12 Vectores lógicos
12.1 Introducción
En este capítulo, aprenderá herramientas para trabajar con vectores lógicos. Los vectores lógicos son el tipo de vector más simple porque cada elemento solo puede tener uno de tres valores posibles: TRUE, TRUE, FALSE, FALSE y faltante, NA. Es relativamente raro encontrar vectores lógicos en sus datos sin procesar, pero los creará y manipulará en el curso de casi todos los análisis.
Comenzaremos discutiendo la forma más común de crear vectores lógicos: con comparaciones numéricas. Luego, aprenderá cómo puede usar el álgebra booleana para combinar diferentes vectores lógicos, así como algunos resúmenes útiles. Terminaremos con if_else() y case_when(), dos funciones útiles para realizar cambios condicionales impulsados por vectores lógicos.
12.1.1 Requisitos previos
La mayoría de las funciones que aprenderá en este capítulo son proporcionadas por la base R, por lo que no necesitamos el tidyverse, pero igual lo cargaremos para poder usar mutate(), filter(), y amigos para trabajar con data frames. También continuaremos extrayendo ejemplos del conjunto de datos nycflights13::flights.
Sin embargo, a medida que empecemos a cubrir más herramientas, no siempre habrá un ejemplo real perfecto. Así que empezaremos a inventar algunos datos ficticios con c():
x <- c(1, 2, 3, 5, 7, 11, 13)
x * 2
#> [1] 2 4 6 10 14 22 26Esto facilita la explicación de funciones individuales a costa de dificultar ver cómo podría aplicarse a sus problemas de datos. Solo recuerda que cualquier manipulación que hagamos a un vector flotante, puedes hacerla a una variable dentro de un data frame con mutate() y amigos.
12.2 Comparaciones
Una forma muy común de crear un vector lógico es a través de una comparación numérica con <, <=, >, >=, != y ==. Hasta ahora, en su mayoría hemos creado variables lógicas de manera transitoria dentro de filter() — se calculan, usan y luego se descartan. Por ejemplo, el siguiente filtro encuentra todas las salidas diurnas que llegan aproximadamente a tiempo:
flights |>
filter(dep_time > 600 & dep_time < 2000 & abs(arr_delay) < 20)
#> # A tibble: 172,286 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 601 600 1 844 850
#> 2 2013 1 1 602 610 -8 812 820
#> 3 2013 1 1 602 605 -3 821 805
#> 4 2013 1 1 606 610 -4 858 910
#> 5 2013 1 1 606 610 -4 837 845
#> 6 2013 1 1 607 607 0 858 915
#> # ℹ 172,280 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …Es útil saber que este es un atajo y que puedes crear explícitamente las variables lógicas subyacentes con mutate():
flights |>
mutate(
daytime = dep_time > 600 & dep_time < 2000,
approx_ontime = abs(arr_delay) < 20,
.keep = "used"
)
#> # A tibble: 336,776 × 4
#> dep_time arr_delay daytime approx_ontime
#> <int> <dbl> <lgl> <lgl>
#> 1 517 11 FALSE TRUE
#> 2 533 20 FALSE FALSE
#> 3 542 33 FALSE FALSE
#> 4 544 -18 FALSE TRUE
#> 5 554 -25 FALSE FALSE
#> 6 554 12 FALSE TRUE
#> # ℹ 336,770 more rowsEsto es particularmente útil para la lógica más complicada porque nombrar los pasos intermedios facilita la lectura del código y la verificación de que cada paso se haya calculado correctamente.
Con todo, el filtro inicial es equivalente a:
12.2.1 Comparación de punto flotante
Cuidado con usar == con números. Por ejemplo, parece que este vector contiene los números 1 y 2:
Pero si los prueba para la igualdad, obtiene FALSE, FALSE:
x == c(1, 2)
#> [1] FALSE FALSE¿Qué está sucediendo? Las computadoras almacenan números con un número fijo de posiciones decimales, por lo que no hay forma de representar exactamente 1/49 o sqrt(2) y los cálculos subsiguientes estarán ligeramente desviados. Podemos ver los valores exactos llamando a print() con el argumento digits1:
print(x, digits = 16)
#> [1] 0.9999999999999999 2.0000000000000004Puede ver por qué R por defecto redondea estos números; realmente están muy cerca de lo que esperas.
