library(rlang)7 Entornos
7.1 Introduction
El entorno es la estructura de datos que impulsa el alcance. Este capítulo profundiza en los entornos, describe su estructura en profundidad y los usa para mejorar su comprensión de las cuatro reglas de scoping descritas en la Sección 6.4. Comprender los entornos no es necesario para el uso diario de R. Pero es importante comprenderlos porque impulsan muchas funciones importantes de R, como el scoping léxico, los espacios de nombres y las clases R6, e interactúan con la evaluación para brindarle herramientas poderosas para crear dominios. lenguajes específicos, como dplyr y ggplot2.
Prueba
Si puede responder correctamente las siguientes preguntas, ya conoce los temas más importantes de este capítulo. Puede encontrar las respuestas al final del capítulo en la Sección 7.7.
Enumere al menos tres formas en que un entorno difiere de una lista.
¿Cuál es el padre del medio ambiente global? ¿Cuál es el único entorno que no tiene un padre?
¿Qué es el entorno envolvente de una función? ¿Por qué es importante?
¿Cómo determina el entorno desde el que se llamó a una función?
¿En qué se diferencian
<-y<<-?
Estructura
La Sección 7.2 le presenta las propiedades básicas de un entorno y le muestra cómo crear el suyo propio.
La Sección 7.3 proporciona una plantilla de funciones para computar con entornos, ilustrando la idea con una función útil.
La Sección 7.4 describe entornos utilizados para fines especiales: para paquetes, dentro de funciones, para espacios de nombres y para la ejecución de funciones.
La Sección 7.5 explica el último entorno importante: el entorno de la persona que llama. Esto requiere que aprenda sobre la pila de llamadas, que describe cómo se llamó a una función. Habrás visto la pila de llamadas si alguna vez llamaste a
traceback()para ayudar en la depuración.La Sección 7.6 analiza brevemente tres lugares donde los entornos son estructuras de datos útiles para resolver otros problemas.
Requisitos previos
Este capítulo utilizará las funciones rlang para trabajar con entornos, ya que nos permite centrarnos en la esencia de los entornos, en lugar de los detalles secundarios.
Las funciones env_ en rlang están diseñadas para trabajar con la canalización: todas toman un entorno como primer argumento, y muchas también devuelven un entorno. No usaré la canalización en este capítulo con el fin de mantener el código lo más simple posible, pero debería considerarlo para su propio código.
7.2 Conceptos básicos de entornos
En general, un entorno es similar a una lista con nombre, con cuatro excepciones importantes:
Cada nombre debe ser único.
Los nombres de un entorno no están ordenados.
Un entorno tiene un padre.
Los entornos no se copian cuando se modifican.
Exploremos estas ideas con código e imágenes.
7.2.1 Lo esencial
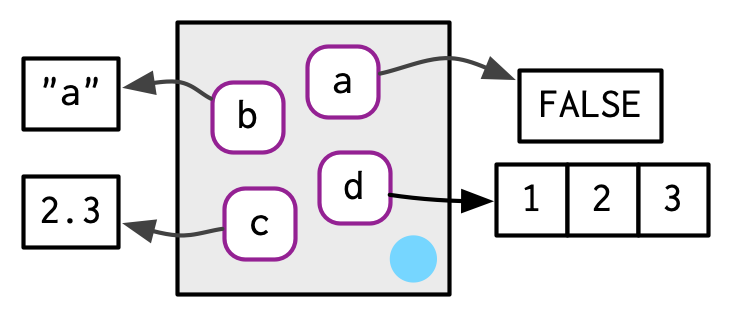
Para crear un entorno, utilice rlang::env(). Funciona como list(), tomando un conjunto de pares nombre-valor:
e1 <- env(
a = FALSE,
b = "a",
c = 2.3,
d = 1:3,
)Utilice new.env() para crear un nuevo entorno. Ignora los parámetros hash y size; no son necesarios. No puede crear y definir valores simultáneamente; use $<-, como se muestra a continuación.
El trabajo de un entorno es asociar, o vincular, un conjunto de nombres a un conjunto de valores. Puede pensar en un entorno como una bolsa de nombres, sin orden implícito (es decir, no tiene sentido preguntar cuál es el primer elemento en un entorno). Por esa razón, dibujaremos el entorno así:
Como se discutió en la Sección 2.5.2, los entornos tienen una semántica de referencia: a diferencia de la mayoría de los objetos R, cuando los modifica, los modifica en su lugar y no crea una copia. Una implicación importante es que los entornos pueden contenerse a sí mismos.
e1$d <- e1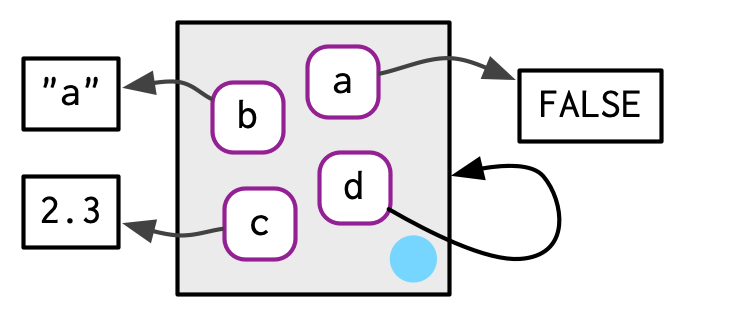
Imprimir un entorno solo muestra su dirección de memoria, lo que no es muy útil:
e1
#> <environment: 0x5556590024f8>En su lugar, usaremos env_print() que nos brinda un poco más de información:
env_print(e1)
#> <environment: 0x5556590024f8>
#> Parent: <environment: global>
#> Bindings:
#> • a: <lgl>
#> • b: <chr>
#> • c: <dbl>
#> • d: <env>Puede usar env_names() para obtener un vector de caracteres que proporcione los enlaces actuales
env_names(e1)
#> [1] "a" "b" "c" "d"En R 3.2.0 y versiones posteriores, use names() para enumerar los enlaces en un entorno. Si su código necesita funcionar con R 3.1.0 o anterior, use ls(), pero tenga en cuenta que deberá configurar all.names = TRUE para mostrar todos los enlaces.
7.2.2 Entornos importantes
Hablaremos en detalle sobre entornos especiales en Sección 7.4, pero por ahora necesitamos mencionar dos. El entorno actual, o current_env() es el entorno en el que el código se está ejecutando actualmente. Cuando estás experimentando de forma interactiva, ese suele ser el entorno global, o global_env(). El entorno global a veces se llama su “área de trabajo”, ya que es donde se lleva a cabo todo el cálculo interactivo (es decir, fuera de una función).
Para comparar entornos, debe usar identical() y no ==. Esto se debe a que == es un operador vectorizado y los entornos no son vectores.
identical(global_env(), current_env())
#> [1] TRUE
global_env() == current_env()
#> Error in global_env() == current_env(): comparison (==) is possible only for atomic and list typesAccede al entorno global con globalenv() y al entorno actual con environment(). El entorno global se imprime como R_GlobalEnv y .GlobalEnv.
