df <- data.frame(runif(3), runif(3))
names(df) <- c(1, 2)2 Nombres y valores
2.1 Introducción
En R, es importante comprender la distinción entre un objeto y su nombre. Si lo hace, le ayudará a:
- Predecir con mayor precisión el rendimiento y el uso de memoria de su código.
- Escribir código más rápido evitando copias accidentales, una fuente importante de código lento.
- Comprender mejor las herramientas de programación funcional de R.
El objetivo de este capítulo es ayudarlo a comprender la distinción entre nombres y valores, y cuándo R copiará un objeto.
Prueba
Responda las siguientes preguntas para ver si puede omitir este capítulo con seguridad. Puede encontrar las respuestas al final del capítulo en la Sección 2.7.
Dado el siguiente data frame, ¿cómo creo una nueva columna llamada “3” que contenga la suma de
1y2? Solo puede usar$, no[[. ¿Qué hace que1,2y3sean desafiantes como nombres de variables?En el siguiente código, ¿cuánta memoria ocupa
y?x <- runif(1e6) y <- list(x, x, x)¿En qué línea se copia
aen el siguiente ejemplo?a <- c(1, 5, 3, 2) b <- a b[[1]] <- 10
Estructura
La Sección 2.2 lo introduce a la distinción entre nombres y valores, y explica cómo
<-crea un vínculo, o referencia, entre un nombre y un valor.La Sección 2.3 describe cuándo R hace una copia: cada vez que modificas un vector, es casi seguro que estás creando un nuevo vector modificado. Aprenderá a usar
tracemem()para averiguar cuándo se produce realmente una copia. Luego, explorará las implicaciones que se aplican a las llamadas a funciones, listas, data frames y vectores de caracteres.La Sección 2.4 explora las implicaciones de las dos secciones anteriores sobre cuánta memoria ocupa un objeto. Dado que su intuición puede estar profundamente equivocada y dado que
utils::object.size()es lamentablemente inexacto, aprenderá a usarlobstr::obj_size().La Sección 2.5 describe las dos excepciones importantes para copiar al modificar: con entornos y valores con un solo nombre, los objetos se modifican en su lugar.
La Sección 2.6 concluye el capítulo con una discusión sobre el recolector de basura, que libera la memoria utilizada por objetos que ya no están referenciados por un nombre.
Requisitos previos
Usaremos el paquete lobstr para profundizar en la representación interna de los objetos R.
library(lobstr)Fuentes
Los detalles de la gestión de memoria de R no están documentados en un solo lugar. Gran parte de la información de este capítulo se obtuvo de una lectura atenta de la documentación (en particular ?Memory y ?gc), la sección perfilado de memoria de Escribiendo extensiones R (R Core Team 2018b) y SEXPs de R internals (R Core Team 2018a). El resto lo descubrí leyendo el código fuente de C, realizando pequeños experimentos y haciendo preguntas sobre R-devel. Cualquier error es enteramente mío.
2.2 Binding basics
Considere este código:
x <- c(1, 2, 3)Es fácil leerlo como: “crear un objeto llamado ‘x’, que contenga los valores 1, 2 y 3”. Desafortunadamente, esa es una simplificación que conducirá a predicciones inexactas sobre lo que R realmente está haciendo detrás de escena. Es más exacto decir que este código está haciendo dos cosas:
- Está creando un objeto, un vector de valores,
c(1, 2, 3). - Y vincula ese objeto a un nombre,
x.
En otras palabras, el objeto, o valor, no tiene nombre; en realidad es el nombre el que tiene un valor.
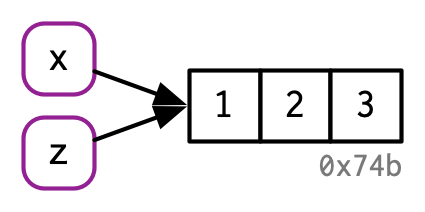
Para aclarar aún más esta distinción, dibujaré diagramas como este:
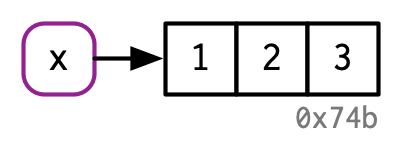
El nombre, x, se dibuja con un rectángulo redondeado. Tiene una flecha que apunta (o une o hace referencia) al valor, el vector c(1, 2, 3). La flecha apunta en dirección opuesta a la flecha de asignación: <- crea un enlace desde el nombre en el lado izquierdo hasta el objeto en el lado derecho.