Ahora que ha visto por qué == está fallando, ¿qué puede hacer al respecto? Una opción es usar dplyr::near() que ignora las pequeñas diferencias:
12.2.2 Valores faltantes
Los valores faltantes representan lo desconocido, por lo que son “contagiosos”: casi cualquier operación que involucre un valor desconocido también será desconocida:
NA > 5
#> [1] NA
10 == NA
#> [1] NAEl resultado más confuso es este:
NA == NA
#> [1] NAEs más fácil entender por qué esto es cierto si proporcionamos artificialmente un poco más de contexto:
# No sabemos cuántos años tiene María.
edad_maria <- NA
# No sabemos cuántos años tiene Juan.
edad_juan <- NA
# ¿María y Juan tienen la misma edad?
edad_maria == edad_juan
#> [1] NA
# ¡No sabemos!Entonces, si desea encontrar todos los vuelos en los que falta dep_time, el siguiente código no funciona porque dep_time == NA generará NA para cada fila, y filter() elimina automáticamente los valores faltantes:
flights |>
filter(dep_time == NA)
#> # A tibble: 0 × 19
#> # ℹ 19 variables: year <int>, month <int>, day <int>, dep_time <int>,
#> # sched_dep_time <int>, dep_delay <dbl>, arr_time <int>, …En su lugar, necesitaremos una nueva herramienta: is.na().
12.2.3 is.na()
is.na(x) funciona con cualquier tipo de vector y devuelve TRUE, TRUE, para los valores faltantes y FALSE, FALSE, para todo lo demás:
Podemos usar is.na() para encontrar todas las filas a las que les falta dep_time:
flights |>
filter(is.na(dep_time))
#> # A tibble: 8,255 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 NA 1630 NA NA 1815
#> 2 2013 1 1 NA 1935 NA NA 2240
#> 3 2013 1 1 NA 1500 NA NA 1825
#> 4 2013 1 1 NA 600 NA NA 901
#> 5 2013 1 2 NA 1540 NA NA 1747
#> 6 2013 1 2 NA 1620 NA NA 1746
#> # ℹ 8,249 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …is.na() también puede ser útil en arrange(). arrange() generalmente coloca todos los valores faltantes al final, pero puede anular este valor predeterminado ordenando primero por is.na():
flights |>
filter(month == 1, day == 1) |>
arrange(dep_time)
#> # A tibble: 842 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 517 515 2 830 819
#> 2 2013 1 1 533 529 4 850 830
#> 3 2013 1 1 542 540 2 923 850
#> 4 2013 1 1 544 545 -1 1004 1022
#> 5 2013 1 1 554 600 -6 812 837
#> 6 2013 1 1 554 558 -4 740 728
#> # ℹ 836 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …
flights |>
filter(month == 1, day == 1) |>
arrange(desc(is.na(dep_time)), dep_time)
#> # A tibble: 842 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 NA 1630 NA NA 1815
#> 2 2013 1 1 NA 1935 NA NA 2240
#> 3 2013 1 1 NA 1500 NA NA 1825
#> 4 2013 1 1 NA 600 NA NA 901
#> 5 2013 1 1 517 515 2 830 819
#> 6 2013 1 1 533 529 4 850 830
#> # ℹ 836 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …Volveremos para cubrir los valores faltantes con más profundidad en Capítulo 18.
12.2.4 Ejercicios
- ¿Cómo funciona
dplyr::near()? Escribenearpara ver el código fuente. ¿Essqrt(2)^2cerca de 2? - Use
mutate(),is.na()ycount()juntos para describir cómo se conectan los valores que faltan endep_time,sched_dep_timeydep_delay.
