la audiencia son otros autores de paquetes, entonces un paquete más sencillo con menos dependencias puede ser más apropiado. Si, en cambio, el usuario objetivo es un científico de datos o un estadístico, probablemente ya tendrá instaladas muchas dependencias populares y se beneficiaría de un paquete con más funciones.
Un enfoque equilibrado comprende que agregar (o eliminar) dependencias conlleva compensaciones. Agregar una dependencia le brinda funciones adicionales, correcciones de errores y pruebas en el mundo real, a costa de un mayor tiempo de instalación, espacio en disco y mantenimiento, si la dependencia tiene cambios importantes. En algunos casos, tiene sentido aumentar las dependencias de un paquete, incluso si ya existe una implementación. Por ejemplo, base R tiene varias implementaciones diferentes de evaluación no estándar con diferentes semánticas entre sus funciones. Lo mismo solía ocurrir con los paquetes tidyverse, pero ahora todos dependen de las implementaciones en tidyselect y rlang paquetes. Los usuarios se benefician de la coherencia mejorada de esta característica y los desarrolladores de paquetes individuales pueden dejar que los mantenedores de tidyselect y rlang se preocupen por los detalles técnicos.
Por el contrario, eliminar una dependencia reduce el tiempo de instalación, el espacio en disco y evita posibles cambios importantes. Sin embargo, significa que su paquete tendrá menos funciones o que deberá volver a implementarlas usted mismo. Esto, a su vez, requiere tiempo de desarrollo e introduce nuevos errores. Una ventaja de utilizar una solución existente es que obtendrá el beneficio de todos los errores que ya se han descubierto y solucionado. Especialmente si muchos otros paquetes dependen de la dependencia, este es un regalo que sigue dando.
De manera similar a la optimización del rendimiento, si le preocupa la carga de las dependencias, tiene sentido abordar esas preocupaciones de una manera específica y cuantitativa. El paquete experimental itdepends fue creado para la charla y publicación de blog en los que se basa esta sección. Sigue siendo una fuente útil de ideas concretas (y código) para analizar qué tan pesada es una dependencia. El paquete pak también tiene varias funciones que son útiles para el análisis de dependencias:
10.1.3 Pensamientos de dependencia específicos del tidyverse
Los paquetes mantenidos por el equipo de tidyverse desempeñan diferentes funciones en el ecosistema y se gestionan en consecuencia. Por ejemplo, los paquetes tidyverse y devtools son esencialmente metapaquetes que existen para comodidad del usuario final. En consecuencia, se recomienda que otros paquetes no dependan de tidyverse3 o devtools (Sección 2.2), es decir, estos dos paquetes casi nunca deberían aparecer en Imports . En cambio, un mantenedor de paquetes debe identificar y depender del paquete específico que realmente implementa la funcionalidad deseada.
En la sección anterior hablamos de diferentes formas de medir el peso de una dependencia. Tanto tidyverse como devtools pueden considerarse pesados debido al gran número de dependencias recursivas:
n_hard_deps <- function(pkg) {
deps <- tools::package_dependencies(pkg, recursive = TRUE)
sapply(deps, length)
}
n_hard_deps(c("tidyverse", "devtools"))
#> Warning: unable to access index for repository http://cran.us.r-project.org /src/contrib:
#> cannot open URL 'http://cran.us.r-project.org /src/contrib/PACKAGES'
#> tidyverse devtools
#> 0 0Por el contrario, varios paquetes están concebidos específicamente como paquetes de bajo nivel que implementan características que deberían funcionar y sentirse igual en todo el ecosistema. Al momento de escribir este artículo, esto incluye:
- rlang, para soportar la evaluación ordenada y arrojar errores
- cli y pegamento, para crear una interfaz de usuario rica (que incluye errores)
- withr, para gestionar el estado de manera responsable
- ciclo de vida, para gestionar el ciclo de vida de funciones y argumentos
Básicamente, se consideran dependencias gratuitas y se pueden agregar a DESCRIPTION mediante usethis::use_tidy_dependencies() (que también hace algunas cosas más). No debería sorprender que estos paquetes tengan una huella de dependencia muy pequeña.
