24 Web scraping
24.1 Introducción
Este capítulo le presenta los conceptos básicos del web scraping con rvest. El web scraping es una herramienta muy útil para extraer datos de páginas web. Algunos sitios web ofrecerán una API, un conjunto de solicitudes HTTP estructuradas que devuelven datos como JSON, que usted maneja utilizando las técnicas de Capítulo 23. Siempre que sea posible, debe utilizar la API1, ya que, por lo general, le brindará datos más confiables. Desafortunadamente, sin embargo, la programación con API web está fuera del alcance de este libro. En cambio, estamos enseñando scraping, una técnica que funciona ya sea que un sitio proporcione o no una API.
En este capítulo, primero discutiremos la ética y la legalidad del scraping antes de sumergirnos en los conceptos básicos de HTML. Luego, aprenderá los conceptos básicos de los selectores de CSS para ubicar elementos específicos en la página y cómo usar funciones rvest para obtener datos de texto y atributos de HTML y en R. Luego discutiremos algunas técnicas para descubrir qué selector de CSS necesita para la página de la que desee extraer los datos, antes de terminar verá un par de casos de estudio y una breve discusión de sitios web dinámicos.
24.1.1 Requisitos previos
En este capítulo, nos centraremos en las herramientas proporcionadas por rvest. rvest es miembro de tidyverse, pero no es un miembro central, por lo que deberá cargarlo explícitamente. También cargaremos el tidyverse completo, ya que lo encontraremos generalmente útil para trabajar con los datos que hemos recopilado.
24.2 Scraping éticas y legalidades
Antes de comenzar a analizar el código que necesitará para realizar el web scraping, debemos analizar si es legal y ético que lo haga. En general, la situación es complicada con respecto a ambos.
La legalidad depende mucho del lugar donde vivas. Sin embargo, como principio general, si los datos son públicos, no personales y fácticos, es probable que esté bien 2. Estos tres factores son importantes porque están relacionados con los términos y condiciones del sitio, la información de identificación personal y los derechos de autor, como veremos a continuación.
Si los datos no son públicos, no personales o fácticos, o si los extrae específicamente para ganar dinero con ellos, deberá hablar con un abogado. En cualquier caso, debe ser respetuoso con los recursos del servidor que aloja las páginas de las que está haciendo scraping. Lo que es más importante, esto significa que si está extrayendo datos de muchas páginas, debe asegurarse de esperar un poco entre cada solicitud. Una forma fácil de hacerlo es usar el paquete polite de Dmytro Perepolkin. Se pausará automáticamente entre las solicitudes y almacenará en caché los resultados para que nunca solicite la misma página dos veces.
24.2.1 Términos de servicio
Si observa detenidamente, encontrará que muchos sitios web incluyen un enlace de “términos y condiciones” o “términos de servicio” en algún lugar de la página, y si lee esa página detenidamente, a menudo descubrirá que el sitio prohíbe específicamente el web scraping. Estas páginas tienden a ser una apropiación legal de tierras donde las empresas hacen reclamos muy amplios. Es educado respetar estos términos de servicio siempre que sea posible, pero tome cualquier reclamo con pinzas.
Los tribunales de EE. UU. generalmente han determinado que simplemente poner los términos de servicio en el pie de página del sitio web no es suficiente para que usted esté sujeto a ellos, por ejemplo, [HiQ Labs v. LinkedIn] (https://en.wikipedia.org/ wiki/HiQ_Labs_v._LinkedIn). En general, para estar sujeto a los términos del servicio, debe haber realizado alguna acción explícita, como crear una cuenta o marcar una casilla. Por eso es importante si los datos son públicos o no; si no necesita una cuenta para acceder a ellos, es poco probable que esté sujeto a los términos del servicio. Tenga en cuenta, sin embargo, que la situación es bastante diferente en Europa, donde los tribunales han determinado que los términos de servicio son exigibles incluso si no los acepta explícitamente.
24.2.2 Información de identificación personal
Incluso si los datos son públicos, debe tener mucho cuidado al recopilar información de identificación personal, como nombres, direcciones de correo electrónico, números de teléfono, fechas de nacimiento, etc. Europa tiene leyes particularmente estrictas sobre la recopilación o el almacenamiento de dichos datos (GDPR), e independientemente de dónde viva, es probable que esté entrando en un atolladero ético. Por ejemplo, en 2016, un grupo de investigadores recopiló información de perfil público (por ejemplo, nombres de usuario, edad, sexo, ubicación, etc.) de unas 70 000 personas en el sitio de citas OkCupid y publicaron estos datos sin intentar anonimizarlos. Si bien los investigadores sintieron que esto no tenía nada de malo ya que los datos ya eran públicos, este trabajo fue ampliamente condenado debido a preocupaciones éticas sobre la identificabilidad de los usuarios cuya información se publicó en el conjunto de datos. Si su trabajo consiste en recopilar información de identificación personal, le recomendamos leer sobre el estudio OkCupid3, así como estudios similares con ética de investigación cuestionable que involucran la adquisición y divulgación de información de identificación personal.