12.3 Álgebra booleana
Una vez que tenga varios vectores lógicos, puede combinarlos usando álgebra booleana. En R, & es “y”, | es “o”, ! es “no”, y xor() es exclusivo o 2. Por ejemplo, df |> filter(!is.na(x)) encuentra todas las filas donde no falta x y df |> filter(x < -10 | x > 0) encuentra todas las filas donde x es menor que -10 o mayor que 0. Figura 12.1 muestra el conjunto completo de operaciones booleanas y cómo funcionan.
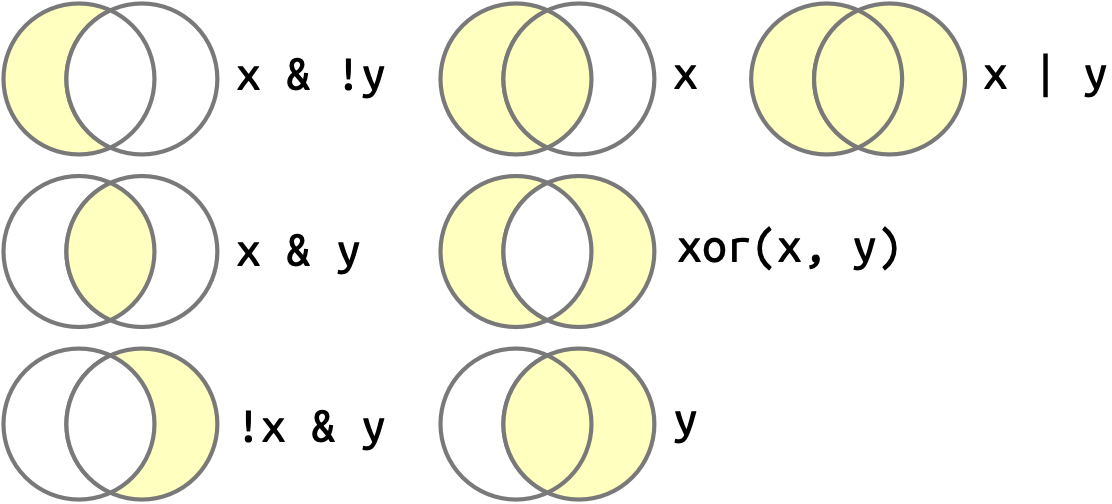
x es el círculo a la izquierda, y es el círculo de la derecha, y la región sombreada muestra qué partes selecciona cada operador.
Además de & y |, R también tiene && y ||. ¡No los use en funciones dplyr! Estos se denominan operadores de cortocircuito y solo devuelven un solo TRUE o FALSE. Son importantes para la programación, no para la ciencia de datos.
12.3.1 Valores Faltantes
Las reglas para los valores faltantes en el álgebra booleana son un poco difíciles de explicar porque parecen inconsistentes a primera vista:
Para entender lo que está pasando, piense en NA | TRUE (NA o TRUE). Un valor faltante en un vector lógico significa que el valor podría ser TRUE o FALSE. TRUE | TRUE y FALSE | TRUE son ambos TRUE porque al menos uno de ellos es TRUE. NA | TRUE también debe ser TRUE porque NA puede ser TRUE o FALSE. Sin embargo NA | FALSE es FALSE porque NA puede ser TRUE o FALSE Se aplica un razonamiento similar con NA & FALSE.
