library(available)
available("doofus")
#> Urban Dictionary can contain potentially offensive results,
#> should they be included? [Y]es / [N]o:
#> 1: 1
#> ── doofus ──────────────────────────────────────────────────────────────────
#> Name valid: ✔
#> Available on CRAN: ✔
#> Available on Bioconductor: ✔
#> Available on GitHub: ✔
#> Abbreviations: http://www.abbreviations.com/doofus
#> Wikipedia: https://en.wikipedia.org/wiki/doofus
#> Wiktionary: https://en.wiktionary.org/wiki/doofus
#> Sentiment:???4 Flujos de trabajo de desarrollo fundamentales
Habiendo echado un vistazo bajo el capó de los paquetes y bibliotecas de R en Capítulo 3, aquí proporcionamos los flujos de trabajo básicos para crear un paquete y moverlo a través de los diferentes estados que surgen durante el desarrollo.
4.1 Crear un paquete
4.1.1 Examinar el paisaje existente
Muchos paquetes nacen de la frustración de una persona por alguna tarea común que debería ser más fácil. ¿Cómo se debe decidir si algo es digno de ser empaquetado? No hay una respuesta definitiva, pero es útil apreciar al menos dos tipos de recompensa:
- Producto: tu vida será mejor cuando esta funcionalidad se implemente formalmente, en un paquete.
- Proceso: un mayor dominio de R te hará más eficaz en tu trabajo.
Si lo único que le importa es la existencia de un producto, entonces su objetivo principal es navegar por el espacio de los paquetes existentes. Silge, Nash y Graves organizaron una encuesta y sesiones sobre este tema en useR! 2017 y su artículo para el R Journal (Silge, Nash, y Graves 2018) proporciona un resumen completo de recursos.
Si está buscando formas de aumentar su dominio de R, aún debe informarse sobre el panorama. Pero hay muchas buenas razones para crear su propio paquete, incluso si existe un trabajo previo relevante. La forma en que los expertos llegaron a ese camino es construyendo cosas, a menudo cosas muy básicas, y usted merece la misma oportunidad de aprender haciendo retoques. Si sólo se le permite trabajar en cosas que nunca se han tocado, es probable que esté enfrentando problemas que son muy oscuros o muy difíciles.
También es válido evaluar la idoneidad de las herramientas existentes en función de la interfaz de usuario, los valores predeterminados y el comportamiento de los casos extremos. Técnicamente, un paquete puede hacer lo que necesita, pero quizás sea muy poco ergonómico para su caso de uso. En este caso, puede tener sentido que usted desarrolle su propia implementación o escriba funciones contenedoras que suavicen los bordes afilados.
Si su trabajo pertenece a un dominio bien definido, infórmese sobre los paquetes R existentes, incluso si ha decidido crear su propio paquete. ¿Siguen patrones de diseño específicos? ¿Existen estructuras de datos específicas que sean comunes como entrada y salida principal? Por ejemplo, existe una comunidad R muy activa en torno al análisis de datos espaciales (r-spatial.org) que se ha autoorganizado con éxito para promover una mayor coherencia entre paquetes con diferentes mantenedores. En el modelado, el paquete de hardhat proporciona una base para crear un paquete de modelado que funciona bien con el ecosistema tidymodels. Su paquete se utilizará más y necesitará menos documentación si encaja bien en el entorno.
4.1.2 Nombra tu paquete
“Sólo hay dos cosas difíciles en Ciencias de la Computación: invalidación de caché y nombrar cosas.”
— Phil Karlton
Antes de poder crear su paquete, debe darle un nombre. ¡Esta puede ser la parte más difícil de crear un paquete! (Sobre todo porque nadie puede automatizarlo por usted).
4.1.2.1 Requisitos formales
Hay tres requisitos formales.:
- El nombre sólo puede constar de letras, números y puntos, es decir, “.”.
- Debe comenzar con una letra.
- No puede terminar con un punto.
Desafortunadamente, esto significa que no puede usar guiones ni guiones bajos, es decir, - o _, en el nombre de su paquete. Recomendamos no utilizar puntos en los nombres de los paquetes, debido a asociaciones confusas con extensiones de archivos y métodos S3.
4.1.2.2 Cosas para considerar
Si planeas compartir tu paquete con otras personas, es importante encontrar un buen nombre. A continuación se ofrecen algunos consejos:
Elija un nombre único que sea fácil de buscar en Google. Esto facilita que los usuarios potenciales encuentren su paquete (y los recursos asociados) y que usted vea quién lo está usando.