24.2.3 Derechos de autor
Finalmente, también debe preocuparse por la ley de derechos de autor. La ley de derechos de autor es complicada, pero vale la pena echar un vistazo a la [ley de EE. UU.] (https://www.law.cornell.edu/uscode/text/17/102) que describe exactamente lo que está protegido: “[… ] obras originales de autoría fijadas en cualquier medio tangible de expresión, […]”. Luego pasa a describir categorías específicas que aplica, como obras literarias, obras musicales, películas y más. Los datos están notablemente ausentes de la protección de los derechos de autor. Esto significa que mientras limite su extracción a datos, la protección de derechos de autor no se aplica. (Pero tenga en cuenta que Europa tiene un derecho “sui generis” separado que protege las bases de datos).
Como un breve ejemplo, en los EE. UU., las listas de ingredientes y las instrucciones no tienen derechos de autor, por lo que los derechos de autor no se pueden usar para proteger una receta. Pero si esa lista de recetas va acompañada de un contenido literario novedoso sustancial, eso tiene derechos de autor. Por eso, cuando buscas una receta en Internet, siempre hay mucho contenido de antemano.
Si necesita extraer contenido original (como texto o imágenes), aún puede estar protegido por la [doctrina de uso justo] (https://en.wikipedia.org/wiki/Fair_use). El uso justo no es una regla estricta y rápida, pero sopesa una serie de factores. Es más probable que se aplique si está recopilando los datos con fines de investigación o no comerciales y si limita lo que extrae a solo lo que necesita.
24.3 HTML básico
Para hacer web scraping, primero debe comprender un poco sobre HTML, el lenguaje que describe las páginas web. HTML significa HyperText Markup Lidioma y se parece a esto:
<html>
<head>
<title>Page title</title>
</head>
<body>
<h1 id='first'>A heading</h1>
<p>Some text & <b>some bold text.</b></p>
<img src='myimg.png' width='100' height='100'>
</body>HTML tiene una estructura jerárquica formada por elementos que consisten en una etiqueta de inicio (por ejemplo, <etiqueta>), atributos opcionales (id='primero'), una etiqueta final[^webscraping- 5] (como </etiqueta>) y contenido (todo lo que se encuentra entre la etiqueta de inicio y final).
Dado que < y > se utilizan para las etiquetas de inicio y finalización, no puede escribirlas directamente. En su lugar, debe utilizar los escapes de HTML > (mayor que) y < (menor que). Y dado que esos escapes usan &, si quieres un ampersand literal, tienes que escapar como &. Hay una amplia gama de posibles escapes de HTML, pero no necesita preocuparse demasiado por ellos porque rvest los maneja automáticamente por usted.
Web scraping es posible porque la mayoría de las páginas que contienen datos que desea extraer generalmente tienen una estructura consistente.
24.3.1 Elementos
Hay más de 100 elementos HTML. Algunos de los más importantes son:
Cada página HTML debe estar en un elemento
<html>y debe tener dos elementos secundarios:<head>, que contiene metadatos del documento como el título de la página, y<body>, que contiene el contenido que ve en el navegador.Las etiquetas de bloque como
<h1>(título 1),<section>(sección),<p>(párrafo) y<ol>(lista ordenada) forman la estructura general de la página.Las etiquetas en línea como
<b>(negrita),<i>(cursiva) y<a>(enlace) dan formato al texto dentro de las etiquetas de bloque.
Si encuentra una etiqueta que nunca ha visto antes, puede averiguar qué hace con un poco de google. Otro buen lugar para comenzar son los MDN Web Docs que describen casi todos los aspectos de la programación web.
La mayoría de los elementos pueden tener contenido entre sus etiquetas de inicio y fin. Este contenido puede ser texto o más elementos. Por ejemplo, el siguiente HTML contiene un párrafo de texto, con una palabra en negrita.
<p>
¡Hola! Mi <b>nombre</b> es Hadley.
</p>Los hijos son los elementos que contiene, por lo que el elemento <p> de arriba tiene un hijo, el elemento <b>. El elemento <b> no tiene hijos, pero sí tiene contenidos (el texto “nombre”).