12.3.2 Orden de operaciones
Tenga en cuenta que el orden de las operaciones no funciona como en inglés. Tome el siguiente código que encuentra todos los vuelos que salieron en noviembre o diciembre:
flights |>
filter(month == 11 | month == 12)Es posible que tenga la tentación de escribirlo como diría en inglés: “Buscar todos los vuelos que partieron en noviembre o diciembre”.:
flights |>
filter(month == 11 | 12)
#> # A tibble: 336,776 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 517 515 2 830 819
#> 2 2013 1 1 533 529 4 850 830
#> 3 2013 1 1 542 540 2 923 850
#> 4 2013 1 1 544 545 -1 1004 1022
#> 5 2013 1 1 554 600 -6 812 837
#> 6 2013 1 1 554 558 -4 740 728
#> # ℹ 336,770 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …Este código no da error, pero tampoco parece haber funcionado. ¿Qué está sucediendo? Aquí, R primero evalúa month == 11 creando un vector lógico, al que llamamos nov. Calcula nov | 12. Cuando usa un número con un operador lógico, convierte todo menos 0 en TRUE, por lo que esto es equivalente a nov | TRUE que siempre será TRUE, por lo que se seleccionarán todas las filas:
flights |>
mutate(
nov = month == 11,
final = nov | 12,
.keep = "used"
)
#> # A tibble: 336,776 × 3
#> month nov final
#> <int> <lgl> <lgl>
#> 1 1 FALSE TRUE
#> 2 1 FALSE TRUE
#> 3 1 FALSE TRUE
#> 4 1 FALSE TRUE
#> 5 1 FALSE TRUE
#> 6 1 FALSE TRUE
#> # ℹ 336,770 more rows
12.3.3 %in%
Una manera fácil de evitar el problema de poner tus ==s y |s en el orden correcto es usar %in%. x %in% y devuelve un vector lógico de la misma longitud que x que es TRUE cada vez que un valor en x está en cualquier parte de y.
Entonces, para encontrar todos los vuelos en noviembre y diciembre, podríamos escribir:
Tenga en cuenta que %in% obedece reglas diferentes para NA y ==, ya que NA %in% NA es TRUE.
Esto puede ser un atajo útil:
flights |>
filter(dep_time %in% c(NA, 0800))
#> # A tibble: 8,803 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 800 800 0 1022 1014
#> 2 2013 1 1 800 810 -10 949 955
#> 3 2013 1 1 NA 1630 NA NA 1815
#> 4 2013 1 1 NA 1935 NA NA 2240
#> 5 2013 1 1 NA 1500 NA NA 1825
#> 6 2013 1 1 NA 600 NA NA 901
#> # ℹ 8,797 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …12.3.4 Ejercicios
- Encuentre todos los vuelos en los que falte
arr_delaypero nodep_delay. Encuentre todos los vuelos en los que no falten niarr_timenisched_arr_time, pero síarr_delay. - ¿A cuántos vuelos les falta
dep_time? ¿Qué otras variables faltan en estas filas? ¿Qué podrían representar estas filas? - Suponiendo que la falta de
dep_timeimplica que se canceló un vuelo, mire la cantidad de vuelos cancelados por día. ¿Hay un patrón? ¿Existe una conexión entre la proporción de vuelos cancelados y el retraso promedio de los vuelos no cancelados?
12.4 Resúmenes
Las siguientes secciones describen algunas técnicas útiles para resumir vectores lógicos. Además de funciones que solo funcionan específicamente con vectores lógicos, también puede usar funciones que funcionan con vectores numéricos.
12.4.1 Resúmenes lógicos
Hay dos resúmenes lógicos principales: any() y all(). any(x) es el equivalente de |; devolverá TRUE si hay algún TRUE en x. all(x) es equivalente a &; devolverá TRUE solo si todos los valores de x son TRUE. Como casi todas las funciones de resumen, puede hacer que los valores faltantes desaparezcan con na.rm = TRUE.
Por ejemplo, podríamos usar all() y any() para averiguar si todos los vuelos se retrasaron a la salida como máximo una hora o si algún vuelo se retrasó a la llegada cinco horas o más. Y usar group_by() nos permite hacer eso por día:
flights |>
group_by(year, month, day) |>
summarize(
all_delayed = all(dep_delay <= 60, na.rm = TRUE),
any_long_delay = any(arr_delay >= 300, na.rm = TRUE),
.groups = "drop"
)
#> # A tibble: 365 × 5
#> year month day all_delayed any_long_delay
#> <int> <int> <int> <lgl> <lgl>
#> 1 2013 1 1 FALSE TRUE
#> 2 2013 1 2 FALSE TRUE
#> 3 2013 1 3 FALSE FALSE
#> 4 2013 1 4 FALSE FALSE
#> 5 2013 1 5 FALSE TRUE
#> 6 2013 1 6 FALSE FALSE
#> # ℹ 359 more rowsEn la mayoría de los casos, sin embargo, any() y all() son un poco toscos, y sería bueno poder obtener un poco más de detalles sobre cuántos valores son TRUE o FALSE. Eso nos lleva a los resúmenes numéricos.