tools::package_dependencies(c("rlang", "cli", "glue", "withr", "lifecycle"))
#> Warning: unable to access index for repository http://cran.us.r-project.org /src/contrib:
#> cannot open URL 'http://cran.us.r-project.org /src/contrib/PACKAGES'
#> $rlang
#> NULL
#>
#> $cli
#> NULL
#>
#> $glue
#> NULL
#>
#> $withr
#> NULL
#>
#> $lifecycle
#> NULL
Envío a CRAN
Bajo ciertas configuraciones, incluidas aquellas utilizadas para envíos CRAN entrantes, R CMD check emite una nota si hay 20 o más paquetes “no predeterminados” en Imports:
N checking package dependencies (1.5s)
Imports includes 29 non-default packages.
Importing from so many packages makes the package vulnerable to any of
them becoming unavailable. Move as many as possible to Suggests and
use conditionally.Nuestro mejor consejo es esforzarse por cumplirlo, ya que debería ser bastante raro necesitar tantas dependencias y es mejor eliminar cualquier nota que pueda. Por supuesto, hay excepciones a cada regla, y quizás su paquete sea una de ellas. En ese caso, es posible que deba defender su caso. Es cierto que muchos paquetes CRAN violan este umbral.
10.1.4 Ya sea para importar o sugerir
El paquete withr es un buen caso de estudio para decidir si incluir una dependencia en Imports o Suggests. withr es muy útil para escribir pruebas que se limpian por sí solas. Dicho uso es compatible con incluir withr en Suggests, ya que los usuarios habituales no necesitan ejecutar las pruebas. Pero a veces un paquete también puede usar withr en sus propias funciones, tal vez para ofrecer sus propias funciones with_*() y local_*(). En ese caso, withr debería aparecer en Imports.
Las “Importaciones” y las “Sugerencias” difieren en la intensidad y naturaleza de la dependencia:
-
Imports: los paquetes enumerados aquí deben estar presentes para que su paquete funcione. Cada vez que se instala su paquete, esos paquetes también se instalarán, si aún no están presentes.devtools::load_all()también verifica que todos los paquetes enImportsestén instalados.Vale la pena señalar que agregar un paquete a
Importsgarantiza que se instalará y eso es todo. No tiene nada que ver con importar funciones de ese paquete. Consulte Sección 11.4 para obtener más información sobre cómo usar un paquete enImports. -
Suggests: su paquete puede usar estos paquetes, pero no los requiere. Puede utilizar paquetes sugeridos, por ejemplo, conjuntos de datos, para ejecutar pruebas, crear viñetas o tal vez solo haya una función que necesite el paquete.Los paquetes enumerados en
Suggestsno se instalan automáticamente junto con su paquete. Esto significa que no puede asumir que sus usuarios han instalado todos los paquetes sugeridos, pero sí puede asumir que los desarrolladores sí. Consulte Sección 11.5 para saber cómo comprobar si un paquete sugerido está instalado.
Las “sugerencias” no son muy relevantes para paquetes donde la base de usuarios es aproximadamente igual al equipo de desarrollo o para paquetes que se utilizan en un contexto muy predecible. En ese caso, es razonable usar “Importaciones” para todo. El uso de “Sugerencias” es principalmente una cortesía para los usuarios externos o para adaptarse a instalaciones muy sencillas. Puede liberar a los usuarios de la descarga de paquetes que rara vez necesitan (especialmente aquellos que son difíciles de instalar) y les permite comenzar con su paquete lo más rápido posible.
10.2 Espacio de nombres
Hasta ahora, hemos explicado la mecánica de declarar una dependencia en DESCRIPTION (Sección 9.6) y cómo analizar los costos y beneficios de las dependencias (Sección 10.1). Antes de explicar cómo usar sus dependencias en varias partes de su paquete en Capítulo 11, necesitamos establecer los conceptos de un espacio de nombres de paquete y la ruta de búsqueda.
10.2.1 Motivación
Como sugiere el nombre, los espacios de nombres proporcionan “espacios” para “nombres”. Proporcionan un contexto para buscar el valor de un objeto asociado con un nombre.