Por lo tanto, puede pensar en un nombre como una referencia a un valor. Por ejemplo, si ejecuta este código, no obtiene otra copia del valor c(1, 2, 3), obtiene otro enlace al objeto existente:
y <- x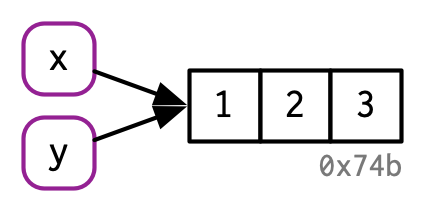
Es posible que hayas notado que el valor c(1, 2, 3) tiene una etiqueta: 0x74b. Si bien el vector no tiene nombre, ocasionalmente necesitaré referirme a un objeto independiente de sus enlaces. Para que eso sea posible, etiquetaré los valores con un identificador único. Estos identificadores tienen una forma especial que se parece a la “dirección” de la memoria del objeto, es decir, la ubicación en la memoria donde se almacena el objeto. Pero debido a que las direcciones de memoria reales cambian cada vez que se ejecuta el código, usamos estos identificadores en su lugar.
Puede acceder al identificador de un objeto con lobstr::obj_addr(). Hacerlo te permite ver que tanto x como y apuntan al mismo identificador:
obj_addr(x)
#> [1] "0x555f21add648"
obj_addr(y)
#> [1] "0x555f21add648"Estos identificadores son largos y cambian cada vez que reinicia R.
Puede tomar algún tiempo comprender la distinción entre nombres y valores, pero comprender esto es realmente útil en la programación funcional, donde las funciones pueden tener diferentes nombres en diferentes contextos.
2.2.1 Nombres no sintácticos
R tiene reglas estrictas sobre lo que constituye un nombre válido. Un nombre sintáctico debe constar de letras1, dígitos, . y _ pero no puede comenzar con _ o un dígito. Además, no puede usar ninguna de las palabras reservadas como TRUE, NULL, if y function (vea la lista completa en ?Reserved). Un nombre que no sigue estas reglas es un nombre no sintáctico; si intenta usarlos, obtendrá un error:
_abc <- 1
#> Error: unexpected input in "_"
if <- 10
#> Error: unexpected assignment in "if <-"Es posible anular estas reglas y usar cualquier nombre, es decir, cualquier secuencia de caracteres, rodeándolo con acentos graves:
`_abc` <- 1
`_abc`
#> [1] 1
`if` <- 10
`if`
#> [1] 10Si bien es poco probable que cree deliberadamente nombres tan locos, debe comprender cómo funcionan estos nombres locos porque los encontrará, más comúnmente cuando carga datos que se han creado fuera de R.
2.2.2 Ejercicios
Explique la relación entre
a,b,cyden el siguiente código:a <- 1:10 b <- a c <- b d <- 1:10El siguiente código accede a la función de media de varias maneras. ¿Todos apuntan al mismo objeto de función subyacente? Verifique esto con
lobstr::obj_addr().mean base::mean get("mean") evalq(mean) match.fun("mean")De forma predeterminada, las funciones de importación de datos base R, como
read.csv(), convertirán automáticamente los nombres no sintácticos en sintácticos. ¿Por qué podría ser esto problemático? ¿Qué opción le permite suprimir este comportamiento?¿Qué reglas usa
make.names()para convertir nombres no sintácticos en sintácticos?Simplifiqué ligeramente las reglas que rigen los nombres sintácticos. ¿Por qué
.123e1no es un nombre sintáctico? Lea?make.namespara obtener todos los detalles.
2.3 Copiar al modificar
Considere el siguiente código. Vincula x e y al mismo valor subyacente, luego modifica y2.
x <- c(1, 2, 3)
y <- x
y[[3]] <- 4
x
#> [1] 1 2 3Modificar y claramente no modificó x. Entonces, ¿qué pasó con el enlace compartido? Mientras que el valor asociado con y cambió, el objeto original no lo hizo. En su lugar, R creó un nuevo objeto, ‘0xcd2’, una copia de ‘0x74b’ con un valor cambiado, y luego rebotó ‘y’ a ese objeto.
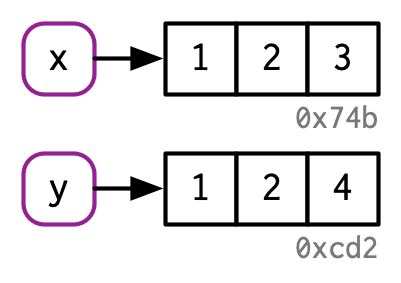
Este comportamiento se llama copiar al modificar. Comprenderlo mejorará radicalmente su intuición sobre el rendimiento del código R. Una forma relacionada de describir este comportamiento es decir que los objetos R no se pueden modificar o inmutables. Sin embargo, generalmente evitaré ese término porque hay un par de excepciones importantes para copiar al modificar que aprenderá en la Sección 2.5.