24.3.2 Atributos
Las etiquetas pueden tener atributos con nombre que se parecen a name1='value1' name2='value2'. Dos de los atributos más importantes son id y class, que se utilizan junto con CSS (hojas de estilo en cascada) para controlar la apariencia visual de la página. Suelen ser útiles cuando se extraen datos de una página. Los atributos también se utilizan para registrar el destino de los enlaces (el atributo href de los elementos <a>) y la fuente de las imágenes (el atributo src del elemento <img>).
24.4 Extrayendo datos
Para comenzar a extraer, necesitará la URL de la página que desea, que generalmente puede copiar desde su navegador web. Luego deberá leer el HTML de esa página en R con read_html(). Esto devuelve un objeto xml_document4 que luego manipularás usando las funciones rvest:
html <- read_html("http://rvest.tidyverse.org/")
html
#> {html_document}
#> <html lang="en">
#> [1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UT ...
#> [2] <body>\n <a href="#container" class="visually-hidden-focusable">Ski ...rvest también incluye una función que te permite escribir HTML en línea. Usaremos esto un montón en este capítulo mientras enseñamos cómo funcionan las diversas funciones rvest con ejemplos simples.
html <- minimal_html("
<p>Esto es un párrafo</p>
<ul>
<li>Esta es una lista con viñetas</li>
</ul>
")
html
#> {html_document}
#> <html>
#> [1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UT ...
#> [2] <body>\n<p>Esto es un párrafo</p>\n <ul>\n<li>Esta es una lista con v ...Ahora que tiene el HTML en R, es hora de extraer los datos de interés. Primero aprenderá sobre los selectores de CSS que le permiten identificar los elementos de interés y las funciones rvest que puede usar para extraer datos de ellos. Luego cubriremos brevemente las tablas HTML, que tienen algunas herramientas especiales.
24.4.1 Buscar elementos
CSS es la abreviatura de hojas de estilo en cascada y es una herramienta para definir el estilo visual de los documentos HTML. CSS incluye un lenguaje en miniatura para seleccionar elementos en una página llamado selectores de CSS. Los selectores de CSS definen patrones para ubicar elementos HTML y son útiles para la extracción de datos porque brindan una forma concisa de describir qué elementos desea extraer.
Volveremos a los selectores de CSS con más detalle en Sección 24.5, pero afortunadamente puedes recorrer un largo camino con solo tres:
pselecciona todos los elementos<p>..titleselecciona todos los elementos con clase,class, que equivale a “title”.#titleselecciona el elemento con el atributoidque equivale a “title”. Los atributos de identificación deben ser únicos dentro de un documento, por lo que esto solo seleccionará un solo elemento.
Probemos estos selectores con un ejemplo simple:
html <- minimal_html("
<h1>Este es un encabezado</h1>
<p id='first'>Esto es un párrafo</p>
<p class='important'>Este es un párrafo importante</p>
")Usa html_elements() para encontrar todos los elementos que coincidan con el selector:
html |> html_elements("p")
#> {xml_nodeset (2)}
#> [1] <p id="first">Esto es un párrafo</p>
#> [2] <p class="important">Este es un párrafo importante</p>
html |> html_elements(".important")
#> {xml_nodeset (1)}
#> [1] <p class="important">Este es un párrafo importante</p>
html |> html_elements("#first")
#> {xml_nodeset (1)}
#> [1] <p id="first">Esto es un párrafo</p>Otra función importante es html_element() que siempre devuelve el mismo número de salidas que de entradas. Si lo aplica a un documento completo, obtendrá la primera coincidencia:
html |> html_element("p")
#> {html_node}
#> <p id="first">Hay una diferencia importante entre html_element() y html_elements() cuando usas un selector que no coincide con ningún elemento. html_elements() devuelve un vector de longitud 0, donde html_element() devuelve un valor faltante. Esto será importante en breve.
html |> html_elements("b")
#> {xml_nodeset (0)}
html |> html_element("b")
#> {xml_missing}
#> <NA>24.4.2 Anidar selecciones
En la mayoría de los casos, usará html_elements() y html_element() juntos, generalmente usando html_elements() para identificar elementos que se convertirán en observaciones y luego usará html_element() para encontrar elementos que se convertirán en variables. Veamos esto en acción usando un ejemplo simple. Aquí tenemos una lista desordenada (<ul>) donde cada elemento de la lista (<li>) contiene información sobre cuatro personajes de StarWars:
html <- minimal_html("
<ul>
<li><b>C-3PO</b> es un <i>androide</i> que pesa <span class='weight'>167 kg</span></li>
<li><b>R4-P17</b> es un <i>androide</i></li>
<li><b>R2-D2</b> es un <i>androide</i> que pesa <span class='weight'>96 kg</span></li>
<li><b>Yoda</b> pesa <span class='weight'>66 kg</span></li>
</ul>
")Podemos usar html_elements() para hacer un vector donde cada elemento corresponde a un carácter diferente:
characters <- html |> html_elements("li")
characters
#> {xml_nodeset (4)}
#> [1] <li>\n<b>C-3PO</b> es un <i>androide</i> que pesa <span class="weight" ...