-
No elija un nombre que ya esté en uso en CRAN o Bioconductor. Es posible que también desees considerar otros tipos de colisión de nombres.:
- ¿Hay algún paquete en desarrollo que esté madurando en, digamos, GitHub que ya tenga algo de historia y parezca estar encaminado hacia su lanzamiento?
- ¿Este nombre ya se utiliza para otra pieza de software o para una biblioteca o marco en, por ejemplo, el ecosistema Python o JavaScript?
Evite el uso de letras mayúsculas y minúsculas: hacerlo hace que el nombre del paquete sea difícil de escribir y aún más difícil de recordar. Por ejemplo, es difícil recordar si es Rgtk2, RGTK2 o RGtk2.
Dé preferencia a nombres que sean pronunciables, para que las personas se sientan cómodas hablando de su paquete y tengan una manera de escucharlo dentro de su cabeza.
-
Encuentre una palabra que evoque el problema y modifíquela para que sea única. Aquí hay unos ejemplos:
- lubridate hace el trabajo con fechas y horas más fácil.
- rvest “cosecha” (“harvests”, en inglés) el contenido de las páginas web.
- r2d3 proporciona utilidades para trabajar con visualizaciones D3.
- forcats es un anagrama de factores, que utilizamos para datos categóricos.
-
Utilice abreviaturas, como las siguientes:
- Rcpp = R + C++ (más más)
- brms = Bayesian Regression Models using Stan (Modelos de regresión bayesiana usando Stan)
-
Agregue una R adicional, por ejemplo:
- stringr proporciona herramientas de cadenas de caracteres (string en inglés).
- beepr reproduce sonidos de notificación.
- callr llama R, desde R.
-
No hagas que te demanden.
- Si está creando un paquete que se dirige a un servicio comercial, consulte las pautas de marca. Por ejemplo, rDrop no se llama rDropbox porque Dropbox prohíbe que cualquier aplicación utilice el nombre completo de la marca registrada..
Nick Tierney presenta una tipología divertida de nombres de paquetes en su publicación de blog Naming Things, que también incluye ejemplos más inspiradores. También tiene algo de experiencia cambiando el nombre de paquetes; la publicación Entonces, has decidido cambiar el nombre de tu paquete r es un buen recurso si no lo hace bien la primera vez.
4.1.2.3 Utilice el paquete available
Es imposible cumplir con todas las sugerencias anteriores simultáneamente, por lo que deberá hacer algunas concesiones. El paquete available tiene una función llamada available() que le ayuda a evaluar el nombre de un paquete potencial desde muchos ángulos:
available::available() hace lo siguiente:
- Comprobaciones de validez.
- Verifica la disponibilidad en CRAN, Bioconductor y más.
- Busca en varios sitios web para ayudarle a descubrir significados no deseados. En una sesión interactiva, las URL que ve arriba se abren en las pestañas del navegador.
- Intenta informar si el nombre tiene un sentimiento positivo o negativo..
pak::pkg_name_check() es una función alternativa con un propósito similar. Dado que el paquete pak se encuentra en desarrollo más activo que el available, puede surgir como la mejor opción en el futuro.
4.1.3 Creación de paquetes
Una vez que haya creado un nombre, hay dos formas de crear el paquete..
- Llamar
usethis::create_package(). - En RStudio, haz File > New Project > New Directory > R Package. Esto en última instancia llama
usethis::create_package(), así que realmente solo hay una manera.
Esto produce el paquete funcional más pequeño posible, con tres componentes:
Un directorio
R/, sobre el cual aprenderá en Capítulo 6.Un archivo básico
DESCRIPTION, sobre el cual aprenderá en Capítulo 9.Un archivo
NAMESPACEbásico, sobre el que aprenderá en Sección 10.2.2.
También puede incluir un archivo de proyecto de RStudio, pkgname.Rproj, que hace que su paquete sea fácil de usar con RStudio, como se describe a continuación. Los archivos básicos .Rbuildignore y .gitignore también quedan atrás.
Advertencia
No utilice package.skeleton() para crear un paquete. Debido a que esta función viene con R, es posible que tenga la tentación de usarla, pero crea un paquete que inmediatamente arroja errores con R CMD build. Anticipa un proceso de desarrollo diferente al que usamos aquí, por lo que reparar este estado inicial roto simplemente hace que el trabajo sea innecesario para las personas que usan devtools (y, especialmente, roxygen2). Use create_package().