Al explorar el comportamiento de copiar al modificar de forma interactiva, tenga en cuenta que obtendrá diferentes resultados dentro de RStudio. Esto se debe a que el panel de entorno debe hacer una referencia a cada objeto para mostrar información sobre él. Esto distorsiona su exploración interactiva pero no afecta el código dentro de las funciones y, por lo tanto, no afecta el rendimiento durante el análisis de datos. Para experimentar, recomiendo ejecutar R directamente desde la terminal o usar Quarto (como este libro).
2.3.1 tracemem()
Puedes ver cuándo se copia un objeto con la ayuda de base::tracemem(). Una vez que llame a esa función con un objeto, obtendrá la dirección actual del objeto:
x <- c(1, 2, 3)
cat(tracemem(x), "\n")
#> <0x7f80c0e0ffc8> A partir de ese momento, cada vez que se copie ese objeto, tracemem() imprimirá un mensaje que le indicará qué objeto se copió, su nueva dirección y la secuencia de llamadas que llevaron a la copia:
y <- x
y[[3]] <- 4L
#> tracemem[0x7f80c0e0ffc8 -> 0x7f80c4427f40]: Si modifica y de nuevo, no se copiará. Esto se debe a que el nuevo objeto ahora solo tiene un único nombre vinculado, por lo que R aplica la optimización de modificación en el lugar. Volveremos a esto en la Sección 2.5.
y[[3]] <- 5L
untracemem(x)untracemem() es lo contrario de tracemem(); apaga el rastreo.
2.3.2 Llamadas de función
Las mismas reglas para copiar también se aplican a las llamadas a funciones. Toma este código:
f <- function(a) {
a
}
x <- c(1, 2, 3)
cat(tracemem(x), "\n")
#> <0x555f21a5faa8>
z <- f(x)
# there's no copy here!
untracemem(x)Mientras f() se está ejecutando, a dentro de la función apunta al mismo valor que x fuera de la función:
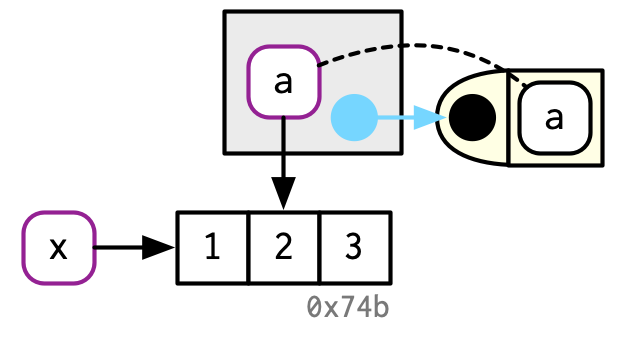
Aprenderá más sobre las convenciones utilizadas en este diagrama en la Sección 7.4.4. En resumen: la función f() está representada por el objeto amarillo a la derecha. Tiene un argumento formal, a, que se convierte en un enlace (indicado por una línea negra punteada) en el entorno de ejecución (el cuadro gris) cuando se ejecuta la función.
Una vez que f() se complete, x y z apuntarán al mismo objeto. 0x74b nunca se copia porque nunca se modifica. Si f() modificara x, R crearía una nueva copia y luego z vincularía ese objeto.
2.3.3 Listas
No son solo los nombres (es decir, las variables) los que apuntan a los valores; los elementos de las listas también lo hacen. Considere esta lista, que es superficialmente muy similar al vector numérico anterior:
l1 <- list(1, 2, 3)Esta lista es más compleja porque en lugar de almacenar los valores en sí, almacena referencias a ellos:
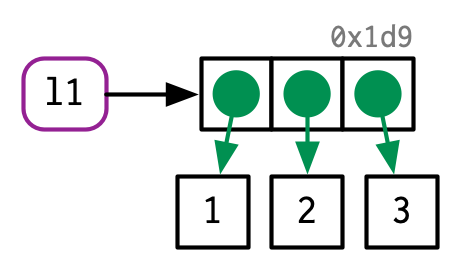
Esto es particularmente importante cuando modificamos una lista:
l2 <- l1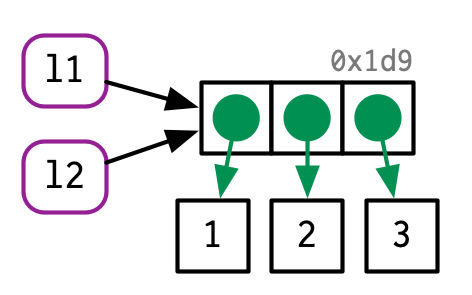
l2[[3]] <- 4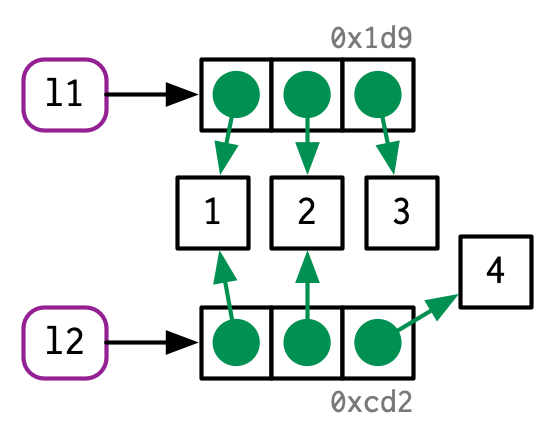
Al igual que los vectores, las listas utilizan el comportamiento de copiar al modificar; la lista original no se modifica y R crea una copia modificada. Esto, sin embargo, es una copia superficial: el objeto de la lista y sus enlaces se copian, pero los valores a los que apuntan los enlaces no. Lo opuesto a una copia superficial es una copia profunda donde se copian los contenidos de cada referencia. Antes de R 3.1.0, las copias siempre eran copias profundas.