Sin saberlo, probablemente ya hayas utilizado espacios de nombres. ¿Ha utilizado alguna vez el operador ::? Elimina la ambigüedad de funciones con el mismo nombre. Por ejemplo, los paquetes lubridate y here proporcionan una función here(). Si adjunta lubridate primero, entonces aquí, here() se referirá a la versión de here, porque gana el último paquete adjunto. Pero si adjunta los paquetes en el orden opuesto, here() se referirá a la versión lubridate.
Esto puede resultar confuso. En su lugar, puede calificar la llamada a la función con un espacio de nombres específico: lubridate::here() y here::here(). Entonces el orden en el que se adjuntan los paquetes no importará4.
lubridate::here() # always gets lubridate::here()
here::here() # always gets here::here()Como verá en Sección 11.4, el estilo de llamada package::function() también es nuestra recomendación predeterminada sobre cómo usar sus dependencias en el código debajo de R/, porque elimina toda ambigüedad. .
Pero, en el contexto del código del paquete, el uso de :: no es realmente nuestra principal línea de defensa contra la confusión vista en el ejemplo anterior. En los paquetes, confiamos en los espacios de nombres para garantizar que todos los paquetes funcionen de la misma manera independientemente de qué paquetes adjunte el usuario.
Considere la función sd() del paquete de estadísticas que forma parte de la base R:
sd
#> function (x, na.rm = FALSE)
#> sqrt(var(if (is.vector(x) || is.factor(x)) x else as.double(x),
#> na.rm = na.rm))
#> <bytecode: 0x55682cc1b338>
#> <environment: namespace:stats>Se define en términos de otra función, var(), también del paquete de estadísticas. Entonces, ¿qué sucede si anulamos var() con nuestra propia definición? ¿Se rompe sd()?
¡Sorprendentemente no es así! Esto se debe a que cuando sd() busca un objeto llamado var(), busca primero en el espacio de nombres del paquete de estadísticas, por lo que encuentra stats::var(), no el var() que creamos en el entorno mundial. Sería un caos si funciones como sd() pudieran ser interrumpidas por un usuario redefiniendo var() o adjuntando un paquete que anule var(). El sistema de espacio de nombres del paquete es lo que nos salva de este destino.
10.2.2 El archivo NAMESPACE
El archivo NAMESPACE juega un papel clave en la definición del espacio de nombres de su paquete. Aquí hay líneas seleccionadas del archivo NAMESPACE en el paquete testthat:
# Generado por roxygen2: no editar a mano
S3method(compare,character)
S3method(print,testthat_results)
export(compare)
export(expect_equal)
import(rlang)
importFrom(brio,readLines)
useDynLib(testthat, .registration = TRUE)La primera línea anuncia que este archivo no está escrito a mano, sino que lo genera el paquete roxygen2. Volveremos a este tema pronto, después de discutir las líneas restantes.
Puede ver que el archivo NAMESPACE se parece un poco al código R (pero no lo es). Cada línea contiene una directiva: S3method(), export(), importFrom(), etc. Cada directiva describe un objeto R e indica si se exporta desde este paquete para ser utilizado por otros o si se importa desde otro paquete para ser utilizado internamente.
Estas directivas son las más importantes en nuestro enfoque de desarrollo, en orden de frecuencia:
-
export(): exporta una función (incluidos los genéricos S3 y S4). -
S3method(): exporta un método S3. -
importFrom(): importa el objeto seleccionado desde otro espacio de nombres (incluidos los genéricos de S4). -
import(): importa todos los objetos del espacio de nombres de otro paquete. -
useDynLib(): registra rutinas desde una DLL (esto es específico de paquetes con código compilado).
Hay otras directivas que no cubriremos aquí porque se desaconsejan explícitamente o simplemente rara vez aparecen en nuestro trabajo de desarrollo.