4.1.4 ¿Dónde deberías crear el paquete, create_package()?
El argumento principal y único requerido para create_package() es la ruta, path donde vivirá su nuevo paquete:
create_package("ruta/al/paquete/nombrepqt")Recuerde que aquí es donde reside su paquete en su forma fuente (Sección 3.2), no en su forma instalada (Sección 3.5). Los paquetes instalados se encuentran en una biblioteca y analizamos las configuraciones convencionales para bibliotecas en Sección 3.7.
¿Dónde debería guardar los paquetes fuente? El principio fundamental es que esta ubicación debe ser distinta de donde se encuentran los paquetes instalados. En ausencia de consideraciones externas, un usuario típico debería designar un directorio dentro de su directorio de inicio para los paquetes R (fuente). Discutimos esto con colegas y la fuente de muchos paquetes de tidyverse se encuentra dentro de directorios como ~/rrr/, ~/documents/tidyverse/, ~/r/packages/ o ~/pkg/. Algunos de nosotros usamos un directorio para esto, otros dividen los paquetes fuente entre unos pocos directorios según su función de desarrollo (colaborador o no), organización de GitHub (tidyverse o r-lib), etapa de desarrollo (activa o no), etc.
Lo anterior probablemente refleja que somos principalmente constructores de herramientas. Un investigador académico podría organizar sus archivos en torno a publicaciones individuales, mientras que un científico de datos podría organizarlos en torno a productos e informes de datos. No existe ninguna razón técnica o tradicional particular para un enfoque específico. Siempre que mantenga una distinción clara entre los paquetes fuente e instalados, simplemente elija una estrategia que funcione dentro de su sistema general para la organización de archivos y úsela de manera consistente.
4.2 Proyectos de RStudio
devtools trabaja mano a mano con RStudio, que creemos que es el mejor entorno de desarrollo para la mayoría de los usuarios de R. Para ser claros, puedes usar devtools sin usar RStudio y puedes desarrollar paquetes en RStudio sin usar devtools. Pero existe una relación especial bidireccional que hace que sea muy gratificante utilizar devtools y RStudio juntos.
RStudio
Un Proyecto de RStudio, con una “P” mayúscula, es un directorio normal en su computadora que incluye alguna infraestructura de RStudio (en su mayoría oculta) para facilitar su trabajo en uno o más proyectos, con una “p” minúscula. “. Un proyecto puede ser un paquete R, un análisis de datos, una aplicación Shiny, un libro, un blog, etc.
4.2.1 Beneficios de los proyectos de RStudio
Desde Sección 3.2, ya sabes que un paquete fuente se encuentra en un directorio de tu computadora. Recomendamos encarecidamente que cada paquete fuente sea también un proyecto RStudio. Éstos son algunas de las ventajas:
Los proyectos son muy “lanzables”. Es fácil iniciar una nueva instancia de RStudio en un proyecto, con el explorador de archivos y el directorio de trabajo configurados exactamente de la manera que necesita, listos para trabajar..
-
Cada Proyecto está aislado; El código ejecutado en un proyecto no afecta a ningún otro proyecto.
- Puede tener varios proyectos de RStudio abiertos a la vez y el código ejecutado en el proyecto A no tiene ningún efecto en la sesión de R ni en el espacio de trabajo del proyecto B.
Obtendrá útiles herramientas de navegación de código como
F2para saltar a la definición de una función yCtrl +.para buscar funciones o archivos por nombre.-
Obtiene útiles atajos de teclado y una interfaz en la que se puede hacer clic para tareas comunes de desarrollo de paquetes, como generar documentación, ejecutar pruebas o verificar el paquete completo.
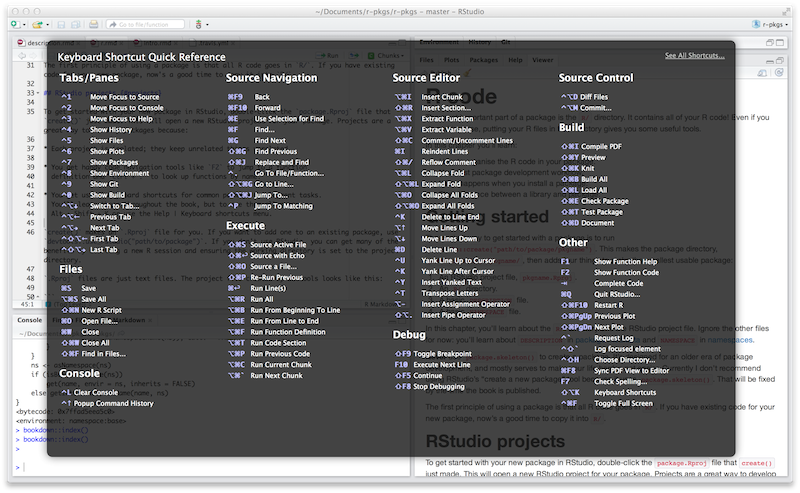
Figura 4.1: Referencia rápida de métodos abreviados de teclado en RStudio.