Para ver los valores que se comparten en las listas, use lobstr::ref(). ref() imprime la dirección de memoria de cada objeto, junto con una identificación local para que pueda cruzar fácilmente los componentes compartidos.
ref(l1, l2)
#> █ [1:0x555f21824ff8] <list>
#> ├─[2:0x555f1f564700] <dbl>
#> ├─[3:0x555f1f564738] <dbl>
#> └─[4:0x555f1f564770] <dbl>
#>
#> █ [5:0x555f2195dd28] <list>
#> ├─[2:0x555f1f564700]
#> ├─[3:0x555f1f564738]
#> └─[6:0x555f1db58c20] <dbl>2.3.4 Data frames
Los data frames son listas de vectores, por lo que copiar al modificar tiene consecuencias importantes cuando modifica un data frame. Tome este data frame como un ejemplo:
d1 <- data.frame(x = c(1, 5, 6), y = c(2, 4, 3))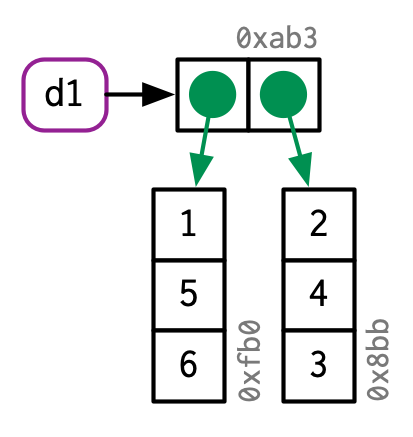
Si modifica una columna, solo esa columna debe modificarse; los otros seguirán apuntando a sus referencias originales:
d2 <- d1
d2[, 2] <- d2[, 2] * 2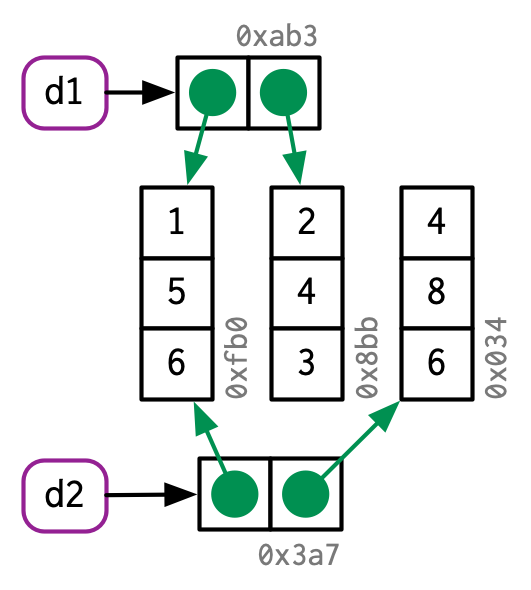
Sin embargo, si modifica una fila, se modifican todas las columnas, lo que significa que se deben copiar todas las columnas:
d3 <- d1
d3[1, ] <- d3[1, ] * 3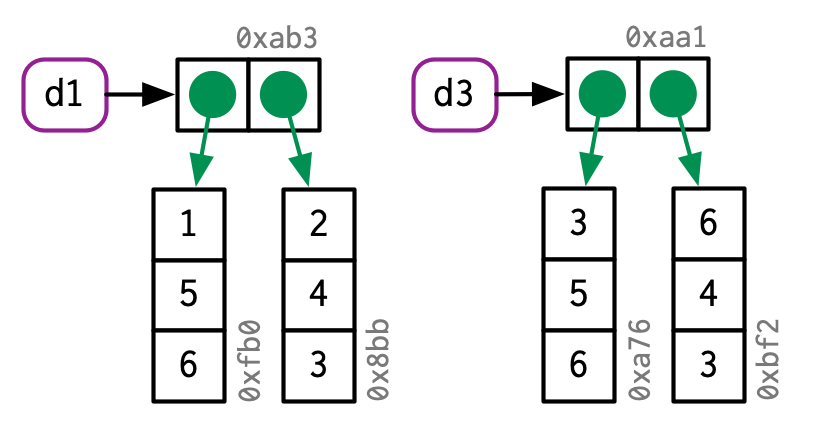
2.3.5 Vectores de caracteres
El último lugar donde R usa referencias es con vectores de caracteres 3. Normalmente dibujo vectores de caracteres como este:
x <- c("a", "a", "abc", "d")
Pero esto es una ficción educada. R en realidad usa un grupo de cadenas global donde cada elemento de un vector de caracteres es un puntero a una cadena única en el grupo:

Puede solicitar que ref() muestre estas referencias configurando el argumento character en TRUE:
ref(x, character = TRUE)
#> █ [1:0x555f1d1c23b8] <chr>
#> ├─[2:0x555f1b736a60] <string: "a">
#> ├─[2:0x555f1b736a60]
#> ├─[3:0x555f1ff4a738] <string: "abc">
#> └─[4:0x555f1bb8a978] <string: "d">Esto tiene un impacto profundo en la cantidad de memoria que usa un vector de caracteres, pero por lo demás generalmente no es importante, por lo que en otras partes del libro dibujaré vectores de caracteres como si las cadenas vivieran dentro de un vector.