7.2.3 Padres
Cada entorno tiene un padre, otro entorno. En los diagramas, el padre se muestra como un pequeño círculo azul pálido y una flecha que apunta a otro entorno. El padre es lo que se usa para implementar el scoping léxico: si un nombre no se encuentra en un entorno, entonces R buscará en su padre (y así sucesivamente). Puede configurar el entorno principal proporcionando un argumento sin nombre a env(). Si no lo proporciona, el valor predeterminado es el entorno actual. En el siguiente código, e2a es el padre de e2b.
e2a <- env(d = 4, e = 5)
e2b <- env(e2a, a = 1, b = 2, c = 3)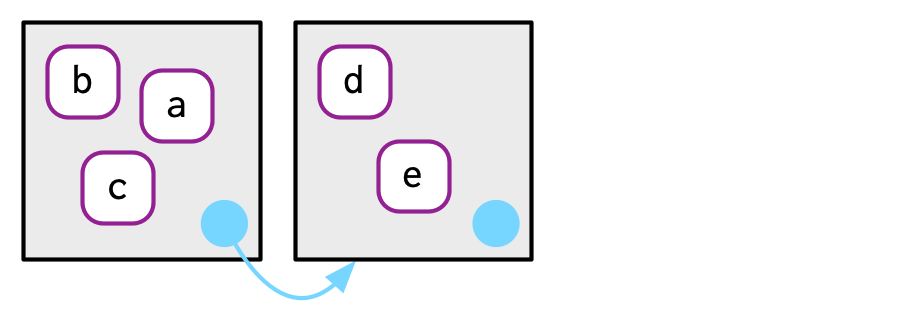
Para ahorrar espacio, normalmente no dibujaré a todos los antepasados; solo recuerda que cada vez que veas un círculo azul pálido, hay un entorno principal en alguna parte.
Puedes encontrar el padre de un entorno con env_parent():
env_parent(e2b)
#> <environment: 0x55565a46b730>
env_parent(e2a)
#> <environment: R_GlobalEnv>Solo un entorno no tiene un padre: el entorno vacío. Dibujo el entorno vacío con un entorno principal vacío y, cuando el espacio lo permita, lo etiquetaré con R_EmptyEnv, el nombre que usa R.
e2c <- env(empty_env(), d = 4, e = 5)
e2d <- env(e2c, a = 1, b = 2, c = 3)![]()
Los ancestros de cada ambiente eventualmente terminan con el ambiente vacío. Puedes ver todos los ancestros con env_parents():
env_parents(e2b)
#> [[1]] <env: 0x55565a46b730>
#> [[2]] $ <env: global>
env_parents(e2d)
#> [[1]] <env: 0x55565565df98>
#> [[2]] $ <env: empty>Por defecto, env_parents() se detiene cuando llega al entorno global. Esto es útil porque los ancestros del entorno global incluyen todos los paquetes adjuntos, que puede ver si anula el comportamiento predeterminado como se muestra a continuación. Volveremos a estos entornos en la Sección 7.4.1.
env_parents(e2b, last = empty_env())
#> [[1]] <env: 0x55565a46b730>
#> [[2]] $ <env: global>
#> [[3]] $ <env: package:rlang>
#> [[4]] $ <env: package:stats>
#> [[5]] $ <env: package:graphics>
#> [[6]] $ <env: package:grDevices>
#> [[7]] $ <env: package:datasets>
#> [[8]] $ <env: renv:shims>
#> [[9]] $ <env: package:utils>
#> [[10]] $ <env: package:methods>
#> [[11]] $ <env: Autoloads>
#> [[12]] $ <env: package:base>
#> [[13]] $ <env: empty>Use parent.env() para encontrar el padre de un entorno. Ninguna función base devuelve todos los ancestros.
7.2.4 Asignación superior, <<-
Los ancestros de un entorno tienen una relación importante con <<-. La asignación regular, <-, siempre crea una variable en el entorno actual. La súper asignación, <<-, nunca crea una variable en el entorno actual, sino que modifica una variable existente que se encuentra en un entorno principal.
x <- 0
f <- function() {
x <<- 1
}
f()
x
#> [1] 1Si <<- no encuentra una variable existente, creará una en el entorno global. Esto generalmente no es deseable, porque las variables globales introducen dependencias no obvias entre funciones. <<- se usa más a menudo junto con una fábrica de funciones, como se describe en la Sección 10.2.4.
7.2.5 Conseguir y configurar
Puede obtener y establecer elementos de un entorno con $ y [[ de la misma manera que una lista:
e3 <- env(x = 1, y = 2)
e3$x
#> [1] 1
e3$z <- 3
e3[["z"]]
#> [1] 3Pero no puedes usar [[ con índices numéricos, y no puedes usar [:
e3[[1]]
#> Error in e3[[1]]: wrong arguments for subsetting an environment
e3[c("x", "y")]
#> Error in e3[c("x", "y")]: object of type 'environment' is not subsettable$ y [[ devolverán NULL si el enlace no existe. Usa env_get() si quieres un error:
e3$xyz
#> NULL
env_get(e3, "xyz")
#> Error in `env_get()`:
#> ! Can't find `xyz` in environment.Si desea usar un valor predeterminado si el enlace no existe, puede usar el argumento default.
env_get(e3, "xyz", default = NA)
#> [1] NAHay otras dos formas de agregar enlaces a un entorno:
env_poke()1 toma un nombre (como cadena) y un valor:env_poke(e3, "a", 100) e3$a #> [1] 100env_bind()le permite vincular múltiples valores:env_bind(e3, a = 10, b = 20) env_names(e3) #> [1] "x" "y" "z" "a" "b"
Puede determinar si un entorno tiene un enlace con env_has():
env_has(e3, "a")
#> a
#> TRUEA diferencia de las listas, establecer un elemento en NULL no lo elimina, porque a veces desea un nombre que se refiera a NULL. En su lugar, usa env_unbind():
e3$a <- NULL
env_has(e3, "a")
#> a
#> TRUE
env_unbind(e3, "a")
env_has(e3, "a")
#> a
#> FALSEDesvincular un nombre no elimina el objeto. Ese es el trabajo del recolector de basura, que elimina automáticamente los objetos sin nombres vinculados a ellos. Este proceso se describe con más detalle en la Sección 2.6.
Consulte get(), assign(), exists() y rm(). Estos están diseñados de forma interactiva para su uso con el entorno actual, por lo que trabajar con otros entornos es un poco complicado. También tenga cuidado con el argumento inherits: por defecto es TRUE, lo que significa que los equivalentes base inspeccionarán el entorno suministrado y todos sus ancestros.