#> [2] <li>\n<b>R4-P17</b> es un <i>androide</i>\n</li>
#> [3] <li>\n<b>R2-D2</b> es un <i>androide</i> que pesa <span class="weight" ...
#> [4] <li>\n<b>Yoda</b> pesa <span class="weight">66 kg</span>\n</li>Para extraer el nombre de cada carácter, usamos html_element(), porque cuando se aplica a la salida de html_elements() se garantiza que devolverá una respuesta por elemento:
characters |> html_element("b")
#> {xml_nodeset (4)}
#> [1] <b>C-3PO</b>
#> [2] <b>R4-P17</b>
#> [3] <b>R2-D2</b>
#> [4] <b>Yoda</b>La distinción entre html_element() y html_elements() no es importante para el nombre, pero sí lo es para el peso. Queremos obtener un peso para cada carácter, incluso si no hay peso <span>. Eso es lo que hace html_element():
characters |> html_element(".weight")
#> {xml_nodeset (4)}
#> [1] <span class="weight">167 kg</span>
#> [2] NA
#> [3] <span class="weight">96 kg</span>
#> [4] <span class="weight">66 kg</span>html_elements() encuentra todos los <span> de peso que son hijos de characters. Solo hay tres de estos, por lo que perdemos la conexión entre nombres y pesos:
characters |> html_elements(".weight")
#> {xml_nodeset (3)}
#> [1] <span class="weight">167 kg</span>
#> [2] <span class="weight">96 kg</span>
#> [3] <span class="weight">66 kg</span>Ahora que ha seleccionado los elementos de interés, deberá extraer los datos, ya sea del contenido del texto o de algunos atributos.
24.4.3 Texto y atributos
html_text2()5 extrae el contenido de texto sin formato de un elemento HTML:
characters |>
html_element("b") |>
html_text2()
#> [1] "C-3PO" "R4-P17" "R2-D2" "Yoda"
characters |>
html_element(".weight") |>
html_text2()
#> [1] "167 kg" NA "96 kg" "66 kg"Tenga en cuenta que cualquier escape se manejará automáticamente; solo verá escapes de HTML en el HTML de origen, no en los datos devueltos por rvest.
html_attr() extrae datos de atributos:
html <- minimal_html("
<p><a href='https://en.wikipedia.org/wiki/Cat'>cats</a></p>
<p><a href='https://en.wikipedia.org/wiki/Dog'>dogs</a></p>
")
html |>
html_elements("p") |>
html_element("a") |>
html_attr("href")
#> [1] "https://en.wikipedia.org/wiki/Cat" "https://en.wikipedia.org/wiki/Dog"html_attr() siempre devuelve una cadena, por lo que si está extrayendo números o fechas, deberá realizar un procesamiento posterior.
24.4.4 Tablas
Si tiene suerte, sus datos ya estarán almacenados en una tabla HTML, y solo será cuestión de leerlos de esa tabla. Por lo general, es sencillo reconocer una tabla en su navegador: tendrá una estructura rectangular de filas y columnas, y puede copiarla y pegarla en una herramienta como Excel.
Las tablas HTML se construyen a partir de cuatro elementos principales: <table>, <tr> (fila de la tabla), <th> (encabezado de la tabla) y <td> (datos de la tabla). Aquí hay una tabla HTML simple con dos columnas y tres filas:
html <- minimal_html("
<table class='mytable'>
<tr><th>x</th> <th>y</th></tr>
<tr><td>1.5</td> <td>2.7</td></tr>
<tr><td>4.9</td> <td>1.3</td></tr>
<tr><td>7.2</td> <td>8.1</td></tr>
</table>
")rvest proporciona una función que sabe cómo leer este tipo de datos: html_table(). Devuelve una lista que contiene un tibble para cada tabla que se encuentra en la página. Use html_element() para identificar la tabla que desea extraer:
html |>
html_element(".mytable") |>
html_table()
#> # A tibble: 3 × 2
#> x y
#> <dbl> <dbl>
#> 1 1.5 2.7
#> 2 4.9 1.3
#> 3 7.2 8.1Tenga en cuenta que x e y se han convertido automáticamente en números. Esta conversión automática no siempre funciona, por lo que en situaciones más complejas es posible que desee desactivarla con convert = FALSE y luego hacer su propia conversión.