2.3.6 Ejercicios
¿Por qué
tracemem(1:10)no es útil?Explique por qué
tracemem()muestra dos copias cuando ejecuta este código. Sugerencia: mire cuidadosamente la diferencia entre este código y el código que se muestra en la sección anterior.x <- c(1L, 2L, 3L) tracemem(x) x[[3]] <- 4Esboza la relación entre los siguientes objetos:
a <- 1:10 b <- list(a, a) c <- list(b, a, 1:10)¿Qué sucede cuando ejecutas este código?
x <- list(1:10) x[[2]] <- xDibuja una imagen.
2.4 Tamaño del objeto
Puedes averiguar cuánta memoria ocupa un objeto con lobstr::obj_size()4:
obj_size(letters)
#> 1.71 kB
obj_size(ggplot2::diamonds)
#> 3.46 MBDado que los elementos de las listas son referencias a valores, el tamaño de una lista puede ser mucho más pequeño de lo esperado:
x <- runif(1e6)
obj_size(x)
#> 8.00 MB
y <- list(x, x, x)
obj_size(y)
#> 8.00 MBy es sólo 80 bytes5 mayor que x. Ese es el tamaño de una lista vacía con tres elementos:
obj_size(list(NULL, NULL, NULL))
#> 80 BDel mismo modo, debido a que R usa un grupo de cadenas global, los vectores de caracteres ocupan menos memoria de lo que cabría esperar: repetir una cadena 100 veces no hace que ocupe 100 veces más memoria.
banana <- "bananas bananas bananas"
obj_size(banana)
#> 136 B
obj_size(rep(banana, 100))
#> 928 BLas referencias también dificultan pensar en el tamaño de los objetos individuales. obj_size(x) + obj_size(y) solo será igual a obj_size(x, y) si no hay valores compartidos. Aquí, el tamaño combinado de x e y es el mismo que el tamaño de y:
obj_size(x, y)
#> 8.00 MBFinalmente, R 3.5.0 y las versiones posteriores tienen una función que podría generar sorpresas: ALTREP, abreviatura de representación alternativa. Esto permite que R represente ciertos tipos de vectores de forma muy compacta. El lugar donde es más probable que vea esto es con : porque en lugar de almacenar cada número en la secuencia, R solo almacena el primer y el último número. Esto significa que cada secuencia, sin importar cuán grande sea, tiene el mismo tamaño:
obj_size(1:3)
#> 680 B
obj_size(1:1e3)
#> 680 B
obj_size(1:1e6)
#> 680 B
obj_size(1:1e9)
#> 680 B2.4.1 Ejercicios
En el siguiente ejemplo, ¿por qué
object.size(y)yobj_size(y)son tan radicalmente diferentes? Consulta la documentación deobject.size().y <- rep(list(runif(1e4)), 100) object.size(y) #> 8005648 bytes obj_size(y) #> 80.90 kBToma la siguiente lista. ¿Por qué su tamaño es algo engañoso?
funs <- list(mean, sd, var) obj_size(funs) #> 18.76 kBPrediga la salida del siguiente código:
a <- runif(1e6) obj_size(a) b <- list(a, a) obj_size(b) obj_size(a, b) b[[1]][[1]] <- 10 obj_size(b) obj_size(a, b) b[[2]][[1]] <- 10 obj_size(b) obj_size(a, b)
2.5 Modificar en el lugar
Como hemos visto anteriormente, modificar un objeto R generalmente crea una copia. Hay dos excepciones:
Los objetos con un solo enlace obtienen una optimización de rendimiento especial.