-
exportPattern(): exporta todas las funciones que coinciden con un patrón. Creemos que es más seguro utilizar siempre exportaciones explícitas y evitamos el uso de esta directiva. -
exportClasses(),exportMethods(),importClassesFrom(),importMethodsFrom(): exporta e importa clases y métodos S4. Sólo trabajamos en el sistema S4 cuando es necesario por compatibilidad con otro paquete, es decir, generalmente no implementamos métodos o clases que poseemos con S4. Por lo tanto, la cobertura de S4 en este libro es mínima.
En el flujo de trabajo de devtools, el archivo NAMESPACE no está escrito a mano. En su lugar, preferimos generar NAMESPACE con el paquete roxygen2, usando etiquetas específicas ubicadas en un comentario de roxygen encima de la definición de cada función en los archivos R/*.R (Sección 11.3). Tendremos mucho más que decir sobre los comentarios de roxygen y el paquete roxygen2 cuando analicemos la documentación del paquete en Capítulo 16. Por ahora, solo exponemos las razones por las que preferimos este método de generar el archivo NAMESPACE:
Las etiquetas de espacio de nombres están integradas en el código fuente, por lo que cuando lees el código es más fácil ver qué se exporta e importa y por qué.
Roxygen2 abstrae algunos de los detalles de
NAMESPACE. Solo necesita aprender una etiqueta,@export, y roxygen2 determinará qué directiva específica usar, en función de si el objeto asociado es una función normal, un método S3, un método S4 o una clase S4.Roxygen2 mantiene ordenado
NAMESPACE. No importa cuántas veces aparezca@importFrom foo baren tus comentarios de roxygen, solo obtendrás unimportFrom(foo, bar)en tuNAMESPACE. Roxygen2 también mantiene NAMESPACE organizado en un orden de principio, ordenándolo primero por tipo de directiva y luego alfabéticamente. Roxygen2 elimina la carga de escribir NAMESPACE y al mismo tiempo intenta mantener el archivo lo más legible posible. Esta organización también hace que las diferencias de Git sean mucho más informativas.
Tenga en cuenta que puede optar por utilizar roxygen2 para generar solo NAMESPACE, solo man/*.Rd (Capítulo 16), o ambos (como es nuestra práctica). Si no utiliza ninguna etiqueta relacionada con el espacio de nombres, roxygen2 no tocará NAMESPACE. Si no utiliza ninguna etiqueta relacionada con la documentación, roxygen2 no tocará man/.
10.3 Ruta de búsqueda
Para comprender por qué los espacios de nombres son importantes, necesita un conocimiento sólido de las rutas de búsqueda. Para llamar a una función, R primero tiene que encontrarla. Esta búsqueda se desarrolla de manera diferente para el código de usuario que para el código de paquete y eso se debe al sistema de espacio de nombres.
10.3.1 Búsqueda de funciones para el código de usuario
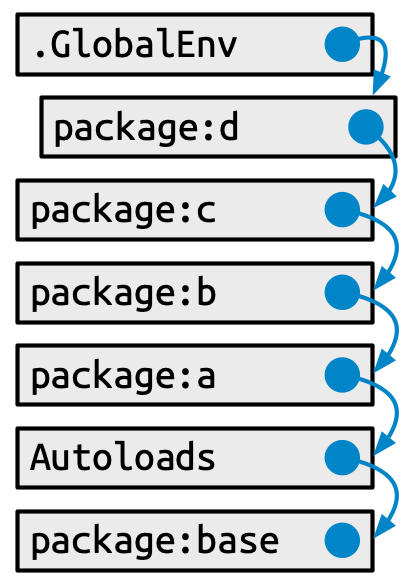
El primer lugar donde R busca un objeto es el entorno global. Si R no lo encuentra allí, busca en la ruta de búsqueda, la lista de todos los paquetes que ha adjuntado. Puede ver esta lista ejecutando search(). Por ejemplo, aquí está la ruta de búsqueda del código de este libro:
search()
#> [1] ".GlobalEnv" "package:stats" "package:graphics"
#> [4] "package:grDevices" "package:datasets" "renv:shims"
#> [7] "package:utils" "package:methods" "Autoloads"
#> [10] "package:base"Esto tiene una forma específica (ver Figura 10.1):
- El medio ambiente global.