24.5 Encontrar los selectores apropiados
Averiguar el selector que necesita para sus datos suele ser la parte más difícil del problema. A menudo tendrá que experimentar un poco para encontrar un selector que sea específico (es decir, que no seleccione cosas que no le interesen) y sensible (es decir, que seleccione todo lo que le interese). ¡Muchas pruebas y errores son una parte normal del proceso! Hay dos herramientas principales disponibles para ayudarlo con este proceso: SelectorGadget y las herramientas de desarrollo de su navegador.
SelectorGadget es un bookmarklet de javascript que genera automáticamente selectores de CSS en función de los ejemplos positivos y negativos que proporcione. No siempre funciona, pero cuando lo hace, ¡es mágico! Puede aprender a instalar y usar SelectorGadget leyendo https://rvest.tidyverse.org/articles/selectorgadget.html o viendo el video de Mine en https://www.youtube.com/watch?v=PetWV5g1Xsc.
Todos los navegadores modernos vienen con un conjunto de herramientas para desarrolladores, pero recomendamos Chrome, incluso si no es su navegador habitual: sus herramientas para desarrolladores web son algunas de las mejores y están disponibles de inmediato. Haga clic con el botón derecho en un elemento de la página y haga clic en Inspeccionar. Esto abrirá una vista ampliable de la página HTML completa, centrada en el elemento en el que acaba de hacer clic. Puede usar esto para explorar la página y tener una idea de qué selectores podrían funcionar. Preste especial atención a los atributos class e id, ya que estos se usan a menudo para formar la estructura visual de la página y, por lo tanto, son buenas herramientas para extraer los datos que está buscando.
Dentro de la vista Elementos, también puede hacer clic con el botón derecho en un elemento y elegir “Copiar como selector” para generar un selector que identificará de forma única el elemento de interés.
Si SelectorGadget o Chrome DevTools han generado un selector de CSS que no comprende, pruebe Explicación de los selectores que traduce los selectores de CSS al inglés. Si te encuentras haciendo esto mucho, es posible que desees obtener más información sobre los selectores de CSS en general. Recomendamos comenzar con el divertido tutorial CSS Dinner y luego consultar los documentos web de MDN.
24.6 Poniendolo todo junto
Pongamos todo esto junto para extraer datos de algunos sitios web. Existe cierto riesgo de que estos ejemplos ya no funcionen cuando los ejecute; ese es el desafío fundamental del web scraping; si la estructura del sitio cambia, entonces tendrá que cambiar su código de raspado.
24.6.1 StarWars
rvest incluye un ejemplo muy simple en vignette("starwars"). Esta es una página simple con HTML mínimo, por lo que es un buen lugar para comenzar. Te animo a navegar a esa página ahora y usar “Inspeccionar elemento” para inspeccionar uno de los encabezados que es el título de una película de Star Wars. Use el teclado o el mouse para explorar la jerarquía del HTML y vea si puede tener una idea de la estructura compartida que usa cada película.
Debería poder ver que cada película tiene una estructura compartida que se ve así:
<section>
<h2 data-id="1">The Phantom Menace</h2>
<p>Released: 1999-05-19</p>
<p>Director: <span class="director">George Lucas</span></p>
<div class="crawl">
<p>...</p>
<p>...</p>
<p>...</p>
</div>
</section>Nuestro objetivo es convertir estos datos en un marco de datos de 7 filas con las variables title, year, director e intro. Comenzaremos leyendo el HTML y extrayendo todos los elementos <sectionn>:
url <- "https://rvest.tidyverse.org/articles/starwars.html"
html <- read_html(url)
section <- html |> html_elements("section")
section
#> {xml_nodeset (7)}
#> [1] <section><h2 data-id="1">\nThe Phantom Menace\n</h2>\n<p>\nReleased: 1 ...
#> [2] <section><h2 data-id="2">\nAttack of the Clones\n</h2>\n<p>\nReleased: ...
#> [3] <section><h2 data-id="3">\nRevenge of the Sith\n</h2>\n<p>\nReleased: ...
#> [4] <section><h2 data-id="4">\nA New Hope\n</h2>\n<p>\nReleased: 1977-05-2 ...
#> [5] <section><h2 data-id="5">\nThe Empire Strikes Back\n</h2>\n<p>\nReleas ...
#> [6] <section><h2 data-id="6">\nReturn of the Jedi\n</h2>\n<p>\nReleased: 1 ...