7.2.6 Enlaces avanzados
Hay dos variantes más exóticas de env_bind():
env_bind_lazy()crea enlaces retrasados, que se evalúan la primera vez que se accede a ellos. Detrás de escena, los enlaces retrasados crean promesas, por lo que se comportan de la misma manera que los argumentos de función.env_bind_lazy(current_env(), b = {Sys.sleep(1); 1}) system.time(print(b)) #> [1] 1 #> user system elapsed #> 0 0 1 system.time(print(b)) #> [1] 1 #> user system elapsed #> 0 0 0El uso principal de los enlaces retrasados es
autoload(), que permite que los paquetes de R proporcionen conjuntos de datos que se comportan como si estuvieran cargados en la memoria, aunque solo se cargan desde el disco cuando es necesario.env_bind_active()crea enlaces activos que se vuelven a calcular cada vez que se accede a ellos:env_bind_active(current_env(), z1 = function(val) runif(1)) z1 #> [1] 0.0808 z1 #> [1] 0.834Los enlaces activos se utilizan para implementar los campos activos de R6, sobre los que aprenderá en la Sección 14.3.2.
Consulte ?delayedAssign() y ?makeActiveBinding().
7.2.7 Ejercicios
Enumera tres formas en las que un entorno difiere de una lista.
Cree un entorno como el que se ilustra en esta imagen.
Cree un par de ambientes como se ilustra en esta imagen.
Explique por qué
e[[1]]ye[c("a", "b")]no tienen sentido cuandoees un entorno.Cree una versión de
env_poke()que solo vinculará nombres nuevos, nunca volverá a vincular nombres antiguos. Algunos lenguajes de programación solo hacen esto y se conocen como [lenguajes de asignación única] (http://en.wikipedia.org/wiki/Assignment_(computer_science)#Single_assignment).¿Qué hace esta función? ¿En qué se diferencia de
<<-y por qué podría preferirlo?rebind <- function(name, value, env = caller_env()) { if (identical(env, empty_env())) { stop("Can't find `", name, "`", call. = FALSE) } else if (env_has(env, name)) { env_poke(env, name, value) } else { rebind(name, value, env_parent(env)) } } rebind("a", 10) #> Error: Can't find `a` a <- 5 rebind("a", 10) a #> [1] 10
7.3 Recursing sobre entornos
Si desea operar en todos los ancestros de un entorno, a menudo es conveniente escribir una función recursiva. Esta sección le muestra cómo, aplicando su nuevo conocimiento de entornos para escribir una función que, dado un nombre, encuentra el entorno where() está definido ese nombre, utilizando las reglas de alcance habituales de R.
La definición de where() es sencilla. Tiene dos argumentos: el nombre a buscar (como una cadena) y el entorno en el que iniciar la búsqueda. (Aprenderemos por qué caller_env() es un buen valor predeterminado en la Sección 7.5.)
where <- function(name, env = caller_env()) {
if (identical(env, empty_env())) {
# caso base
stop("Can't find ", name, call. = FALSE)
} else if (env_has(env, name)) {
# caso de exitoso
env
} else {
# caso recursivo
where(name, env_parent(env))
}
}Hay tres casos:
El caso base: hemos llegado al entorno vacío y no hemos encontrado el enlace. No podemos ir más lejos, por lo que lanzamos un error.
El caso exitoso: el nombre existe en este entorno, por lo que devolvemos el entorno.
El caso recursivo: el nombre no se encontró en este entorno, así que pruebe con el padre.
Estos tres casos se ilustran con estos tres ejemplos:
where("yyy")
#> Error: Can't find yyy
x <- 5
where("x")
#> <environment: R_GlobalEnv>
where("mean")
#> <environment: base>Podría ayudar ver una imagen. Imagine que tiene dos entornos, como en el siguiente código y diagrama:
e4a <- env(empty_env(), a = 1, b = 2)
e4b <- env(e4a, x = 10, a = 11)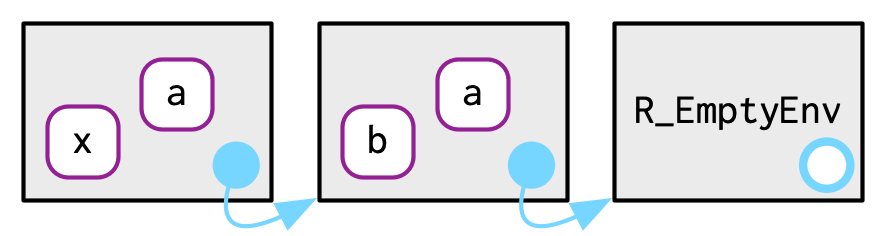
where("a", e4b)encontraráaene4b.where("b", e4b)no encuentrabene4b, así que busca en su padre,e4a, y lo encuentra ahí.where("c", e4b)busca ene4b, entoncese4a, luego llega al entorno vacío y arroja un error.
Es natural trabajar con entornos recursivamente, por lo que where() proporciona una plantilla útil. Eliminar los detalles de where() muestra la estructura más claramente:
f <- function(..., env = caller_env()) {
if (identical(env, empty_env())) {
# caso base
} else if (success) {
# caso exitoso
} else {
# caso recursivo
f(..., env = env_parent(env))
}
}7.3.1 Ejercicios
Modifique
where()para devolver todos los entornos que contienen un enlace paraname. Piensa detenidamente qué tipo de objeto necesitará devolver la función.Escribe una función llamada
fget()que encuentre solo objetos de función. Debe tener dos argumentos,nameyenv, y debe obedecer las reglas regulares de alcance de las funciones: si hay un objeto con un nombre coincidente que no es una función, busque en el padre. Para un desafío adicional, agregue también un argumentoinheritsque controle si la función recurre a los padres o solo busca en un entorno.
7.4 Entornos especiales
La mayoría de los entornos no los crea usted (por ejemplo, con env()), sino que los crea R. En esta sección, aprenderá sobre los entornos más importantes, comenzando con los entornos de paquete. Luego, aprenderá sobre el entorno de la función vinculado a la función cuando se crea y el entorno de ejecución (generalmente) efímero que se crea cada vez que se llama a la función. Finalmente, verá cómo los entornos de funciones y paquetes interactúan para admitir espacios de nombres, lo que garantiza que un paquete siempre se comporte de la misma manera, independientemente de qué otros paquetes haya cargado el usuario.