RStudio
Para ver los atajos de teclado más útiles, presione Alt + Shift + K o use Help > Keyboard Shortcuts Help. Deberías ver algo como Figura 4.1.
RStudio también proporciona la Paleta de comandos que brinda acceso rápido y con capacidad de búsqueda a todos los comandos del IDE – especialmente útil cuando no recuerdas un atajo de teclado en particular. Se invoca mediante Ctrl + Shift + P (Windows & Linux) o Cmd + Shift + P (macOS).
RStudio
Siga @rstudiotips en Twitter para obtener una dosis regular de consejos y trucos de RStudio.
4.2.2 Cómo conseguir un proyecto RStudio
Si sigue nuestra recomendación de crear nuevos paquetes con create_package(), cada paquete nuevo también será un proyecto RStudio, si está trabajando desde RStudio.
Si necesita designar el directorio de un paquete fuente preexistente como un proyecto RStudio, elija una de estas opciones:
- En RStudio, haz File > New Project > Existing Directory.
- Llame a
create_package()con la ruta al paquete fuente R preexistente. - Llame a
usethis::use_rstudio(), con el proyecto usethis activo establecido en un paquete R existente. En la práctica, esto probablemente signifique que solo necesita asegurarse de que su directorio de trabajo esté dentro del directorio del paquete preexistente.
4.2.3 ¿Qué caracteriza a un proyecto RStudio?
Un directorio que sea un proyecto RStudio contendrá un archivo .Rproj. Normalmente, si el directorio se llama “foo”, el archivo del proyecto es foo.Rproj. Y si ese directorio también es un paquete R, entonces el nombre del paquete suele ser también “foo”. El camino de menor resistencia es hacer que todos estos nombres coincidan y NO anidar su paquete dentro de un subdirectorio dentro del Proyecto. Si opta por un flujo de trabajo diferente, sepa que puede sentir que está luchando con las herramientas.