12.4.2 Resúmenes numéricos de vectores lógicos
Cuando usa un vector lógico en un contexto numérico, TRUE se convierte en 1 y FALSE se convierte en 0. Esto hace que sum() y mean() sean muy útiles con vectores lógicos porque sum(x) da el número de TRUEs y mean(x) da la proporción de TRUEs (porque mean() es simplemente sum() dividido por length()).
Eso, por ejemplo, nos permite ver la proporción de vuelos que se retrasaron a la salida como máximo una hora y la cantidad de vuelos que se retrasaron a la llegada cinco horas o más:
flights |>
group_by(year, month, day) |>
summarize(
proportion_delayed = mean(dep_delay <= 60, na.rm = TRUE),
count_long_delay = sum(arr_delay >= 300, na.rm = TRUE),
.groups = "drop"
)
#> # A tibble: 365 × 5
#> year month day proportion_delayed count_long_delay
#> <int> <int> <int> <dbl> <int>
#> 1 2013 1 1 0.939 3
#> 2 2013 1 2 0.914 3
#> 3 2013 1 3 0.941 0
#> 4 2013 1 4 0.953 0
#> 5 2013 1 5 0.964 1
#> 6 2013 1 6 0.959 0
#> # ℹ 359 more rows12.4.3 Subconjunto lógico
Hay un uso final para los vectores lógicos en los resúmenes: puede usar un vector lógico para filtrar una sola variable a un subconjunto de interés. Esto hace uso del operador base [ (subconjunto pronunciado), sobre el que obtendrá más información en Sección 27.2.
Imagine que quisiéramos ver el retraso promedio solo para los vuelos que realmente se retrasaron. Una forma de hacerlo sería filtrar primero los vuelos y luego calcular el retraso promedio:
flights |>
filter(arr_delay > 0) |>
group_by(year, month, day) |>
summarize(
behind = mean(arr_delay),
n = n(),
.groups = "drop"
)
#> # A tibble: 365 × 5
#> year month day behind n
#> <int> <int> <int> <dbl> <int>
#> 1 2013 1 1 32.5 461
#> 2 2013 1 2 32.0 535
#> 3 2013 1 3 27.7 460
#> 4 2013 1 4 28.3 297
#> 5 2013 1 5 22.6 238
#> 6 2013 1 6 24.4 381
#> # ℹ 359 more rowsEsto funciona, pero ¿y si también quisiéramos calcular el retraso promedio de los vuelos que llegaron temprano? Tendríamos que realizar un paso de filtro por separado y luego descubrir cómo combinar los dos marcos de datos juntos [^ lógicos-3]. En su lugar, podría usar [ para realizar un filtrado en línea: arr_delay[arr_delay > 0] generará solo los retrasos de llegada positivos.
Esto lleva a:
flights |>
group_by(year, month, day) |>
summarize(
behind = mean(arr_delay[arr_delay > 0], na.rm = TRUE),
ahead = mean(arr_delay[arr_delay < 0], na.rm = TRUE),
n = n(),
.groups = "drop"
)
#> # A tibble: 365 × 6
#> year month day behind ahead n
#> <int> <int> <int> <dbl> <dbl> <int>
#> 1 2013 1 1 32.5 -12.5 842
#> 2 2013 1 2 32.0 -14.3 943
#> 3 2013 1 3 27.7 -18.2 914
#> 4 2013 1 4 28.3 -17.0 915
#> 5 2013 1 5 22.6 -14.0 720
#> 6 2013 1 6 24.4 -13.6 832
#> # ℹ 359 more rowsTambién tenga en cuenta la diferencia en el tamaño del grupo: en el primer fragmento n() da el número de vuelos retrasados por día; en el segundo, n() da el número total de vuelos.