7.4.1 Entornos de paquetes y la ruta de búsqueda
Cada paquete adjunto por library() o require() se convierte en uno de los padres del entorno global. El padre inmediato del entorno global es el último paquete que adjuntó 2, el padre de ese paquete es el penúltimo paquete que adjuntó, …
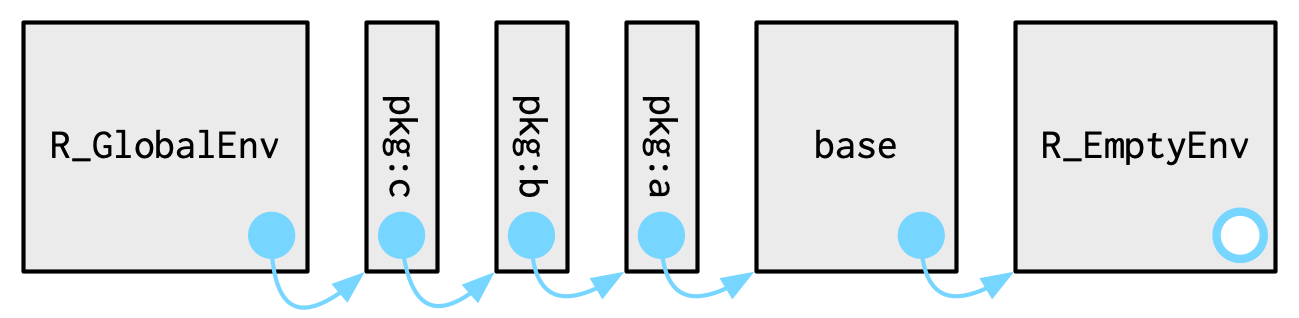
Si sigue a todos los padres hacia atrás, verá el orden en que se adjuntó cada paquete. Esto se conoce como ruta de búsqueda porque todos los objetos en estos entornos se pueden encontrar desde el espacio de trabajo interactivo de nivel superior. Puede ver los nombres de estos entornos con base::search(), o los propios entornos con rlang::search_envs():
search()
#> [1] ".GlobalEnv" "package:rlang" "package:stats"
#> [4] "package:graphics" "package:grDevices" "package:datasets"
#> [7] "renv:shims" "package:utils" "package:methods"
#> [10] "Autoloads" "package:base"
search_envs()
#> [[1]] $ <env: global>
#> [[2]] $ <env: package:rlang>
#> [[3]] $ <env: package:stats>
#> [[4]] $ <env: package:graphics>
#> [[5]] $ <env: package:grDevices>
#> [[6]] $ <env: package:datasets>
#> [[7]] $ <env: renv:shims>
#> [[8]] $ <env: package:utils>
#> [[9]] $ <env: package:methods>
#> [[10]] $ <env: Autoloads>
#> [[11]] $ <env: package:base>Los dos últimos entornos en la ruta de búsqueda son siempre los mismos:
El entorno
Autoloadsutiliza enlaces retrasados para ahorrar memoria al cargar solo objetos del paquete (como grandes conjuntos de datos) cuando es necesario.El entorno base,
package: baseo, a veces, simplementebase, es el entorno del paquete base. Es especial porque debe poder iniciar la carga de todos los demás paquetes. Puedes acceder a él directamente conbase_env().
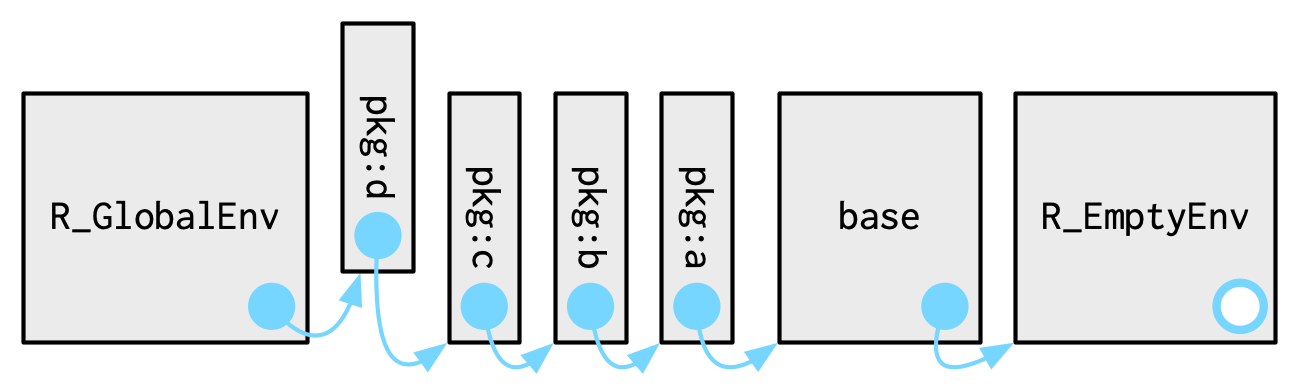
Tenga en cuenta que cuando adjunta otro paquete con library(), el entorno principal del entorno global cambia:
7.4.2 El entorno funcional
Una función vincula el entorno actual cuando se crea. Esto se denomina entorno de función y se utiliza para el scoping léxico. En todos los lenguajes informáticos, las funciones que capturan (o encierran) sus entornos se denominan cierres, razón por la cual este término a menudo se usa indistintamente con función en la documentación de R.
Puede obtener el entorno de la función con fn_env():
y <- 1
f <- function(x) x + y
fn_env(f)
#> <environment: R_GlobalEnv>Utilice environment(f) para acceder al entorno de la función f.
En los diagramas, dibujaré una función como un rectángulo con un extremo redondeado que une un entorno.
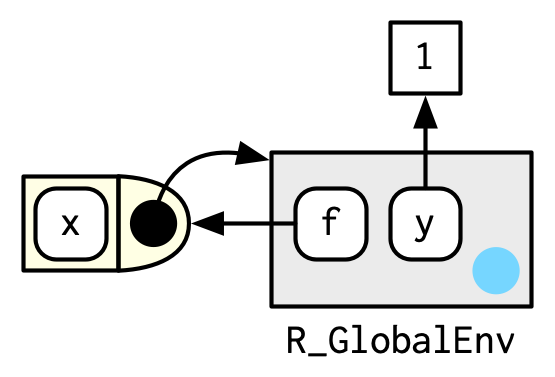
En este caso, f() vincula el entorno que vincula el nombre f a la función. Pero ese no es siempre el caso: en el siguiente ejemplo, g está enlazado en un nuevo entorno e, pero g() enlaza el entorno global. La distinción entre atar y ser atado por es sutil pero importante; la diferencia es cómo encontramos g versus cómo g encuentra sus variables.
e <- env()
e$g <- function() 1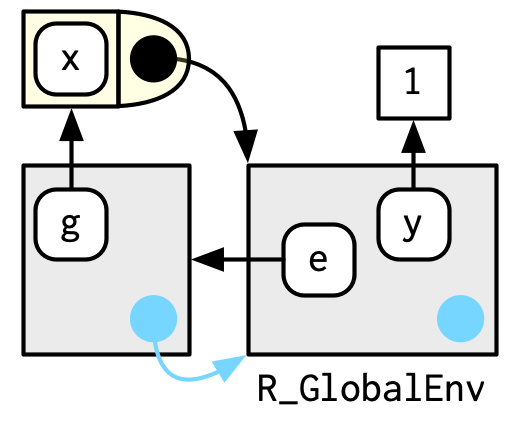
7.4.3 Espacios de nombres
En el diagrama anterior, vio que el entorno principal de un paquete varía según los otros paquetes que se hayan cargado. Esto parece preocupante: ¿no significa eso que el paquete encontrará diferentes funciones si los paquetes se cargan en un orden diferente? El objetivo de los espacios de nombres es asegurarse de que esto no suceda y de que todos los paquetes funcionen de la misma manera, independientemente de los paquetes que adjunte el usuario.