- Los paquetes que se han adjuntado, por ejemplo, mediante
library(), desde el más reciente hasta el menos adjunto. -
Autocargas, un entorno especial que utiliza enlaces retrasados para ahorrar memoria cargando solo objetos de paquete (como grandes conjuntos de datos) cuando sea necesario. - El entorno base, por lo que nos referimos al entorno del paquete base.

Cada elemento en la ruta de búsqueda tiene el siguiente elemento como padre, es decir, se trata de una cadena de entornos que se buscan en orden. En el diagrama, esta relación se muestra como un pequeño círculo azul con una flecha que apunta al padre. El primer entorno (el entorno global) y los dos últimos (Autoloads y el entorno base) son especiales y mantienen su posición.
Pero la sección intermedia de paquetes adjuntos es más dinámica. Cuando se adjunta un nuevo paquete, se inserta inmediatamente después y se convierte en el padre del entorno global. Cuando adjuntas otro paquete con library(), cambia la ruta de búsqueda, como se muestra en Figura 10.2:
El problema principal sobre cómo funciona la ruta de búsqueda del usuario es el escenario que exploramos en Sección 10.2.1, donde dos paquetes (lubridate y aquí) ofrecen funciones competitivas con el mismo nombre (here()). Ahora debería quedar muy claro por qué la llamada de un usuario a here() puede producir un resultado diferente, dependiendo del orden en el que adjuntó los dos paquetes.
Este tipo de confusión sería aún más perjudicial si se aplicara al código del paquete, pero afortunadamente no es así. Ahora podemos explicar cómo el sistema de espacio de nombres elimina este problema.
10.3.2 Búsqueda de funciones dentro de un paquete
En Sección 10.2.1, demostramos que la definición de un usuario de una función llamada var() no rompe stats::sd(). De alguna manera, para nuestro inmenso alivio, stats::sd() encuentra stats::var() cuando debería. ¿Cómo funciona?
Esta sección es algo técnica y es absolutamente posible desarrollar un paquete con un espacio de nombres con buen comportamiento sin comprender completamente estos detalles. Considera esta lectura opcional que puedes consultar cuando y si estás interesado. Puedes aprender aún más en Advanced R, especialmente en el capítulo sobre entornos, del cual hemos adaptado parte de este material.
Cada función en un paquete está asociada con un par de entornos: el entorno del paquete, que es lo que aparece en la ruta de búsqueda del usuario, y el entorno espacio de nombres.
El entorno del paquete es la interfaz externa del paquete. Así es como un usuario normal de R encuentra una función en un paquete adjunto o con
::. Su padre está determinado por la ruta de búsqueda, es decir, el orden en el que se han adjuntado los paquetes. El entorno del paquete solo expone objetos exportados.El entorno del espacio de nombres es la interfaz interna del paquete. Incluye todos los objetos del paquete, tanto exportados como no exportados. Esto garantiza que cada función pueda encontrar todas las demás funciones en el paquete. Cada enlace en el entorno del paquete también existe en el entorno del espacio de nombres, pero no viceversa.
Figura 10.3 representa la función sd() como un rectángulo con un extremo redondeado. Las flechas de paquete:stats y namespace:stats muestran que sd() está vinculado en ambos. Pero la relación no es simétrica. El círculo negro con una flecha que apunta hacia namespace:stats indica dónde sd() buscará los objetos que necesita: en el entorno del espacio de nombres, no en el entorno del paquete.
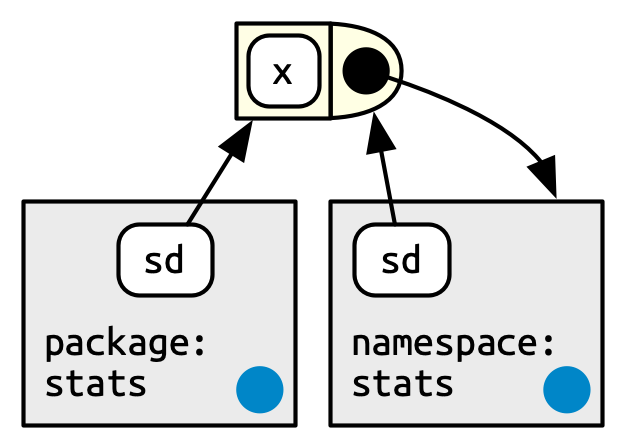
El entorno del paquete controla cómo los usuarios encuentran la función; el espacio de nombres controla cómo la función encuentra sus variables.