Los entornos, un tipo especial de objeto, siempre se modifican en su lugar.
2.5.1 Objetos con un solo enlace
Si un objeto tiene un solo nombre vinculado, R lo modificará en su lugar:
v <- c(1, 2, 3)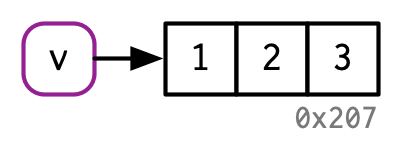
v[[3]] <- 4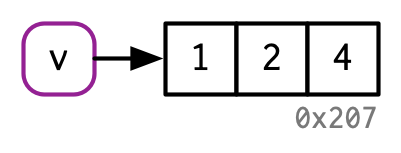
(Tenga en cuenta los ID de objeto aquí: v continúa enlazando con el mismo objeto, 0x207).
Dos complicaciones hacen que predecir exactamente cuándo R aplica esta optimización sea un desafío:
Cuando se trata de enlaces, R actualmente puede 6 solo contar 0, 1 o muchos. Eso significa que si un objeto tiene dos enlaces y uno desaparece, el recuento de referencias no vuelve a 1: uno menos que muchos sigue siendo muchos. A su vez, esto significa que R hará copias cuando a veces no sea necesario.
Cada vez que llama a la gran mayoría de las funciones, hace una referencia al objeto. La única excepción son las funciones C “primitivas” especialmente escritas. Estos solo pueden ser escritos por R-core y ocurren principalmente en el paquete base.
Juntas, estas dos complicaciones hacen que sea difícil predecir si se producirá o no una copia. En cambio, es mejor determinarlo empíricamente con tracemem().
Exploremos las sutilezas con un caso de estudio usando bucles for. Los bucles for tienen la reputación de ser lentos en R, pero a menudo esa lentitud se debe a que cada iteración del bucle crea una copia. Considere el siguiente código. Resta la mediana de cada columna de un data frame grande:
x <- data.frame(matrix(runif(5 * 1e4), ncol = 5))
medians <- vapply(x, median, numeric(1))
for (i in seq_along(medians)) {
x[[i]] <- x[[i]] - medians[[i]]
}Este ciclo es sorprendentemente lento porque cada iteración del ciclo copia el data frame. Puedes ver esto usando tracemem():
cat(tracemem(x), "\n")
#> <0x7f80c429e020>
for (i in 1:5) {
x[[i]] <- x[[i]] - medians[[i]]
}
#> tracemem[0x7f80c429e020 -> 0x7f80c0c144d8]:
#> tracemem[0x7f80c0c144d8 -> 0x7f80c0c14540]: [[<-.data.frame [[<-
#> tracemem[0x7f80c0c14540 -> 0x7f80c0c145a8]: [[<-.data.frame [[<-
#> tracemem[0x7f80c0c145a8 -> 0x7f80c0c14610]:
#> tracemem[0x7f80c0c14610 -> 0x7f80c0c14678]: [[<-.data.frame [[<-
#> tracemem[0x7f80c0c14678 -> 0x7f80c0c146e0]: [[<-.data.frame [[<-
#> tracemem[0x7f80c0c146e0 -> 0x7f80c0c14748]:
#> tracemem[0x7f80c0c14748 -> 0x7f80c0c147b0]: [[<-.data.frame [[<-
#> tracemem[0x7f80c0c147b0 -> 0x7f80c0c14818]: [[<-.data.frame [[<-
#> tracemem[0x7f80c0c14818 -> 0x7f80c0c14880]:
#> tracemem[0x7f80c0c14880 -> 0x7f80c0c148e8]: [[<-.data.frame [[<-
#> tracemem[0x7f80c0c148e8 -> 0x7f80c0c14950]: [[<-.data.frame [[<-
#> tracemem[0x7f80c0c14950 -> 0x7f80c0c149b8]:
#> tracemem[0x7f80c0c149b8 -> 0x7f80c0c14a20]: [[<-.data.frame [[<-
#> tracemem[0x7f80c0c14a20 -> 0x7f80c0c14a88]: [[<-.data.frame [[<-
untracemem(x)De hecho, cada iteración copia el data frame no una, ni dos, ¡sino tres veces! Se hacen dos copias con [[.data.frame, y se hace otra copia7 porque [[.data.frame es una función normal que incrementa el recuento de referencias de x.