Por ejemplo, tome sd():
sd
#> function (x, na.rm = FALSE)
#> sqrt(var(if (is.vector(x) || is.factor(x)) x else as.double(x),
#> na.rm = na.rm))
#> <bytecode: 0x5556594f4ce0>
#> <environment: namespace:stats>sd() se define en términos de var(), por lo que podría preocuparse de que el resultado de sd() se vea afectado por cualquier función llamada var() ya sea en el entorno global o en uno de los otros paquetes adjuntos . R evita este problema aprovechando el entorno de función versus enlace descrito anteriormente. Cada función en un paquete está asociada con un par de entornos: el entorno del paquete, del que aprendió anteriormente, y el entorno del espacio de nombres.
El entorno del paquete es la interfaz externa del paquete. Así es como usted, el usuario de R, encuentra una función en un paquete adjunto o con
::. Su padre está determinado por la ruta de búsqueda, es decir, el orden en que se han adjuntado los paquetes.El entorno del espacio de nombres es la interfaz interna del paquete. El entorno del paquete controla cómo encontramos la función; el espacio de nombres controla cómo la función encuentra sus variables.
Cada enlace en el entorno del paquete también se encuentra en el entorno del espacio de nombres; esto asegura que cada función pueda usar cualquier otra función en el paquete. Pero algunos enlaces solo ocurren en el entorno del espacio de nombres. Estos se conocen como objetos internos o no exportados, que permiten ocultar al usuario detalles de implementación internos.
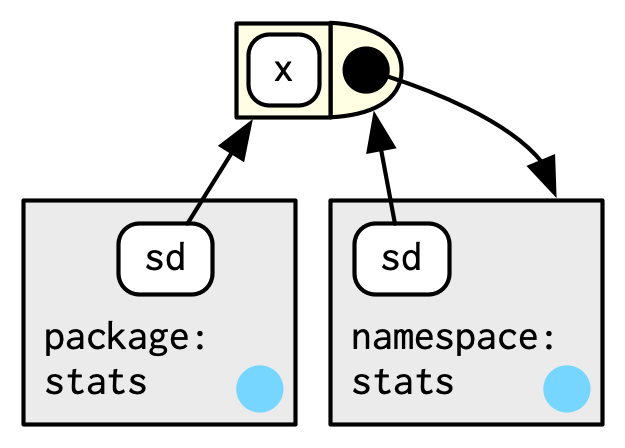
Cada entorno de espacio de nombres tiene el mismo conjunto de ancestros:
Cada espacio de nombres tiene un entorno de importaciones que contiene enlaces a todas las funciones utilizadas por el paquete. El entorno de importación está controlado por el desarrollador del paquete con el archivo
NAMESPACE.La importación explícita de cada función base sería tediosa, por lo que el padre del entorno de importación es el espacio de nombres base. El espacio de nombres base contiene los mismos enlaces que el entorno base, pero tiene un padre diferente.
El padre del espacio de nombres base es el entorno global. Esto significa que si un enlace no está definido en el entorno de importación, el paquete lo buscará de la forma habitual. Esto suele ser una mala idea (porque hace que el código dependa de otros paquetes cargados), por lo que
R CMD checkadvierte automáticamente sobre dicho código. Es necesario principalmente por razones históricas, particularmente debido a cómo funciona el envío del método S3.
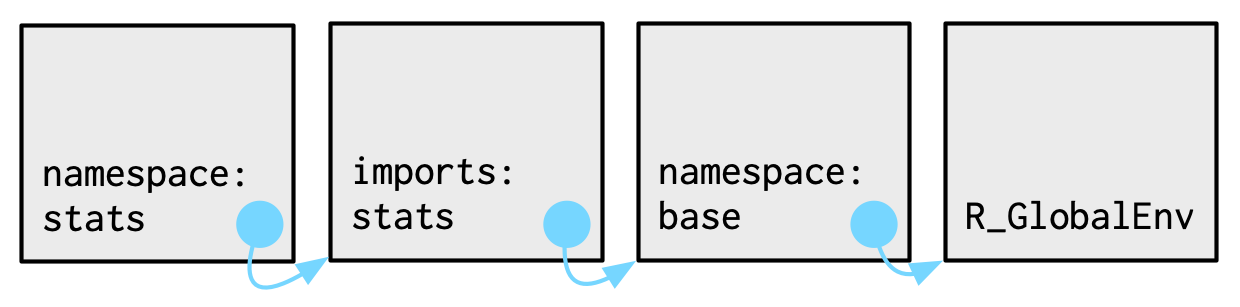
Juntando todos estos diagramas obtenemos:
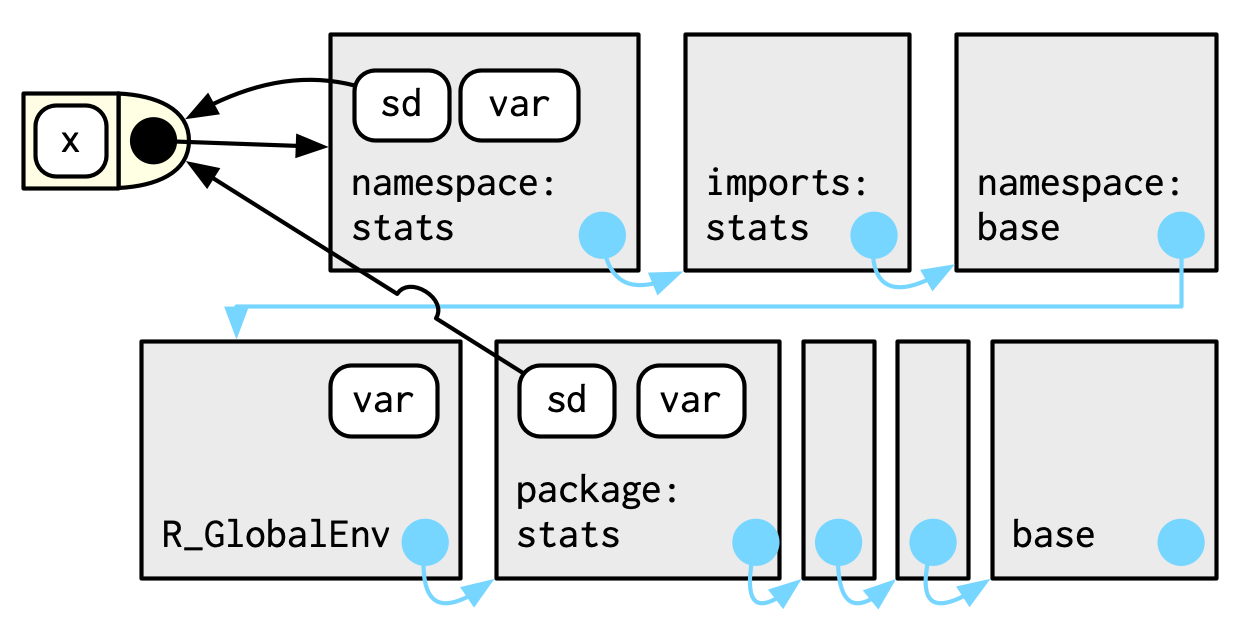
Entonces, cuando sd() busca el valor de var, siempre lo encuentra en una secuencia de entornos determinada por el desarrollador del paquete, pero no por el usuario del paquete. Esto garantiza que el código del paquete siempre funcione de la misma manera, independientemente de los paquetes que haya adjuntado el usuario.