Un archivo .Rproj es solo un archivo de texto. Aquí hay un archivo de proyecto representativo que puede ver en un proyecto iniciado mediante usethis:
Version: 1.0
RestoreWorkspace: No
SaveWorkspace: No
AlwaysSaveHistory: Default
EnableCodeIndexing: Yes
Encoding: UTF-8
AutoAppendNewline: Yes
StripTrailingWhitespace: Yes
LineEndingConversion: Posix
BuildType: Package
PackageUseDevtools: Yes
PackageInstallArgs: --no-multiarch --with-keep.source
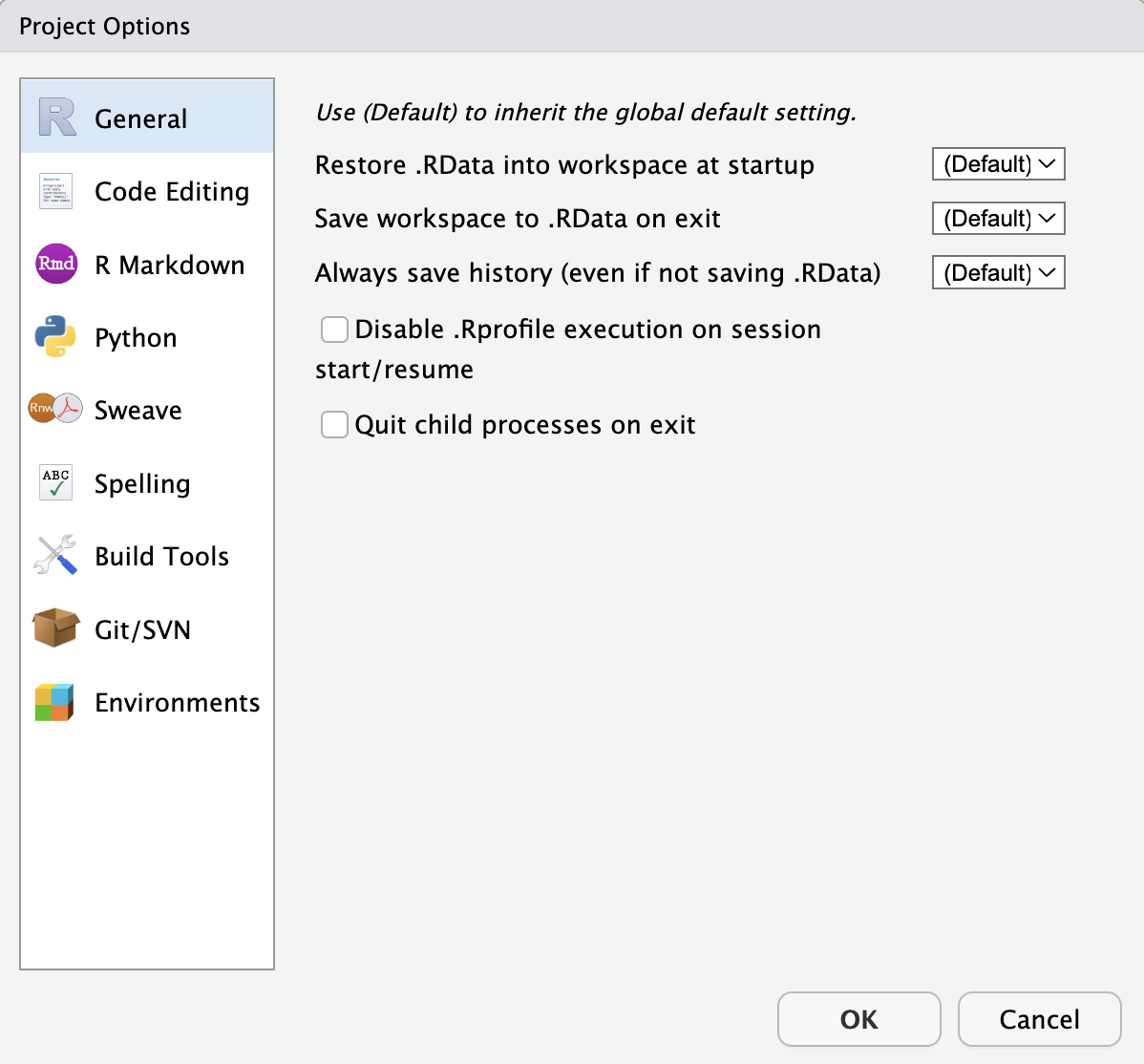
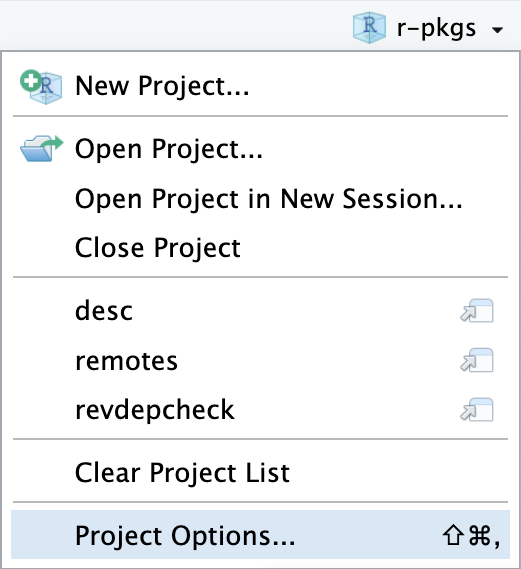
PackageRoxygenize: rd,collate,namespaceNo es necesario modificar este archivo manualmente. En su lugar, utilice la interfaz disponible a través de Tools > Project Options (Figura 4.2) o Project Options en el menú Proyectos en la esquina superior derecha (Figura 4.3).
4.2.4 Cómo lanzar un proyecto RStudio
Haga doble clic en el archivo foo.Rproj en el Finder de macOS o en el Explorador de Windows para iniciar el proyecto foo en RStudio.
También puede iniciar proyectos desde RStudio a través de File > Open Project (in New Session) o el menú Proyectos en la esquina superior derecha.
Si utiliza una aplicación de productividad o de inicio, probablemente pueda configurarla para que haga algo agradable con los archivos .Rproj. Ambos usamos a Alfred para esto. 1, que es solo macOS, pero existen herramientas similares para Windows. De hecho, esta es una muy buena razón para utilizar una aplicación de productividad en primer lugar.