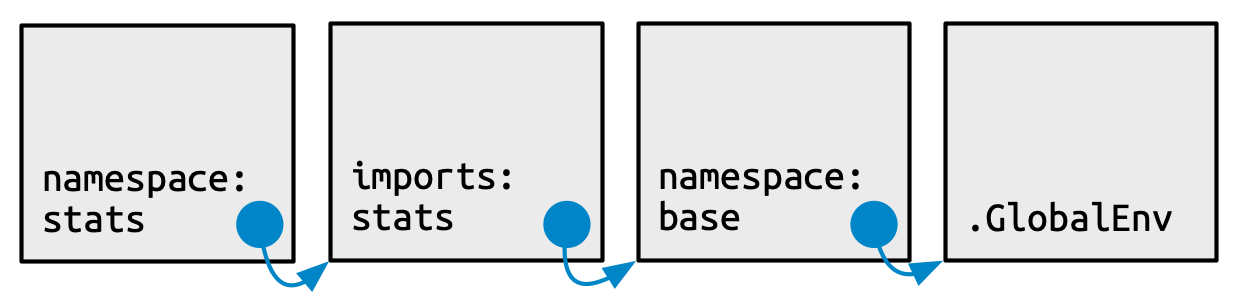
Cada entorno de espacio de nombres tiene el mismo conjunto de ancestros, como se muestra en Figura 10.4:
Cada espacio de nombres tiene un entorno importaciones que puede contener enlaces a funciones utilizadas por el paquete que están definidas en otro paquete. El entorno de importaciones lo controla el desarrollador del paquete con el archivo
NAMESPACE. Específicamente, directivas comoimportFrom()eimports()pueblan este entorno.Importar explícitamente cada función base sería tedioso, por lo que el padre del entorno de importaciones es el espacio de nombres base. El espacio de nombres base contiene los mismos enlaces que el entorno base, pero tiene un padre diferente.
El padre del espacio de nombres base es el entorno global. Esto significa que si un enlace no está definido en el entorno de importaciones, el paquete lo buscará de la forma habitual. Esto suele ser una mala idea (porque hace que el código dependa de otros paquetes cargados), por lo que
R CMD checkadvierte automáticamente sobre dicho código. Es necesario principalmente por razones históricas, particularmente debido a cómo funciona el envío del método S3.
Finalmente, podemos juntarlo todo en este último diagrama, Figura 10.5. Esto muestra la ruta de búsqueda del usuario, en la parte inferior, y la ruta de búsqueda de estadísticas internas, en la parte superior.