No existe un vínculo directo entre el paquete y los entornos de espacio de nombres; el enlace está definido por los entornos de función.
7.4.4 Entornos de ejecución
El último tema importante que debemos cubrir es el entorno de ejecución. ¿Qué devolverá la siguiente función la primera vez que se ejecute? ¿Qué pasa con el segundo?
g <- function(x) {
if (!env_has(current_env(), "a")) {
message("Defining a")
a <- 1
} else {
a <- a + 1
}
a
}Piénsalo un momento antes de seguir leyendo.
g(10)
#> Defining a
#> [1] 1
g(10)
#> Defining a
#> [1] 1Esta función devuelve el mismo valor cada vez debido al principio de nuevo comienzo, descrito en la Sección 6.4.3. Cada vez que se llama a una función, se crea un nuevo entorno para albergar la ejecución. Esto se denomina entorno de ejecución y su padre es el entorno de funciones. Ilustremos ese proceso con una función más simple. La figura Figura 7.1 ilustra las convenciones gráficas: dibujo entornos de ejecución con un padre indirecto; el entorno principal se encuentra a través del entorno de función.
h <- function(x) {
# 1.
a <- 2 # 2.
x + a
}
y <- h(1) # 3.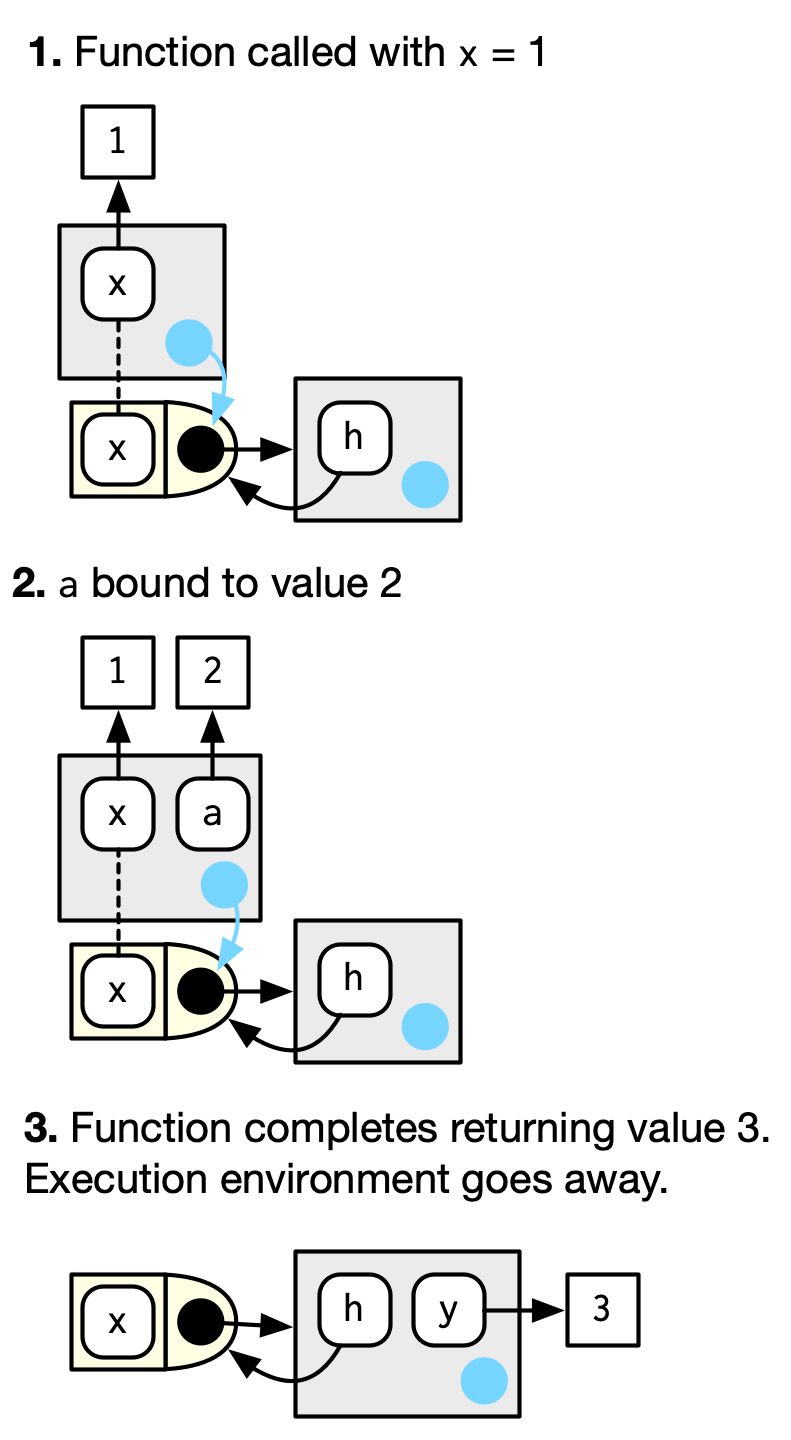
Un entorno de ejecución suele ser efímero; una vez que la función se haya completado, el entorno se recolectará como basura. Hay varias maneras de hacer que se quede por más tiempo. El primero es devolverlo explícitamente:
h2 <- function(x) {
a <- x * 2
current_env()
}
e <- h2(x = 10)
env_print(e)
#> <environment: 0x55565c1ce6d0>
#> Parent: <environment: global>
#> Bindings:
#> • a: <dbl>
#> • x: <dbl>
fn_env(h2)
#> <environment: R_GlobalEnv>Otra forma de capturarlo es devolver un objeto con un enlace a ese entorno, como una función. El siguiente ejemplo ilustra esa idea con una fábrica de funciones, plus(). Usamos esa fábrica para crear una función llamada plus_one().