Es muy normal – ¡y productivo! – tener varios proyectos abiertos a la vez.
4.2.5 Proyecto RStudio versus uso activo de este proyecto
Notarás que la mayoría de las funciones de usethis no toman una ruta: operan en los archivos en el “proyecto de usethis activo”. El uso de este paquete supone que el 95% de las veces todos estos coinciden:
- El proyecto RStudio actual, si se utiliza RStudio.
- El uso activo de este proyecto.
- Directorio de trabajo actual para el proceso R.
Si las cosas parecen raras, llame a proj_sitrep() para obtener un “informe de situación”. Éste identificará situaciones peculiares y propondrá formas de volver a un estado más feliz.
# Por lo general, estos deberían ser los mismos (o no estar configurados).
proj_sitrep()
#> * directorio de trabajo: '/Users/jenny/rrr/readxl'
#> * active_usethis_proj: '/Users/jenny/rrr/readxl'
#> * active_rstudio_proj: '/Users/jenny/rrr/readxl'4.3 Directorio de trabajo y disciplina de ruta de archivo
A medida que desarrolle su paquete, ejecutará código R. Esta será una combinación de llamadas de flujo de trabajo (por ejemplo, document() o test()) y llamadas ad hoc que le ayudarán a escribir sus funciones, ejemplos y pruebas. Recomendamos encarecidamente que mantenga el nivel superior de su paquete fuente como directorio de trabajo de su proceso R. Esto generalmente sucederá de forma predeterminada, por lo que esta es realmente una recomendación para evitar flujos de trabajo de desarrollo que requieran que juegue con el directorio de trabajo.
Si es totalmente nuevo en el desarrollo de paquetes, no tiene muchas bases para apoyar o resistirse a esta propuesta. Pero aquellos con cierta experiencia pueden encontrar esta recomendación algo molesta. Quizás se pregunte cómo se supone que debe expresar las rutas cuando trabaja en subdirectorios, como tests/. A medida que sea relevante, le mostraremos cómo explotar los asistentes de creación de rutas, como testthat::test_path(), que determinan las rutas en el momento de la ejecución.
La idea básica es que al dejar el directorio de trabajo solo, se le recomienda escribir rutas que transmitan la intención explícitamente (“leer foo.csv del directorio de prueba”) en lugar de implícitamente (“leer foo.csv del directorio de trabajo actual , que creo será el directorio de prueba”). Una señal segura de dependencia de rutas implícitas es el jugueteo incesante con su directorio de trabajo, porque está utilizando setwd() para cumplir manualmente las suposiciones que están implícitas en sus rutas.
El uso de rutas explícitas puede eliminar toda una clase de dolores de cabeza en las rutas y también hace que el desarrollo diario sea más placentero. Hay dos razones por las que es difícil acertar con los caminos implícitos:
- Recuerde las diferentes formas que puede adoptar un paquete durante el ciclo de desarrollo (Capítulo 3). Estos estados difieren entre sí en términos de qué archivos y carpetas existen y sus posiciones relativas dentro de la jerarquía. Es complicado escribir rutas relativas que funcionen en todos los estados del paquete.
- Con el tiempo, usted y potencialmente CRAN procesarán su paquete con herramientas integradas como
R CMD build,R CMD checkyR CMD INSTALL. Es difícil realizar un seguimiento de cuál será el directorio de trabajo en cada etapa de estos procesos.
Los asistentes de ruta como testthat::test_path(), fs::path_package() y el paquete rprojroot son extremadamente útiles para crear rutas resistentes que resistan en toda la gama de situaciones que surgen durante el desarrollo y el uso. Otra forma de eliminar rutas frágiles es ser riguroso en el uso de métodos adecuados para almacenar datos dentro de su paquete (Capítulo 7) y apuntar al directorio temporal de la sesión cuando sea apropiado, como para artefactos de prueba efímeros. (Capítulo 13).
4.4 Prueba de manejo con load_all()
La función load_all() es posiblemente la parte más importante del flujo de trabajo de devtools.
# con devtools adjuntado y
# el directorio de trabajo configurado en el nivel superior de su paquete fuente ...
load_all()
# ... ahora experimenta con las funciones de tu paquete.load_all() es el paso clave en este ciclo de desarrollo de paquetes de “hacer espuma, enjuagar y repetir”:
- Modificar la definición de una función.
load_all()- Pruebe el cambio ejecutando un pequeño ejemplo o algunas pruebas.