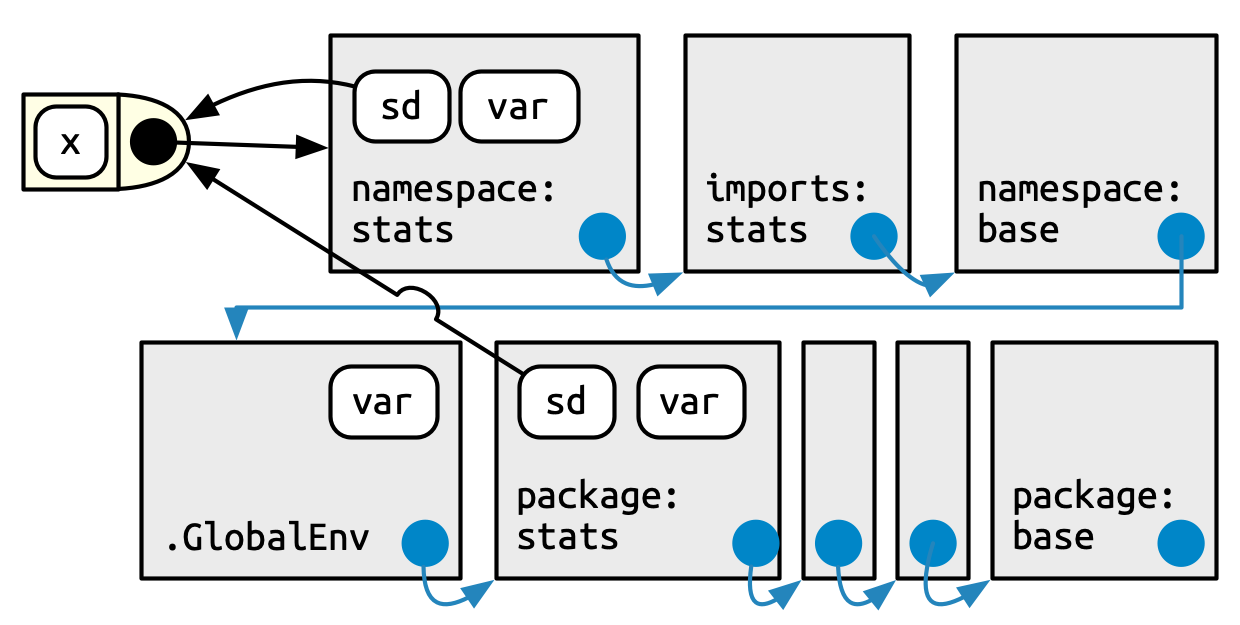
Un usuario (o algún paquete que esté usando) es libre de definir una función llamada var(). Pero cuando ese usuario llama a sd(), siempre llamará a stats::var() porque sd() busca en una secuencia de entornos determinados por el paquete de estadísticas, no por el usuario. Así es como el sistema de espacio de nombres garantiza que el código del paquete siempre funcione de la misma manera, independientemente de lo que se haya definido en el entorno global o de lo que se haya adjuntado.
10.4 Adjuntar versus cargar
Es común escuchar algo como “usamos library(algúnpaquete) para cargar algún paquete”. Pero técnicamente library() adjunta un paquete a la ruta de búsqueda. Este abuso casual de la terminología suele ser inofensivo e incluso puede resultar beneficioso en algunos entornos. Pero a veces es importante ser preciso y pedante y éste es uno de esos momentos. Los desarrolladores de paquetes necesitan saber la diferencia entre adjuntar y cargar un paquete y cuándo preocuparse por esta diferencia.
Si hay un paquete instalado,
Cargar cargará código, datos y cualquier archivo DLL; registrar los métodos S3 y S4; y ejecute la función
.onLoad(). Después de cargarlo, el paquete está disponible en la memoria, pero como no está en la ruta de búsqueda, no podrá acceder a sus componentes sin usar::. De manera confusa,::también cargará un paquete automáticamente si aún no está cargado.Adjuntar coloca el paquete en la ruta de búsqueda (Sección 10.3.1). No puede adjuntar un paquete sin cargarlo primero, por lo que
library()(orequire()) cargan y luego adjuntan el paquete. Esto también ejecuta la función.onAttach().
Hay cuatro funciones que hacen que un paquete esté disponible, que se muestran en Tabla 10.1. Se diferencian según si se cargan o adjuntan y qué sucede si no se encuentra el paquete (es decir, arroja un error o devuelve FALSE).
| Arroja un error | Devulve FALSE
|
|
|---|---|---|
| Cargar | loadNamespace("x") |
requireNamespace("x", quietly = TRUE) |
| Adjuntar | library(x) |
require(x, quietly = TRUE) |
De las cuatro, estas dos funciones son, con diferencia, las más útiles:
Utilice
library(x)en, por ejemplo, un script de análisis de datos o una viñeta. Generará un error si el paquete no está instalado y finalizará el script. Desea adjuntar el paquete para ahorrar escritura. Nunca uselibrary()en el código del paquete debajo deR/otests/.Utilice
requireNamespace("x", quietly = TRUE)dentro de un paquete si desea especificar un comportamiento diferente dependiendo de si un paquete sugerido está instalado o no. Tenga en cuenta que esto también carga el paquete. Damos ejemplos en Sección 11.5.1.