12.4.4 Ejercicios
- ¿Qué te dirá
sum(is.na(x))? ¿Qué talmean(is.na(x))? - ¿Qué devuelve
prod()cuando se aplica a un vector lógico? ¿A qué función de resumen lógico es equivalente? ¿Qué devuelvemin()cuando se aplica a un vector lógico? ¿A qué función de resumen lógico es equivalente? Lea la documentación y realice algunos experimentos.
12.5 Transformaciones condicionales
Una de las características más poderosas de los vectores lógicos es su uso para transformaciones condicionales, es decir, hacer una cosa para la condición x y algo diferente para la condición y. Hay dos herramientas importantes para esto: if_else() y case_when().
12.5.1 if_else()
Si quiere usar un valor cuando una condición es TRUE y otro valor cuando es FALSE, puede usar dplyr::if_else()3. Siempre usarás los tres primeros argumentos de if_else(). El primer argumento, condition, es un vector lógico, el segundo, true, da la salida cuando la condición es verdadera, y el tercero, false, da la salida si la condición es falsa.
Comencemos con un ejemplo simple de etiquetar un vector numérico como “+ve” (positivo) o “-ve” (negativo):
Hay un cuarto argumento opcional, missing que se usará si la entrada es NA:
if_else(x > 0, "+ve", "-ve", "???")
#> [1] "-ve" "-ve" "-ve" "-ve" "+ve" "+ve" "+ve" "???"También puede usar vectores para los argumentos true y false. Por ejemplo, esto nos permite crear una implementación mínima de abs():
if_else(x < 0, -x, x)
#> [1] 3 2 1 0 1 2 3 NAHasta ahora, todos los argumentos han usado los mismos vectores, pero, por supuesto, puede mezclarlos y combinarlos. Por ejemplo, podría implementar una versión simple de coalesce() como esta:
Es posible que haya notado una pequeña infelicidad en nuestro ejemplo de etiquetado anterior: cero no es ni positivo ni negativo. Podríamos resolver esto agregando un if_else() adicional:
Esto ya es un poco difícil de leer, y puedes imaginar que solo sería más difícil si tuvieras más condiciones. En su lugar, puede cambiar a dplyr::case_when().
12.5.2 case_when()
case_when() de dplyr está inspirado en la declaración CASE de SQL y proporciona una forma flexible de realizar diferentes cálculos para diferentes condiciones. Tiene una sintaxis especial que, lamentablemente, no se parece a nada que vayas a usar en tidyverse. Toma pares que parecen condition ~ output. condition debe ser un vector lógico; cuando es TRUE, se usará output.
Esto significa que podríamos recrear nuestro anterior if_else() anidado de la siguiente manera:
Esto es más código, pero también es más explícito.
Para explicar cómo funciona case_when(), exploremos algunos casos más simples. Si ninguno de los casos coincide, la salida obtiene un NA:
case_when(
x < 0 ~ "-ve",
x > 0 ~ "+ve"
)
#> [1] "-ve" "-ve" "-ve" NA "+ve" "+ve" "+ve" NAUse .default si desea crear un valor catch all “predeterminado”:
case_when(
x < 0 ~ "-ve",
x > 0 ~ "+ve",
.default = "???"
)
#> [1] "-ve" "-ve" "-ve" "???" "+ve" "+ve" "+ve" "???"Y tenga en cuenta que si coinciden varias condiciones, solo se utilizará la primera:
case_when(
x > 0 ~ "+ve",
x > 2 ~ "big"
)
#> [1] NA NA NA NA "+ve" "+ve" "+ve" NAAl igual que con if_else(), puede usar variables en ambos lados de ~ y puede mezclar y combinar variables según sea necesario para su problema. Por ejemplo, podríamos usar case_when() para proporcionar algunas etiquetas legibles por humanos para el retraso de llegada:
flights |>
mutate(
status = case_when(
is.na(arr_delay) ~ "cancelado",
arr_delay < -30 ~ "muy temprano",
arr_delay < -15 ~ "temprano",
abs(arr_delay) <= 15 ~ "a tiempo",
arr_delay < 60 ~ "tarde",
arr_delay < Inf ~ "muy tarde",
),
.keep = "used"
)
#> # A tibble: 336,776 × 2
#> arr_delay status
#> <dbl> <chr>
#> 1 11 a tiempo
#> 2 20 tarde
#> 3 33 tarde
#> 4 -18 temprano
#> 5 -25 temprano
#> 6 12 a tiempo
#> # ℹ 336,770 more rowsTenga cuidado al escribir este tipo de declaraciones complejas case_when(); mis primeros dos intentos usaron una combinación de < y > y seguí creando accidentalmente condiciones superpuestas.