Cuando eres nuevo en el desarrollo de paquetes o en devtools, es fácil pasar por alto la importancia de load_all() y caer en algunos hábitos incómodos en un flujo de trabajo de análisis de datos.
4.4.1 Beneficios de load_all()
Cuando comienza a utilizar un entorno de desarrollo, como RStudio o VS Code, la mayor ventaja es la capacidad de enviar líneas de código desde un script .R para su ejecución en la consola R. La fluidez de esto es lo que hace que sea tolerable seguir la mejor práctica de considerar el código fuente como real 2 (en lugar de objetos en el espacio de trabajo) y guardar archivos .R (en lugar de guardar y volver a cargar .Rdata).
load_all() tiene el mismo significado para el desarrollo de paquetes e, irónicamente, requiere que NO pruebe el código del paquete de la misma manera que el código de script. load_all() simula el proceso completo para ver el efecto de un cambio en el código fuente, lo cual es bastante complicado 3 que no querrás hacerlo muy a menudo. Figura 4.4 refuerza que la función library() solo puede cargar un paquete que ha sido instalado, mientras que load_all() ofrece una simulación de alta fidelidad de esto, basada en la fuente del paquete actual.

Los principales beneficios de load_all() incluyen:
- Puede iterar rápidamente, lo que fomenta la exploración y el progreso incremental.
- Esta aceleración iterativa es especialmente notable en paquetes con código compilado.
- Puedes desarrollar de forma interactiva bajo un régimen de espacio de nombres que imita con precisión cómo son las cosas cuando alguien usa tu paquete instalado, con las siguientes ventajas adicionales:
- Puede llamar a sus propias funciones internas directamente, sin usar
:::y sin caer en la tentación de definir temporalmente sus funciones en el espacio de trabajo global. - También puede llamar funciones de otros paquetes que haya importado a su
NAMESPACE, sin caer en la tentación de adjuntar estas dependencias a través delibrary().
- Puede llamar a sus propias funciones internas directamente, sin usar
load_all() elimina la fricción del flujo de trabajo de desarrollo y elimina la tentación de utilizar soluciones alternativas que a menudo conducen a errores en torno a la gestión de espacios de nombres y dependencias.
4.4.2 Otras formas de llamar load_all()
Cuando se trabaja en un proyecto que es un paquete, RStudio ofrece varias formas de llamar load_all():
- Atajo de teclado: Cmd+Shift+L (macOS), Ctrl+Shift+L (Windows, Linux)
- Paneles de construcción menú More …
- Build > Load All
devtools::load_all() es una envoltura delgada alrededor de pkgload::load_all() que agrega un poco de facilidad de uso. Es poco probable que uses load_all() programáticamente o dentro de otro paquete, pero si lo haces, probablemente deberías usar pkgload::load_all() directamente.
4.5 check() y R CMD check
Base R proporciona varias herramientas de línea de comandos y “R CMD check” es el método oficial para comprobar que un paquete R es válido. Es esencial pasar la verificación R CMD check si planea enviar su paquete a CRAN, pero recomendamos encarecidamente cumplir con este estándar incluso si no tiene intención de publicar su paquete en CRAN. R CMD check detecta muchos problemas comunes que de otro modo descubrirías por las malas.
Nuestra forma recomendada de ejecutar R CMD check es en la consola R a través de devtools:
devtools::check()Recomendamos esto porque le permite ejecutar R CMD check desde R, lo que reduce drásticamente la fricción y aumenta la probabilidad de que check() sea temprano y con frecuencia. Este énfasis en la fluidez y la retroalimentación rápida es exactamente la misma motivación que se da para load_all(). En el caso de check(), realmente está ejecutando R CMD check por usted. No se trata sólo de una simulación de alta fidelidad, como es el caso de load_all().
RStudio
RStudio expone check() en el menú Build, en el panel Build a través de Check y en los atajos de teclado Ctrl + Shift + E (Windows & Linux) o Cmd + Shift + E (macOS).
Un error de novato que vemos a menudo en los desarrolladores de nuevos paquetes es trabajar demasiado en su paquete antes de ejecutar “R CMD check”. Luego, cuando finalmente lo ejecutan, es típico descubrir muchos problemas, lo que puede resultar muy desmoralizador. Es contrario a la intuición, pero la clave para minimizar este dolor es ejecutar R CMD check con más frecuencia: cuanto antes encuentre un problema, más fácil será solucionarlo.4. Modelamos este comportamiento muy intencionalmente en Capítulo 1.