Están sucediendo muchas cosas en el diagrama porque el entorno envolvente de plus_one() es el entorno de ejecución de plus().
plus <- function(x) {
function(y) x + y
}
plus_one <- plus(1)
plus_one
#> function(y) x + y
#> <environment: 0x55565ca465e8>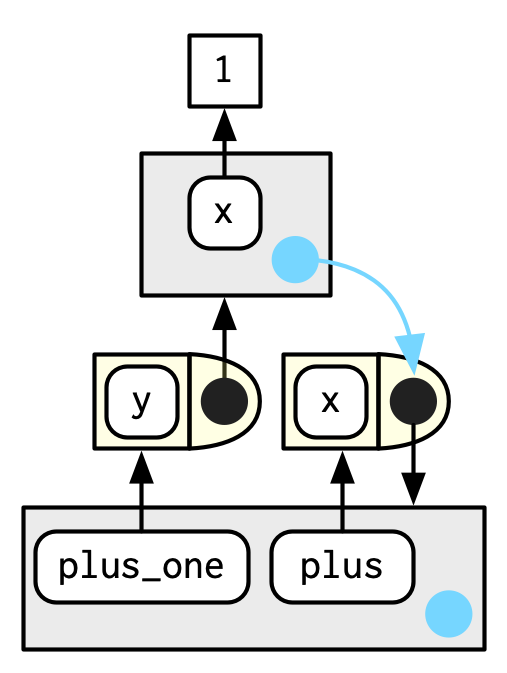
¿Qué sucede cuando llamamos plus_one()? Su entorno de ejecución tendrá el entorno de ejecución capturado de plus() como padre:
plus_one(2)
#> [1] 3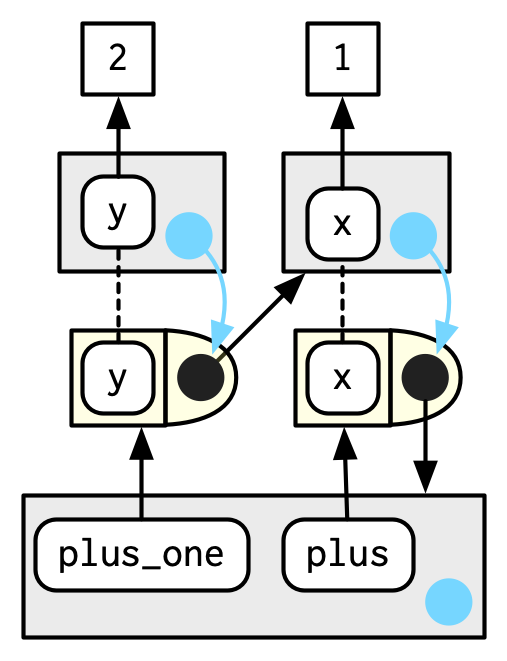
Aprenderá más sobre las fábricas de funciones en la Sección 10.2.
7.4.5 Ejercicios
¿En qué se diferencia
search_envs()deenv_parents(global_env())?Dibuje un diagrama que muestre los entornos circundantes de esta función:
f1 <- function(x1) { f2 <- function(x2) { f3 <- function(x3) { x1 + x2 + x3 } f3(3) } f2(2) } f1(1)Escriba una versión mejorada de
str()que proporcione más información sobre las funciones. Muestre dónde se encontró la función y en qué entorno se definió.
7.5 Pilas de llamadas
Hay un último entorno que debemos explicar, el entorno caller, al que se accede con rlang::caller_env(). Esto proporciona el entorno desde el que se llamó a la función y, por lo tanto, varía en función de cómo se llame a la función, no de cómo se creó. Como vimos anteriormente, este es un valor predeterminado útil cada vez que escribe una función que toma un entorno como argumento.
parent.frame() es equivalente a caller_env(); solo tenga en cuenta que devuelve un entorno, no un marco.
Para comprender completamente el entorno de la persona que llama, debemos analizar dos conceptos relacionados: la pila de llamadas, que se compone de marcos. La ejecución de una función crea dos tipos de contexto. Ya aprendió sobre uno: el entorno de ejecución es un elemento secundario del entorno de función, que está determinado por el lugar donde se creó la función. Hay otro tipo de contexto creado por donde se llamó a la función: esto se llama la pila de llamadas.
7.5.1 Pilas de llamadas simples
Ilustremos esto con una secuencia simple de llamadas: f() llama a g() llama a h().
f <- function(x) {
g(x = 2)
}
g <- function(x) {
h(x = 3)
}
h <- function(x) {
stop()
}La forma más común de ver una pila de llamadas en R es mirando el traceback() después de que haya ocurrido un error:
f(x = 1)
#> Error:
traceback()
#> 4: stop()
#> 3: h(x = 3)
#> 2: g(x = 2)
#> 1: f(x = 1)En lugar de stop() + traceback() para entender la pila de llamadas, vamos a usar lobstr::cst() para imprimir el árbol de pilas de llamadas (call stack tree, en inglés):
h <- function(x) {
lobstr::cst()
}
f(x = 1)
#> █
#> └─f(x = 1)
#> └─g(x = 2)
#> └─h(x = 3)
#> └─lobstr::cst()Esto nos muestra que cst() fue llamado desde h(), que fue llamado desde g(), que fue llamado desde f(). Tenga en cuenta que el orden es el opuesto de traceback(). A medida que las pilas de llamadas se vuelven más complicadas, creo que es más fácil entender la secuencia de llamadas si comienza desde el principio, en lugar del final (es decir, f() llama a g(); en lugar de g() fue llamado por f()).
7.5.2 Evaluación perezosa
La pila de llamadas anterior es simple: mientras obtiene una pista de que hay una estructura similar a un árbol involucrada, todo sucede en una sola rama. Esto es típico de una pila de llamadas cuando todos los argumentos se evalúan con entusiasmo.
Vamos a crear un ejemplo más complicado que implique una evaluación perezosa. Crearemos una secuencia de funciones, a(), b(), c(), que pasan un argumento x.
a <- function(x) b(x)
b <- function(x) c(x)
c <- function(x) x
a(f())
#> █
#> ├─a(f())
#> │ └─b(x)
#> │ └─c(x)
#> └─f()
#> └─g(x = 2)
#> └─h(x = 3)
#> └─lobstr::cst()x se evalúa perezosamente, por lo que este árbol tiene dos ramas. En la primera rama a() llama a b(), luego b() llama a c(). La segunda rama comienza cuando c() evalúa su argumento x. Este argumento se evalúa en una nueva rama porque el entorno en el que se evalúa es el entorno global, no el entorno de c().
7.5.3 Marcos
Cada elemento de la pila de llamadas es un marco3, también conocido como contexto de evaluación. El marco es una estructura de datos interna extremadamente importante, y el código R solo puede acceder a una pequeña parte de la estructura de datos porque manipularlo romperá R. Un marco tiene tres componentes clave:
Una expresión (etiquetada con
expr) que da la llamada a la función. Esto es lo que imprimetraceback().Un entorno (etiquetado con
env), que suele ser el entorno de ejecución de una función. Hay dos excepciones principales: el entorno del marco global es el entorno global, y llamar aeval()también genera marcos, donde el entorno puede ser cualquier cosa.Un padre, la llamada anterior en la pila de llamadas (se muestra con una flecha gris).
La figura Figura 7.2 ilustra la pila para la llamada a f(x = 1) que se muestra en la Sección 7.5.1.