#> [7] <section><h2 data-id="7">\nThe Force Awakens\n</h2>\n<p>\nReleased: 20 ...Esto recupera siete elementos que coinciden con las siete películas que se encuentran en esa página, lo que sugiere que usar section como selector es bueno. La extracción de los elementos individuales es sencilla ya que los datos siempre se encuentran en el texto. Solo es cuestión de encontrar el selector adecuado:
section |> html_element("h2") |> html_text2()
#> [1] "The Phantom Menace" "Attack of the Clones"
#> [3] "Revenge of the Sith" "A New Hope"
#> [5] "The Empire Strikes Back" "Return of the Jedi"
#> [7] "The Force Awakens"
section |> html_element(".director") |> html_text2()
#> [1] "George Lucas" "George Lucas" "George Lucas"
#> [4] "George Lucas" "Irvin Kershner" "Richard Marquand"
#> [7] "J. J. Abrams"Una vez que hayamos hecho eso para cada componente, podemos envolver todos los resultados en un tibble:
tibble(
title = section |>
html_element("h2") |>
html_text2(),
released = section |>
html_element("p") |>
html_text2() |>
str_remove("Released: ") |>
parse_date(),
director = section |>
html_element(".director") |>
html_text2(),
intro = section |>
html_element(".crawl") |>
html_text2()
)
#> # A tibble: 7 × 4
#> title released director intro
#> <chr> <date> <chr> <chr>
#> 1 The Phantom Menace 1999-05-19 George Lucas "Turmoil has engulfed …
#> 2 Attack of the Clones 2002-05-16 George Lucas "There is unrest in th…
#> 3 Revenge of the Sith 2005-05-19 George Lucas "War! The Republic is …
#> 4 A New Hope 1977-05-25 George Lucas "It is a period of civ…
#> 5 The Empire Strikes Back 1980-05-17 Irvin Kershner "It is a dark time for…
#> 6 Return of the Jedi 1983-05-25 Richard Marquand "Luke Skywalker has re…
#> # ℹ 1 more rowHicimos un poco más de procesamiento de released para obtener una variable que será fácil de usar más adelante en nuestro análisis.
24.6.2 Las mejores películas de IMDB
Para nuestra próxima tarea, abordaremos algo un poco más complicado, extrayendo las 250 mejores películas de la base de datos de películas de Internet (IMDb). Cuando escribimos este capítulo, la página se parecía a Figura 24.1.
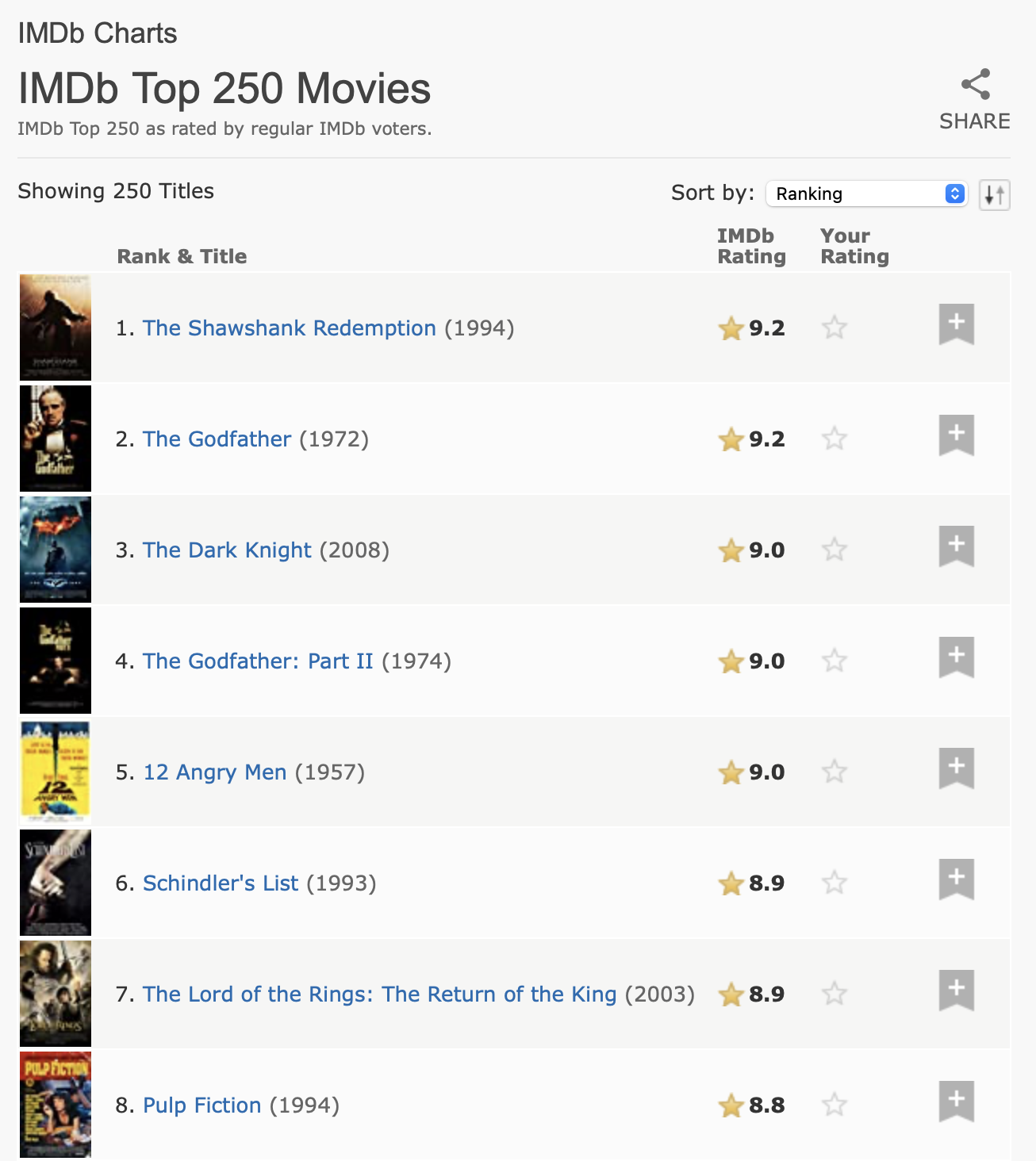
Estos datos tienen una estructura tabular clara, por lo que vale la pena comenzar con html_table():
url <- "https://web.archive.org/web/20220201012049/https://www.imdb.com/chart/top/"