El límite superior de este enfoque es ejecutar R CMD check cada vez que realiza un cambio. No ejecutamos check() manualmente con tanta frecuencia, pero cuando estamos trabajando activamente en un paquete, es típico ejecutar check() varias veces al día. No juegue con su paquete durante días, semanas o meses, esperando algún hito especial para finalmente ejecutar R CMD check. Si usas GitHub (Sección 20.1), Le mostraremos cómo configurar las cosas para que R CMD check se ejecute automáticamente cada vez que realice un push (Sección 20.2.1).
4.5.1 Flujo de trabajo
Esto es lo que sucede dentro devtools::check():
Garantiza que la documentación esté actualizada ejecutando
devtools::document().Empaqueta el paquete antes de revisarlo (Sección 3.3). Esta es la mejor práctica para verificar paquetes porque garantiza que la verificación comience desde cero: porque un paquete de paquetes no contiene ninguno de los archivos temporales que pueden acumularse en su paquete fuente, por ejemplo. artefactos como los archivos
.soy.oque acompañan al código compilado, puede evitar las advertencias falsas que generarán dichos archivos.Establece la variable de entorno
NOT_CRANen"true". Esto le permite omitir selectivamente pruebas en CRAN. Consulte?testthat::skip_on_crany Sección 15.4.1 para obtener más detalles.
El flujo de trabajo para comprobar un paquete es sencillo, pero tedioso:
Ejecute
devtools::check(), o presione Ctrl/Cmd + Shift + E.Arregle el primer problema.
Repita hasta que no haya más problemas.
R CMD check devuelve tres tipos de mensajes:
ERROR(errores): Problemas graves que debes solucionar independientemente de si envías o no a CRAN.WARNING(advertencias): Problemas probables que debes solucionar si planeas enviar a CRAN (y es una buena idea investigar incluso si no lo estás haciendo).NOTE(notas): Problemas leves o, en algunos casos, simplemente una observación. Si realiza un envío a CRAN, debe esforzarse por eliminar todas las NOTAS, incluso si son falsos positivos. Si no tiene NOTAS, no se requiere intervención humana y el proceso de envío del paquete será más sencillo. Si no es posible eliminar una “NOTA”, deberá describir por qué está bien en los comentarios de envío, como se describe en Sección 22.7. Si no realiza el envío a CRAN, lea atentamente cada NOTA. Si es fácil eliminar las NOTAS, vale la pena, para que puedas seguir esforzándote por conseguir un resultado totalmente limpio. Pero si eliminar una NOTA tendrá un impacto negativo neto en su paquete, es razonable simplemente tolerarlo. Asegúrese de que eso no le lleve a ignorar otras cuestiones que realmente deberían abordarse.
R CMD check consta de docenas de controles individuales y sería abrumador enumerarlos aquí. Consulte nuestra guía solo en línea para verificar `R CMD check para más detalles.
4.5.2 Antecedentes sobre R CMD check
A medida que acumula experiencia en el desarrollo de paquetes, es posible que desee acceder R CMD check directamente en algún momento. Recuerde que R CMD check es algo que debe ejecutar en la terminal, no en la consola R. Puedes ver su documentación así:
R CMD check --helpR CMD check se puede ejecutar en un directorio que contiene un paquete R en formato fuente (Sección 3.2) o, preferiblemente, en un empaquetado (Sección 3.3):
R CMD build somepackage
R CMD check somepackage_0.0.0.9000.tar.gz Para obtener más información, consulte la sección Comprobación de paquetes de Escribir extensiones R.
Específicamente, configuramos Alfred para favorecer los archivos
.Rprojen sus resultados de búsqueda cuando propone aplicaciones o archivos para abrir. Para registrar el tipo de archivo.Rprojcon Alfred, vaya a Preferences > Features > Default Results > Advanced. Arrastre cualquier archivo.Rproja este espacio y luego ciérrelo.↩︎Citando la filosofía de uso favorecida por Emacs Speaks Statistics (ESS).↩︎
El método de línea de comando es salir de R, ir al shell, hacer
R CMD build fooen el directorio principal del paquete, luegoR CMD INSTALL foo_x.y.x.tar.gz, reiniciar R y llamarlibrary(foo).↩︎Una excelente publicación de blog que aboga por “si duele, hazlo más a menudo” es FrequencyReducesDifficulty de Martin Fowler.↩︎