16 Compensaciones
16.1 Introducción
Ahora conoce los tres conjuntos de herramientas OOP más importantes disponibles en R. Ahora que comprende su funcionamiento básico y los principios que los sustentan, podemos comenzar a comparar y contrastar los sistemas para comprender sus fortalezas y debilidades. Esto le ayudará a elegir el sistema que tiene más probabilidades de resolver nuevos problemas.
En general, al elegir un sistema OO, le recomiendo que utilice S3 de forma predeterminada. S3 es simple y se usa ampliamente en base R y CRAN. Si bien está lejos de ser perfecto, sus idiosincrasias se comprenden bien y existen enfoques conocidos para superar la mayoría de las deficiencias. Si tiene experiencia previa en programación, es probable que se incline hacia R6, porque le resultará familiar. Creo que deberías resistirte a esta tendencia por dos razones. En primer lugar, si usa R6, es muy fácil crear una API no idiomática que se sentirá muy extraña para los usuarios nativos de R y tendrá puntos débiles sorprendentes debido a la semántica de referencia. En segundo lugar, si se apega a R6, perderá el aprendizaje de una nueva forma de pensar sobre OOP que le brinda un nuevo conjunto de herramientas para resolver problemas.
Estructura
La Sección 16.2 compara S3 y S4. En resumen, S4 es más formal y tiende a requerir una planificación más anticipada. Eso lo hace más adecuado para grandes proyectos desarrollados por equipos, no individualmente.
La Sección 16.3 compara S3 y R6. Esta sección es bastante larga porque estos dos sistemas son fundamentalmente diferentes y hay una serie de compensaciones que debe tener en cuenta.
Requisitos previos
Debe estar familiarizado con S3, S4 y R6, como se explicó en los tres capítulos anteriores.
16.2 S4 contra S3
Una vez que haya dominado S3, S4 no es demasiado difícil de entender: las ideas subyacentes son las mismas, S4 es simplemente más formal, más estricto y más detallado. El rigor y la formalidad de S4 lo hacen ideal para equipos grandes. Dado que el propio sistema proporciona más estructura, hay menos necesidad de convenciones y los nuevos contribuyentes no necesitan tanta formación. S4 tiende a requerir un diseño más inicial que S3, y es más probable que esta inversión rinda frutos en proyectos más grandes donde hay más recursos disponibles.
Un gran esfuerzo de equipo donde S4 se usa con buenos resultados es Bioconductor. Bioconductor es similar a CRAN: es una forma de compartir paquetes entre una audiencia más amplia. Bioconductor es más pequeño que CRAN (~1,300 versus ~10,000 paquetes, julio de 2017) y los paquetes tienden a estar más estrechamente integrados debido al dominio compartido y porque Bioconductor tiene un proceso de revisión más estricto. No se requieren paquetes de bioconductores para usar S4, pero la mayoría lo hará porque las estructuras de datos clave (por ejemplo, SummarizedExperiment, IRanges, DNAStringSet) se construyen usando S4.