Podemos reducir el número de copias usando una lista en lugar de un data frame. La modificación de una lista utiliza código C interno, por lo que las referencias no se incrementan y no se realiza ninguna copia:
y <- as.list(x)
cat(tracemem(y), "\n")
#> <0x7f80c5c3de20>
for (i in 1:5) {
y[[i]] <- y[[i]] - medians[[i]]
}Si bien no es difícil determinar cuándo se realiza una copia, es difícil evitarlo. Si se encuentra recurriendo a trucos exóticos para evitar copias, puede ser hora de reescribir su función en C++, como se describe en el Capítulo 25.
2.5.2 Entornos
Aprenderá más sobre los entornos en el Capítulo 7, pero es importante mencionarlos aquí porque su comportamiento es diferente al de otros objetos: los entornos siempre se modifican en su lugar. Esta propiedad a veces se describe como semántica de referencia porque cuando modifica un entorno, todos los enlaces existentes a ese entorno continúan teniendo la misma referencia.
Tome este entorno, que vinculamos a e1 y e2:
e1 <- rlang::env(a = 1, b = 2, c = 3)
e2 <- e1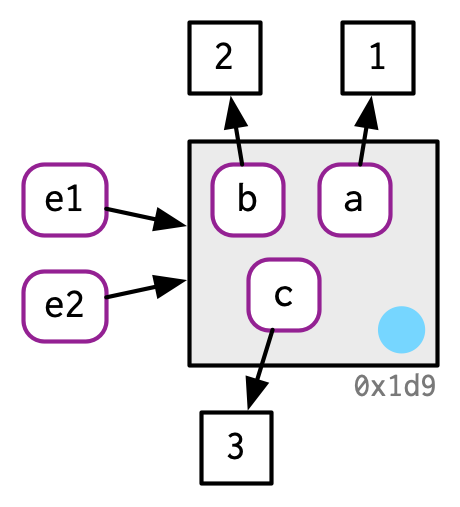
Si cambiamos un enlace, el entorno se modifica en su lugar:
e1$c <- 4
e2$c
#> [1] 4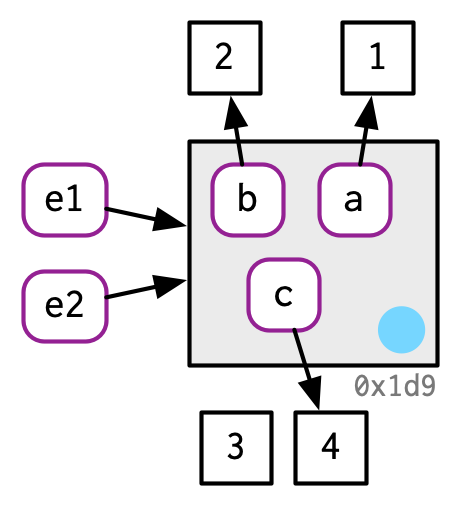
Esta idea básica se puede utilizar para crear funciones que “recuerden” su estado anterior. Consulte la Sección 10.2.4 para obtener más detalles. Esta propiedad también se usa para implementar el sistema de programación orientado a objetos R6, el tema del Capítulo 14.
Una consecuencia de esto es que los entornos pueden contenerse a sí mismos:
e <- rlang::env()
e$self <- e
ref(e)
#> █ [1:0x555f1ef9a6a8] <env>
#> └─self = [1:0x555f1ef9a6a8]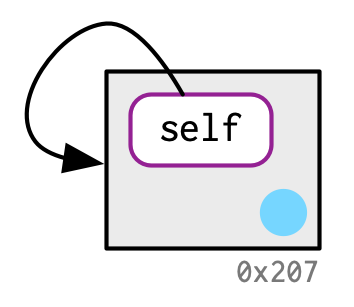
¡Esta es una propiedad única de los entornos!
2.5.3 Ejercicios
Explique por qué el siguiente código no crea una lista circular.
x <- list() x[[1]] <- xEnvuelva los dos métodos para restar medianas en dos funciones, luego use el paquete
bench(Hester 2018) para comparar cuidadosamente sus velocidades. ¿Cómo cambia el rendimiento a medida que aumenta el número de columnas?¿Qué sucede si intenta usar
tracemem()en un entorno?