loadNamespace() es algo esotérico y en realidad solo es necesario para el código R interno.
require(pkg) casi nunca es una buena idea5 y, sospechamos, puede provenir de personas que proyectan ciertas esperanzas y sueños en el nombre de la función. Irónicamente, require(pkg) en realidad no requiere éxito al adjuntar el paquete y su función o script continuará incluso en caso de falla. Esto, a su vez, a menudo conduce a un error muy desconcertante mucho más tarde. Si desea “adjuntar o fallar”, use library(). Si desea verificar si el paquete está disponible y proceder en consecuencia, use requireNamespace("pkg", quietly = TRUE).
Un uso razonable de require() es en un ejemplo que usa un paquete que su paquete sugiere, que se analiza con más detalle en Sección 11.5.3.
Las funciones .onLoad() y .onAttach() mencionadas anteriormente son dos de varios ganchos que le permiten ejecutar código específico cuando su paquete está cargado o adjunto (o, incluso, desconectado o descargado). La mayoría de los paquetes no necesitan esto, pero estos ganchos son útiles en determinadas situaciones. Consulte Sección 6.5.4 para conocer algunos casos de uso de .onLoad() y .onAttach().
10.4.1 Ya sea para importar o depender
Ahora estamos en condiciones de establecer la diferencia entre Depends e Imports en el archivo DESCRIPTION. Incluir un paquete en “dependencia” o “importaciones” garantiza que se instale cuando sea necesario. La principal diferencia es que un paquete que usted enumere en Imports simplemente se cargará cuando lo use, mientras que un paquete que usted enumere en Dependsse adjuntará cuando su paquete esté adjunto.
A menos que exista una buena razón para lo contrario, siempre debe enumerar los paquetes en Imports, no en Depends. Esto se debe a que un buen paquete es autónomo y minimiza los cambios en el panorama global, incluida la ruta de búsqueda.6
Los usuarios de devtools en realidad están expuestos regularmente al hecho de que devtools “depende” de usethis:
Esta elección está motivada por la compatibilidad con versiones anteriores. Cuando devtools se dividió en varios paquetes más pequeños (Sección 2.2), muchas de las funciones orientadas al usuario pasaron a usaethis. Poner usethis en dependencias fue una elección pragmática para evitar que los usuarios realicen un seguimiento de qué función terminó y dónde.
Un ejemplo más clásico de dependencia es cómo el paquete censored depende de los paquetes parsnip y surival. parsnip proporciona una interfaz unificada para ajustar modelos y censored es un paquete de extensión para análisis de supervivencia. censored no es útil sin parsnip y survival, por lo que tiene sentido enumerarlos en Depends.
En programación, Happy Path es el escenario donde todas las entradas tienen sentido y son exactamente como las cosas “deberían ser”. El Camino Infeliz es todo lo demás (objetos de longitud o dimensión cero, objetos a los que les faltan datos, dimensiones o atributos, objetos que no existen, etc.).↩︎
Antes de escribir su propia versión de X, eche un vistazo al rastreador de errores y al conjunto de pruebas de otro paquete que implemente X. Esto puede resultar útil para apreciar lo que realmente está involucrado.↩︎
Hay una publicación de blog que advierte a las personas que no dependan del paquete tidyverse: https://www.tidyverse.org/blog/2018/06/tidyverse-not-for-packages/.↩︎
Nos centraremos en los paquetes de este libro, pero hay otras formas además de usar
::para abordar conflictos en el código del usuario final: el paquete en conflicto y la opción"conflicts.policy"introducido en base R v3.6.0.↩︎La publicación de blog clásica “
library()vsrequire()en R” de Yihui Xie es otro buen recurso sobre esto.↩︎Thomas Leeper creó varios paquetes de ejemplo para demostrar el comportamiento desconcertante que puede surgir cuando los paquetes usan
Dependsy compartió el trabajo en https://github.com/leeper/Depends. Esta demostración también subraya la importancia de usar::(oimportFrom()) al usar funciones externas en su paquete, como se recomienda en Capítulo 11.↩︎