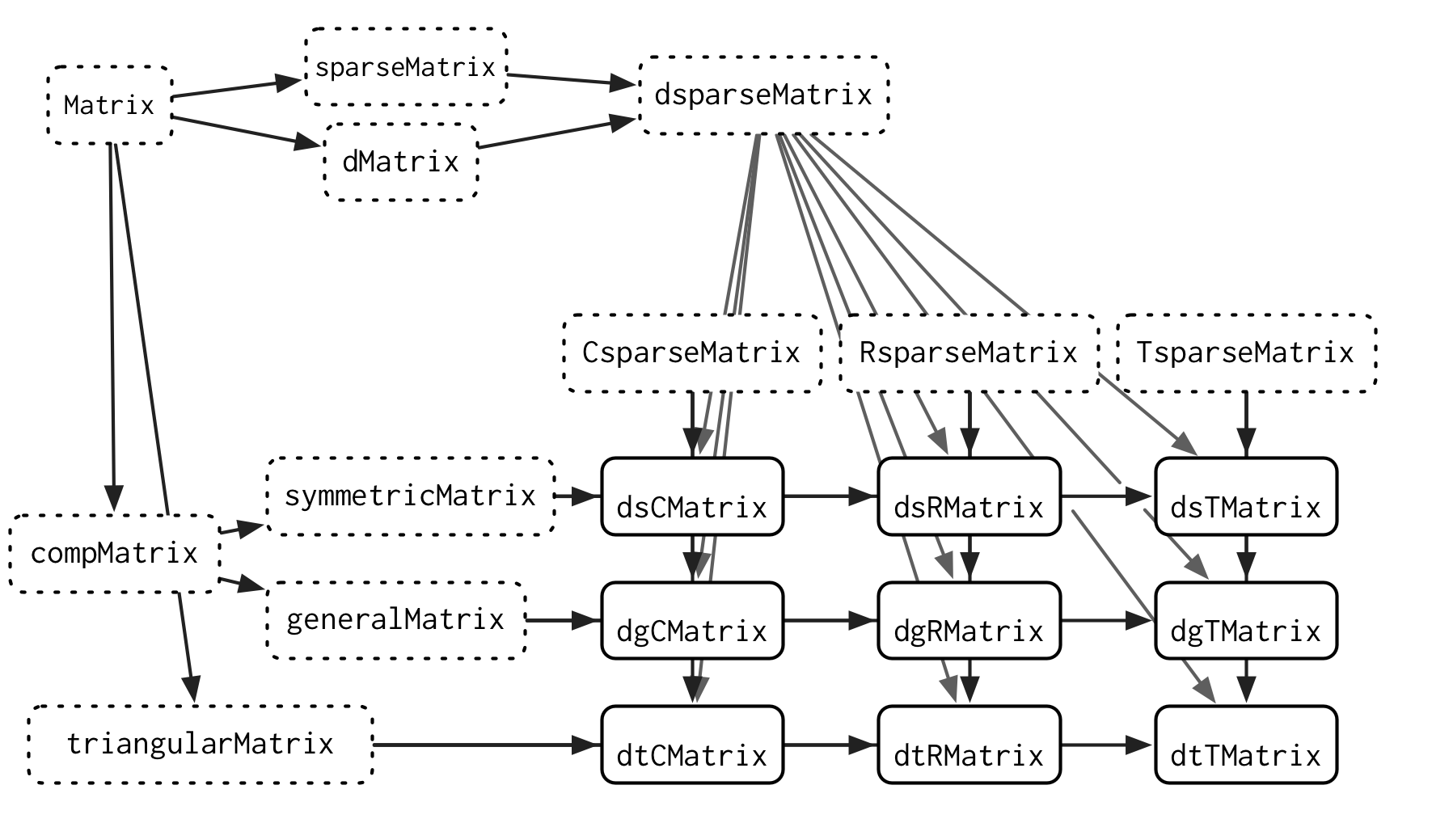
S4 también es una buena opción para sistemas complejos de objetos interrelacionados, y es posible minimizar la duplicación de código mediante la implementación cuidadosa de métodos. El mejor ejemplo de tal sistema es el paquete Matrix (Bates y Maechler 2018). Está diseñado para almacenar y calcular de manera eficiente con muchos tipos diferentes de matrices densas y dispersas. A partir de la versión 1.7.0, define clases 108, funciones genéricas 23 y métodos 1780, y para darle una idea de la complejidad, se muestra un pequeño subconjunto del gráfico de clase en Figura 16.1.
Este dominio es una buena opción para S4 porque a menudo hay atajos computacionales para combinaciones específicas de matrices dispersas. S4 facilita proporcionar un método general que funcione para todas las entradas y luego proporcionar métodos más especializados donde las entradas permiten una implementación más eficiente. Esto requiere una planificación cuidadosa para evitar la ambigüedad en el envío de métodos, pero la planificación compensa con un mayor rendimiento.
El mayor desafío para usar S4 es la combinación de una mayor complejidad y la ausencia de una única fuente de documentación. S4 es un sistema complejo y su uso eficaz en la práctica puede resultar complicado. Esto no sería un gran problema si la documentación de S4 no estuviera dispersa en la documentación, los libros y los sitios web de R. S4 necesita un tratamiento de longitud de libro, pero ese libro (todavía) no existe. (La documentación para S3 no es mejor, pero la falta es menos dolorosa porque S3 es mucho más simple).