2.6 Desvincular y el recolector de basura.
Considere este código:
x <- 1:3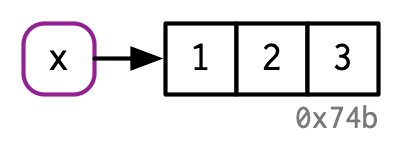
x <- 2:4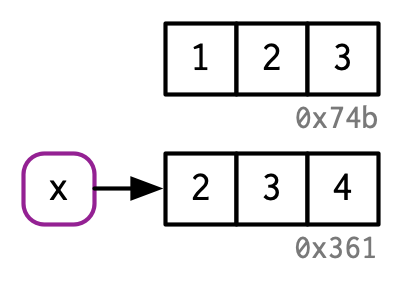
rm(x)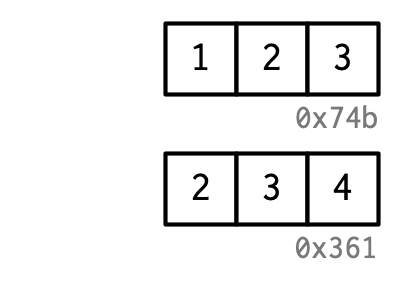
Creamos dos objetos, pero cuando finaliza el código, ninguno de los objetos está vinculado a un nombre. ¿Cómo se eliminan estos objetos? Ese es el trabajo del recolector de basura, o GC para abreviar. El GC libera memoria eliminando objetos R que ya no se usan y solicitando más memoria del sistema operativo si es necesario.
R utiliza un GC de trazado. Esto significa que rastrea todos los objetos a los que se puede acceder desde el entorno global8 y todos los objetos a los que, a su vez, se puede acceder desde esos objetos (es decir, las referencias en listas y entornos se buscan de forma recursiva). El recolector de elementos no utilizados no utiliza el recuento de referencias de modificación en el lugar descrito anteriormente. Si bien estas dos ideas están estrechamente relacionadas, las estructuras de datos internas están optimizadas para diferentes casos de uso.
El recolector de basura (GC) se ejecuta automáticamente cada vez que R necesita más memoria para crear un nuevo objeto. Mirando desde el exterior, es básicamente imposible predecir cuándo se ejecutará el GC. De hecho, ni siquiera deberías intentarlo. Si desea saber cuándo se ejecuta GC, llame a gcinfo(TRUE) y GC imprimirá un mensaje en la consola cada vez que se ejecute.
Puedes forzar la recolección de basura llamando a gc(). Pero a pesar de lo que hayas leído en otros lugares, nunca hay necesidad de llamar a gc() tú mismo. Las únicas razones por las que podría querer llamar a gc() es para pedirle a R que devuelva la memoria a su sistema operativo para que otros programas puedan usarla, o por el efecto secundario que le dice cuánta memoria se está usando actualmente:
gc()
#> used (Mb) gc trigger (Mb) max used (Mb)
#> Ncells 1028686 55.0 2064407 110 1794553 95.9
#> Vcells 5399124 41.2 15002373 114 14995530 114.5lobstr::mem_used() es un envoltorio alrededor de gc() que imprime el número total de bytes utilizados:
mem_used()
#> 100.77 MBEste número no coincidirá con la cantidad de memoria informada por su sistema operativo. Hay tres razones:
Incluye objetos creados por R pero no por el intérprete de R.
Tanto R como el sistema operativo son perezosos: no reclamarán memoria hasta que realmente se necesite. R podría estar reteniendo la memoria porque el sistema operativo aún no la ha solicitado.
R cuenta la memoria ocupada por objetos, pero puede haber espacios vacíos debido a objetos eliminados. Este problema se conoce como fragmentación de la memoria.
2.7 Respuestas de la prueba
Debe citar nombres no sintácticos con acentos graves:
`: por ejemplo, las variables1,2y3.df <- data.frame(runif(3), runif(3)) names(df) <- c(1, 2) df$`3` <- df$`1` + df$`2`Ocupa unos 8 MB.
x <- runif(1e6) y <- list(x, x, x) obj_size(y) #> 8.00 MBase copia cuando se modificab,b[[1]] <- 10.
Sorprendentemente, precisamente lo que constituye una letra está determinado por su ubicación actual. Eso significa que la sintaxis del código R en realidad puede diferir de una computadora a otra, y que es posible que un archivo que funciona en una computadora ni siquiera se analice en otra. Evite este problema apegado a los caracteres ASCII (es decir, A-Z) tanto como sea posible.↩︎
Es posible que se sorprenda al ver que
[[se usa para crear un subconjunto de un vector numérico. Volveremos a esto en la Sección 4.3, pero en resumen, creo que siempre debes usar[[cuando obtienes o configuras un solo elemento.↩︎Confusamente, un vector de caracteres es un vector de cadenas, no de caracteres individuales.↩︎
Tenga cuidado con la función
utils::object.size(). No tiene en cuenta correctamente las referencias compartidas y devolverá tamaños que son demasiado grandes.↩︎Si está ejecutando R de 32 bits, verá tamaños ligeramente diferentes.↩︎
Para cuando lea esto, es posible que esto haya cambiado, ya que hay planes en marcha para mejorar el conteo de referencias: https://developer.r-project.org/Refcnt.html↩︎
Estas copias son superficiales: solo copian la referencia a cada columna individual, no el contenido de las columnas. Esto significa que el rendimiento no es terrible, pero obviamente no es tan bueno como podría ser.↩︎
Y todos los entornos de la pila de llamadas actual.↩︎