html <- read_html(url)
table <- html |>
html_element("table") |>
html_table()
table
#> # A tibble: 250 × 5
#> `` `Rank & Title` `IMDb Rating` `Your Rating` ``
#> <lgl> <chr> <dbl> <chr> <lgl>
#> 1 NA "1.\n The Shawshank Redempt… 9.2 "12345678910\n… NA
#> 2 NA "2.\n The Godfather\n … 9.1 "12345678910\n… NA
#> 3 NA "3.\n The Godfather: Part I… 9 "12345678910\n… NA
#> 4 NA "4.\n The Dark Knight\n … 9 "12345678910\n… NA
#> 5 NA "5.\n 12 Angry Men\n … 8.9 "12345678910\n… NA
#> 6 NA "6.\n Schindler's List\n … 8.9 "12345678910\n… NA
#> # ℹ 244 more rowsEsto incluye algunas columnas vacías, pero en general hace un buen trabajo al capturar la información de la tabla. Sin embargo, necesitamos hacer un poco más de procesamiento para que sea más fácil de usar. Primero, cambiaremos el nombre de las columnas para que sea más fácil trabajar con ellas y eliminaremos los espacios en blanco superfluos en la clasificación y el título. Haremos esto con select() (en lugar de rename()) para renombrar y seleccionar solo estas dos columnas en un solo paso. Luego, eliminaremos las líneas nuevas y los espacios adicionales, y luego aplicaremos separate_wider_regex() (de Sección 15.3.4) para extraer el título, el año y la clasificación en sus propias variables.
ratings <- table |>
select(
rank_title_year = `Rank & Title`,
rating = `IMDb Rating`
) |>
mutate(
rank_title_year = str_replace_all(rank_title_year, "\n +", " ")
) |>
separate_wider_regex(
rank_title_year,
patterns = c(
rank = "\\d+", "\\. ",
title = ".+", " +\\(",
year = "\\d+", "\\)"
)
)
ratings
#> # A tibble: 250 × 4
#> rank title year rating
#> <chr> <chr> <chr> <dbl>
#> 1 1 The Shawshank Redemption 1994 9.2
#> 2 2 The Godfather 1972 9.1
#> 3 3 The Godfather: Part II 1974 9
#> 4 4 The Dark Knight 2008 9
#> 5 5 12 Angry Men 1957 8.9
#> 6 6 Schindler's List 1993 8.9
#> # ℹ 244 more rowsIncluso en este caso, donde la mayoría de los datos provienen de las celdas de la tabla, vale la pena mirar el código HTML sin formato. Si lo hace, descubrirá que podemos agregar un poco de información adicional usando uno de los atributos. Esta es una de las razones por las que vale la pena dedicar un poco de tiempo a explorar el origen de la página; puede encontrar datos adicionales o puede encontrar una ruta de análisis que sea un poco más fácil.