16.3 R6 contra S3
R6 es un sistema OO profundamente diferente de S3 y S4 porque se basa en objetos encapsulados, en lugar de funciones genéricas. Además, los objetos R6 tienen semántica de referencia, lo que significa que se pueden modificar en su lugar. Estas dos grandes diferencias tienen una serie de consecuencias no obvias que exploraremos aquí:
Un genérico es una función regular, por lo que vive en el espacio de nombres global. Un método R6 pertenece a un objeto, por lo que vive en un espacio de nombres local. Esto influye en cómo pensamos acerca de nombrar.
La semántica de referencia de R6 permite que los métodos devuelvan un valor y modifiquen un objeto simultáneamente. Esto resuelve un doloroso problema llamado “estado de subprocesamiento”.
Invocas un método R6 usando
$, que es un operador infijo. Si configura sus métodos correctamente, puede usar cadenas de llamadas a métodos como una alternativa a la canalización.
Estas son compensaciones generales entre OOP funcional y encapsulado, por lo que también sirven como una discusión sobre el diseño del sistema en R versus Python.
16.3.1 Espacio de nombres
Una diferencia no obvia entre S3 y R6 es el espacio en el que se encuentran los métodos:
- Las funciones genéricas son globales: todos los paquetes comparten el mismo espacio de nombres.
- Los métodos encapsulados son locales: los métodos están vinculados a un solo objeto.
La ventaja de un espacio de nombres global es que varios paquetes pueden usar los mismos verbos para trabajar con diferentes tipos de objetos. Las funciones genéricas proporcionan una API uniforme que facilita la realización de acciones típicas con un nuevo objeto porque existen fuertes convenciones de nomenclatura. Esto funciona bien para el análisis de datos porque a menudo desea hacer lo mismo con diferentes tipos de objetos. En particular, esta es una de las razones por las que el sistema de modelado de R es tan útil: independientemente de dónde se haya implementado el modelo, siempre se trabaja con él usando el mismo conjunto de herramientas (summary(), predict(), … ).
La desventaja de un espacio de nombres global es que lo obliga a pensar más profundamente sobre la asignación de nombres. Desea evitar múltiples genéricos con el mismo nombre en diferentes paquetes porque requiere que el usuario escriba :: con frecuencia. Esto puede ser difícil porque los nombres de las funciones suelen ser verbos en inglés y los verbos suelen tener varios significados. Toma plot() por ejemplo:
plot(data) # plot some data
plot(bank_heist) # plot a crime
plot(land) # create a new plot of land
plot(movie) # extract plot of a movieEn general, debe evitar los métodos que son homónimos del genérico original y, en su lugar, definir un nuevo genérico.
Este problema no ocurre con los métodos R6 porque están en el ámbito del objeto. El siguiente código está bien, porque no implica que el método de trazado de dos objetos R6 diferentes tenga el mismo significado:
data$plot()
bank_heist$plot()
land$plot()
movie$plot()Estas consideraciones también se aplican a los argumentos a la genérica. Los genéricos de S3 deben tener los mismos argumentos centrales, lo que significa que generalmente tienen nombres no específicos como x o .data. Los genéricos de S3 generalmente necesitan ... para pasar argumentos adicionales a los métodos, pero esto tiene la desventaja de que los nombres de los argumentos mal escritos no generarán un error. En comparación, los métodos R6 pueden variar más ampliamente y usar nombres de argumentos más específicos y sugerentes.
Una ventaja secundaria del espacio de nombres local es que crear un método R6 es muy económico. La mayoría de los lenguajes OO encapsulados lo alientan a crear muchos métodos pequeños, cada uno de los cuales hace una cosa bien con un nombre evocador. Crear un nuevo método S3 es más costoso, porque es posible que también deba crear uno genérico y pensar en los problemas de nombres descritos anteriormente. Eso significa que el consejo de crear muchos métodos pequeños no se aplica a S3. Todavía es una buena idea dividir el código en fragmentos pequeños y fáciles de entender, pero por lo general deberían ser solo funciones regulares, no métodos.
16.3.2 Estado de enhebrado
Un desafío de programar con S3 es cuando desea devolver un valor y modificar el objeto. Esto viola nuestra pauta de que se debe llamar a una función por su valor de retorno o por sus efectos secundarios, pero es necesario en algunos casos.