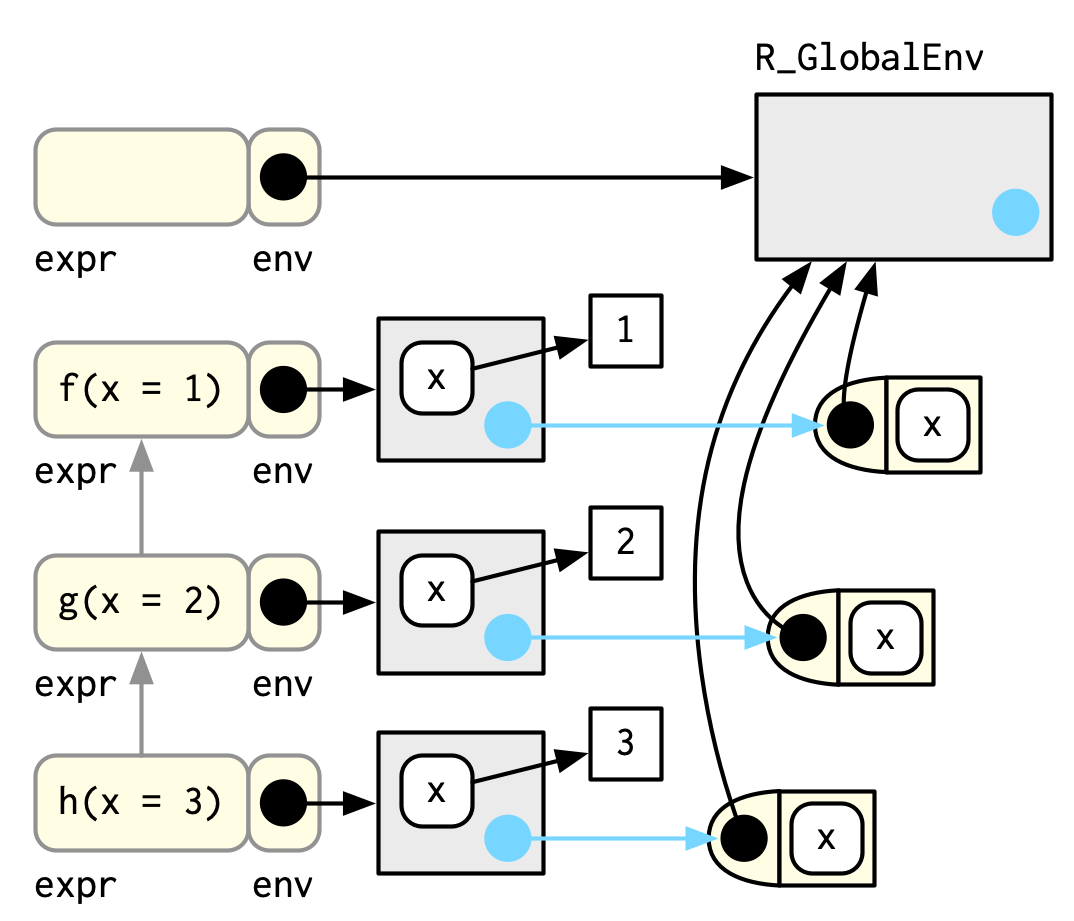
(Para centrarme en los entornos de llamada, he omitido los enlaces en el entorno global de f, g y h a los objetos de función respectivos.)
El marco también contiene controladores de salida creados con on.exit(), reinicios y controladores para el sistema de condiciones, y a qué contexto return() cuando se completa una función. Estos son detalles internos importantes a los que no se puede acceder con el código R.
7.5.4 Alcance dinámico
La búsqueda de variables en la pila de llamadas en lugar de en el entorno adjunto se denomina ámbito dinámico. Pocos lenguajes implementan el alcance dinámico (Emacs Lisp es una [excepción notable] (http://www.gnu.org/software/emacs/emacs-paper.html#SEC15).) Esto se debe a que el alcance dinámico hace que sea mucho más difícil razonar sobre cómo opera una función: no solo necesita saber cómo se definió, también necesita saber el contexto en el que se llamó. El alcance dinámico es principalmente útil para desarrollar funciones que ayudan al análisis interactivo de datos y es uno de los temas tratados en el Capítulo 20.
7.5.5 Ejercicios
- Escriba una función que enumere todas las variables definidas en el entorno en el que se llamó. Debería devolver los mismos resultados que
ls().
7.6 Como estructuras de datos
Además de potenciar el alcance, los entornos también son estructuras de datos útiles por derecho propio porque tienen semántica de referencia. Hay tres problemas comunes que pueden ayudar a resolver:
Evitar copias de datos de gran tamaño. Dado que los entornos tienen semántica de referencia, nunca creará una copia accidentalmente. Pero es complicado trabajar con entornos desnudos, por lo que en su lugar recomiendo usar objetos R6, que se construyen sobre los entornos. Obtenga más información en el Capítulo 14.
Administrar el estado dentro de un paquete. Los entornos explícitos son útiles en los paquetes porque le permiten mantener el estado en las llamadas a funciones. Normalmente, los objetos de un paquete están bloqueados, por lo que no puede modificarlos directamente. En su lugar, puedes hacer algo como esto:
my_env <- new.env(parent = emptyenv()) my_env$a <- 1 get_a <- function() { my_env$a } set_a <- function(value) { old <- my_env$a my_env$a <- value invisible(old) }Devolver el valor anterior de las funciones de establecimiento es un buen patrón porque hace que sea más fácil restablecer el valor anterior junto con
on.exit()(Sección 6.7.4).Como hashmap. Un hashmap es una estructura de datos que toma tiempo constante, O(1), para encontrar un objeto basado en su nombre. Los entornos proporcionan este comportamiento de forma predeterminada, por lo que se pueden usar para simular un mapa hash. Vea el paquete hash (Brown 2013) para un desarrollo completo de esta idea.
7.7 Respuestas de la prueba
Hay cuatro formas: cada objeto en un entorno debe tener un nombre; el orden no importa; los ambientes tienen padres; los entornos tienen semántica de referencia.
El padre del entorno global es el último paquete que cargó. El único entorno que no tiene un padre es el entorno vacío.
El entorno envolvente de una función es el entorno donde se creó. Determina dónde una función busca variables.
Use
caller_env()oparent.frame().<-siempre crea un enlace en el entorno actual;<<-vuelve a enlazar un nombre existente en un padre del entorno actual.
Quizás se pregunte por qué rlang tiene
env_poke()en lugar deenv_set(). Esto es por coherencia: las funciones_set()devuelven una copia modificada; Las funciones_poke()se modifican en su lugar.↩︎Tenga en cuenta la diferencia entre adjunto y cargado. Un paquete se carga automáticamente si accede a una de sus funciones usando
::; solo se adjunta a la ruta de búsqueda mediantelibrary()orequire().↩︎NB:
?environmentusa marco en un sentido diferente: “Los entornos consisten en un marco, o una colección de objetos con nombre, y un puntero a un entorno envolvente”. Evitamos este sentido de marco, que proviene de S, porque es muy específico y no se usa mucho en la base R. Por ejemplo, el marco enparent.frame()es un contexto de ejecución, no una colección de objetos con nombre.↩︎