html |>
html_elements("td strong") |>
head() |>
html_attr("title")
#> [1] "9.2 based on 2,536,415 user ratings"
#> [2] "9.1 based on 1,745,675 user ratings"
#> [3] "9.0 based on 1,211,032 user ratings"
#> [4] "9.0 based on 2,486,931 user ratings"
#> [5] "8.9 based on 749,563 user ratings"
#> [6] "8.9 based on 1,295,705 user ratings"Podemos combinar esto con los datos tabulares y aplicar de nuevo separate_wider_regex() para extraer los datos que nos interesan:
ratings |>
mutate(
rating_n = html |> html_elements("td strong") |> html_attr("title")
) |>
separate_wider_regex(
rating_n,
patterns = c(
"[0-9.]+ based on ",
number = "[0-9,]+",
" user ratings"
)
) |>
mutate(
number = parse_number(number)
)
#> # A tibble: 250 × 5
#> rank title year rating number
#> <chr> <chr> <chr> <dbl> <dbl>
#> 1 1 The Shawshank Redemption 1994 9.2 2536415
#> 2 2 The Godfather 1972 9.1 1745675
#> 3 3 The Godfather: Part II 1974 9 1211032
#> 4 4 The Dark Knight 2008 9 2486931
#> 5 5 12 Angry Men 1957 8.9 749563
#> 6 6 Schindler's List 1993 8.9 1295705
#> # ℹ 244 more rows24.7 Sitios dinámicos
Hasta ahora nos hemos centrado en sitios web donde html_elements() devuelve lo que ve en el navegador y discutimos cómo analizar lo que devuelve y cómo organizar esa información en marcos de datos ordenados. De vez en cuando, sin embargo, llegarás a un sitio donde html_elements() y tus amigos no devuelven nada parecido a lo que ves en el navegador. En muchos casos, eso se debe a que intenta extraer datos de un sitio web que genera dinámicamente el contenido de la página con javascript. Actualmente, esto no funciona con rvest, porque rvest descarga el HTML sin formato y no ejecuta ningún javascript.
Todavía es posible raspar este tipo de sitios, pero rvest necesita usar un proceso más costoso: simular completamente el navegador web, incluida la ejecución de todo javascript. Esta funcionalidad no está disponible en el momento de escribir este artículo, pero es algo en lo que estamos trabajando activamente y podría estar disponible para cuando lea esto. Utiliza el [paquete chromote] (https://rstudio.github.io/chromote/index.html) que en realidad ejecuta el navegador Chrome en segundo plano y le brinda herramientas adicionales para interactuar con el sitio, como un texto de escritura humano y haciendo clic en los botones. Consulte el sitio web de rvest para obtener más detalles.
24.8 Resumen
En este capítulo, ha aprendido sobre por qué, por qué no y cómo extraer datos de páginas web. Primero, aprendió los conceptos básicos de HTML y el uso de selectores de CSS para hacer referencia a elementos específicos, luego aprendió a usar el paquete rvest para obtener datos de HTML en R. Luego demostramos el web scraping con dos casos de estudio: un escenario más simple sobre la extracción de datos sobre películas de StarWars del sitio web del paquete rvest y un escenario más complejo sobre el scraping de las 250 películas principales de IMDB.
Los detalles técnicos de la extracción de datos de la web pueden ser complejos, especialmente cuando se trata de sitios; sin embargo, las consideraciones legales y éticas pueden ser aún más complejas. Es importante que se eduque sobre ambos antes de comenzar a recopilar datos.
Esto nos lleva al final de la parte de importación del libro donde aprendió técnicas para obtener datos desde donde se encuentran (hojas de cálculo, bases de datos, archivos JSON y sitios web) en una forma ordenada en R. Ahora es el momento de dirigir nuestra mirada a un nuevo tema: sacar el máximo provecho de R como lenguaje de programación.
Y muchas API populares ya tienen paquetes CRAN que las envuelven, ¡así que comience con una pequeña investigación primero!↩︎
Obviamente no somos abogados, y esto no es un consejo legal. Pero este es el mejor resumen que podemos dar después de haber leído mucho sobre este tema.↩︎
Un ejemplo de un artículo sobre el estudio OkCupid fue publicado por el https://www.wired.com/2016/05/okcupid-study-reveals-perils-big-data-science.↩︎
Esta clase viene del paquete xml2. xml2 es un paquete de bajo nivel en el que se basa rvest.↩︎
rvest también proporciona
html_text()pero casi siempre debe usarhtml_text2()ya que hace un mejor trabajo al convertir HTML anidado en texto.↩︎