Por ejemplo, imagina que quieres crear una pila de objetos. Una pila tiene dos métodos principales:
push()agrega un nuevo objeto a la parte superior de la pila.pop()devuelve el valor superior y lo elimina de la pila.
La implementación del constructor y el método push() es sencilla. Una pila contiene una lista de elementos, y empujar un objeto a la pila simplemente se agrega a esta lista.
new_stack <- function(items = list()) {
structure(list(items = items), class = "stack")
}
push <- function(x, y) {
x$items <- c(x$items, list(y))
x
}(No he creado un método real para push() porque hacerlo genérico solo haría que este ejemplo fuera más complicado sin ningún beneficio real).
Implementar pop() es más desafiante porque tiene que devolver un valor (el objeto en la parte superior de la pila) y tener un efecto secundario (eliminar ese objeto de esa parte superior). Como no podemos modificar el objeto de entrada en S3, debemos devolver dos cosas: el valor y el objeto actualizado.
pop <- function(x) {
n <- length(x$items)
item <- x$items[[n]]
x$items <- x$items[-n]
list(item = item, x = x)
}Esto conduce a un uso bastante incómodo:
s <- new_stack()
s <- push(s, 10)
s <- push(s, 20)
out <- pop(s)
out$item
#> [1] 20
s <- out$x
s
#> $items
#> $items[[1]]
#> [1] 10
#>
#>
#> attr(,"class")
#> [1] "stack"Este problema se conoce como estado de subprocesamiento o programación del acumulador, porque no importa qué tan profundamente se llame a pop(), debe enhebrar el objeto de pila modificado hasta donde vive.
Una forma en que otros lenguajes de FP enfrentan este desafío es proporcionar un operador de asignación múltiple (o enlace de desestructuración) que le permite asignar múltiples valores en un solo paso. El paquete zeallot (Teetor 2018) proporciona asignaciones múltiples para R con %<-%. Esto hace que el código sea más elegante, pero no resuelve el problema clave:
library(zeallot)
c(value, s) %<-% pop(s)
value
#> [1] 10Una implementación R6 de una pila es más simple porque $pop() puede modificar el objeto en su lugar y devolver solo el valor más alto:
Stack <- R6::R6Class("Stack", list(
items = list(),
push = function(x) {
self$items <- c(self$items, x)
invisible(self)
},
pop = function() {
item <- self$items[[self$length()]]
self$items <- self$items[-self$length()]
item
},
length = function() {
length(self$items)
}
))Esto conduce a un código más natural:
s <- Stack$new()
s$push(10)
s$push(20)
s$pop()
#> [1] 20Encontré un ejemplo de la vida real del estado de subprocesamiento en las escalas ggplot2. Las escalas son complejas porque necesitan combinar datos en cada faceta y cada capa. Originalmente usé clases S3, pero requería pasar datos de escala hacia y desde muchas funciones. Cambiar a R6 simplificó sustancialmente el código. Sin embargo, también introdujo algunos problemas porque olvidé llamar a $clone() al modificar un gráfico. Esto permitió que las parcelas independientes compartieran los mismos datos de escala, creando un error sutil que era difícil de rastrear.
16.3.3 Encadenamiento de métodos
La canalización, |>, es útil porque proporciona un operador infijo que facilita la composición de funciones de izquierda a derecha. Curiosamente, la tubería no es tan importante para los objetos R6 porque ya usan un operador infijo: $. Esto permite al usuario encadenar varias llamadas a métodos en una sola expresión, una técnica conocida como encadenamiento de métodos:
s <- Stack$new()
s$
push(10)$
push(20)$
pop()
#> [1] 20Esta técnica se usa comúnmente en otros lenguajes de programación, como Python y JavaScript, y es posible con una convención: cualquier método R6 que se llame principalmente por sus efectos secundarios (generalmente modificando el objeto) debe devolver invisible(self).
La principal ventaja del encadenamiento de métodos es que puede obtener un autocompletado útil; la desventaja principal es que solo el creador de la clase puede agregar nuevos métodos (y no hay forma de usar el envío múltiple).