12.5.3 Tipos compatibles
Tenga en cuenta que tanto if_else() como case_when() requieren tipos compatibles en la salida. Si no son compatibles, verá errores como este:
En general, relativamente pocos tipos son compatibles, porque la conversión automática de un tipo de vector a otro es una fuente común de errores. Estos son los casos más importantes que son compatibles:
- Los vectores numéricos y lógicos son compatibles, como discutimos en Sección 12.4.2.
- Las cadenas y los factores (Capítulo 16) son compatibles, porque puede pensar en un factor como una cadena con un conjunto restringido de valores.
- Las fechas y las fechas y horas, de las que hablaremos en Capítulo 17, son compatibles porque puede pensar en una fecha como un caso especial de fecha y hora.
-
NA, que técnicamente es un vector lógico, es compatible con todo porque cada vector tiene alguna forma de representar un valor faltante.
No esperamos que memorices estas reglas, pero deberían convertirse en una segunda naturaleza con el tiempo porque se aplican de manera consistente en todo el tidyverse.
12.5.4 Ejercicios
Un número es par si es divisible por dos, lo cual en R puedes averiguar con
x %% 2 == 0. Usa este hecho yif_else()para determinar si cada número entre 0 y 20 es par o impar.Dado un vector de días como
x <- c("Lunes", "Sábado", "Miércoles"), use una instrucciónif_else()para etiquetarlos como fines de semana o días de semana.Usa
if_else()para calcular el valor absoluto de un vector numérico llamadox.Escriba una instrucción
case_when()que use las columnasmonthydaydeflightspara etiquetar una selección de días festivos importantes de EE. UU. (por ejemplo, Año Nuevo, 4 de julio, Acción de Gracias y Navidad). Primero cree una columna lógica que seaTRUEoFALSE, y luego cree una columna de caracteres que dé el nombre de la festividad o seaNA.
12.6 Resumen
La definición de un vector lógico es simple porque cada valor debe ser TRUE, FALSE o NA. Pero los vectores lógicos proporcionan una gran cantidad de posibilidades. En este capítulo, aprendió a crear vectores lógicos con >, <, <=, >=, ==, != y is.na(), cómo combinarlos con !, & y |, y cómo resumirlos con any(), all(), sum() y mean(). También aprendiste las poderosas funciones if_else() y case_when() que te permiten devolver valores dependiendo del valor de un vector lógico.
Veremos vectores lógicos una y otra vez en los siguientes capítulos. Por ejemplo, en Capítulo 14 aprenderá sobre str_detect(x, pattern) que devuelve un vector lógico que es TRUE para los elementos de x que coinciden con el patrón, pattern, y en Capítulo 17 creará vectores lógicos a partir de la comparación de fechas y horas. Pero por ahora, vamos a pasar al siguiente tipo de vector más importante: los vectores numéricos.
R normalmente llama a print por usted (es decir,
xes un atajo paraprint(x)), pero llamarlo explícitamente es útil si desea proporcionar otros argumentos.↩︎Es decir,
xor(x, y)es TRUE si x es TRUE, o y es TRUE, pero no ambos. Así es como solemos usar “o” en inglés. “Ambos” no suele ser una respuesta aceptable a la pregunta “¿quieres un helado o un pastel?”.↩︎El
if_else()de dplyr es muy similar alifelse()de base R. Hay dos ventajas principales deif_else()sobreifelse(): puede elegir qué debería pasar con los valores faltantes, y es mucho más probable queif_else()le dé un error significativo si sus variables tienen tipos incompatibles.↩︎