23 Datos jerárquicos
23.1 Introducción
En este capítulo, aprenderá el arte de rectangular datos: tomando datos que son fundamentalmente jerárquicos, o en forma de árbol, y convirtiéndolos en un marco de datos rectangular formado por filas y columnas. Esto es importante porque los datos jerárquicos son sorprendentemente comunes, especialmente cuando se trabaja con datos que provienen de la web.
Para obtener información sobre el rectángulo, primero deberá aprender sobre las listas, la estructura de datos que hace posible los datos jerárquicos. Luego aprenderá sobre dos funciones cruciales de tidyr: tidyr::unnest_longer() y tidyr::unnest_wider(). Luego le mostraremos algunos casos de estudio, aplicando estas funciones simples una y otra vez para resolver problemas reales. Terminaremos hablando de JSON, la fuente más frecuente de conjuntos de datos jerárquicos y un formato común para el intercambio de datos en la web.
23.1.1 Requisitos previos
En este capítulo, usaremos muchas funciones de tidyr, un miembro central de tidyverse. También usaremos repurrrsive para proporcionar algunos conjuntos de datos interesantes para la práctica de rectángulos, y terminaremos usando jsonlite para leer archivos JSON en listas R.
23.2 Listas
Hasta ahora, ha trabajado con marcos de datos que contienen vectores simples como enteros, números, caracteres, fechas y horas y factores. Estos vectores son simples porque son homogéneos: cada elemento es del mismo tipo de datos. Si quieres almacenar elementos de diferentes tipos en el mismo vector, necesitarás una lista, que creas con list():
x1 <- list(1:4, "a", TRUE)
x1
#> [[1]]
#> [1] 1 2 3 4
#>
#> [[2]]
#> [1] "a"
#>
#> [[3]]
#> [1] TRUEA menudo es conveniente nombrar los componentes, o hijos, de una lista, lo que puede hacer de la misma manera que se nombran las columnas de un tibble:
x2 <- list(a = 1:2, b = 1:3, c = 1:4)
x2
#> $a
#> [1] 1 2
#>
#> $b
#> [1] 1 2 3
#>
#> $c
#> [1] 1 2 3 4Incluso para estas listas tan simples, la impresión ocupa bastante espacio. Una alternativa útil es str(), que genera una visualización compacta de la estructura, restando énfasis al contenido:
Como puede ver, str() muestra cada hijo de la lista en su propia línea. Muestra el nombre, si está presente, luego una abreviatura del tipo, luego los primeros valores.
23.2.1 Jerarquía
Las listas pueden contener cualquier tipo de objeto, incluidas otras listas. Esto los hace adecuados para representar estructuras jerárquicas (en forma de árbol):
Esto es notablemente diferente a c(), que genera un vector plano:
A medida que las listas se vuelven más complejas, str() se vuelve más útil, ya que le permite ver la jerarquía de un vistazo:
A medida que las listas se vuelven aún más grandes y complejas, str() eventualmente comienza a fallar, y deberá cambiar a View()1. Figura 23.1 muestra el resultado de llamar a View(x5). El visor comienza mostrando solo el nivel superior de la lista, pero puede expandir interactivamente cualquiera de los componentes para ver más, como en Figura 23.2. RStudio también le mostrará el código que necesita para acceder a ese elemento, como en Figura 23.3. Volveremos sobre cómo funciona este código en Sección 27.3.
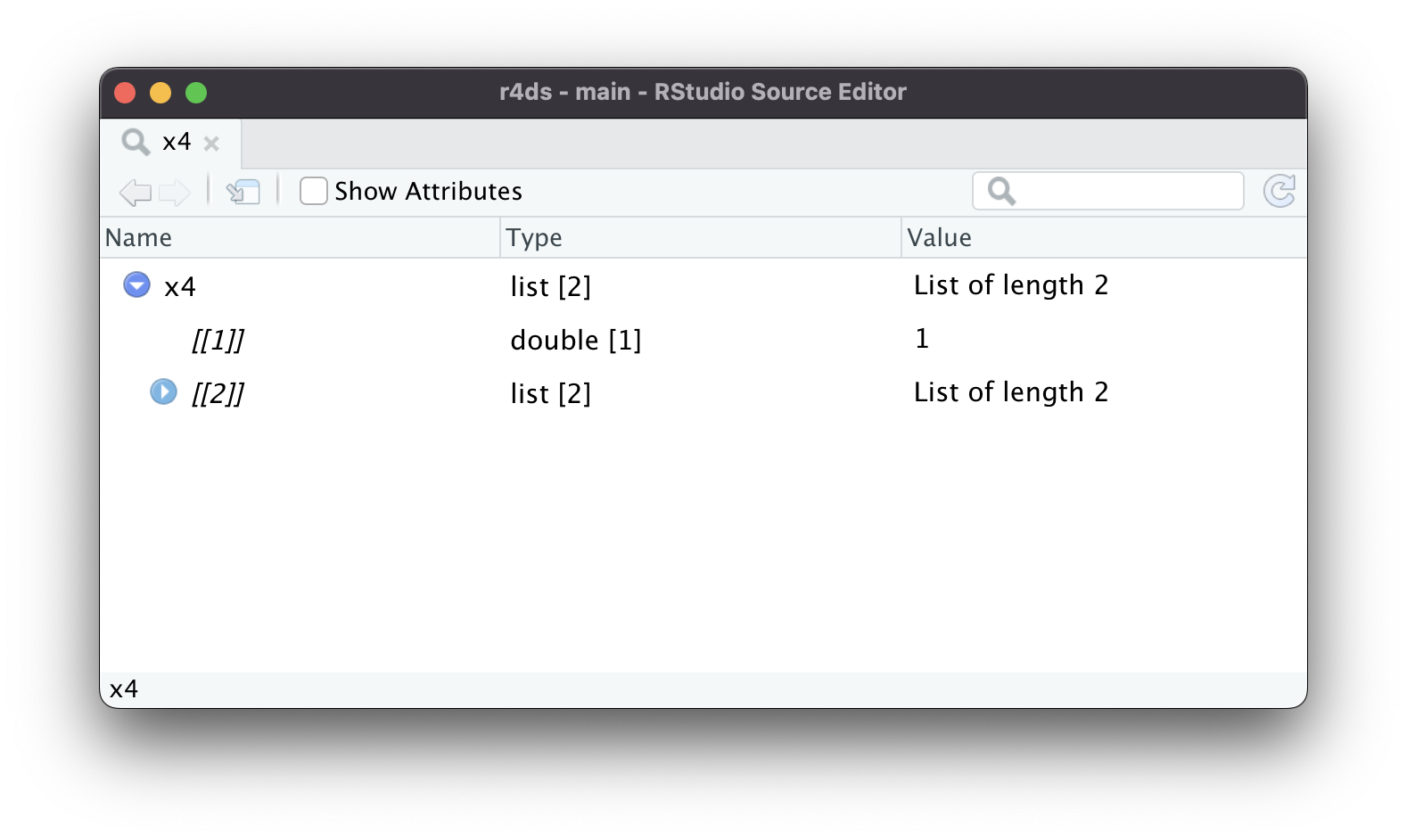
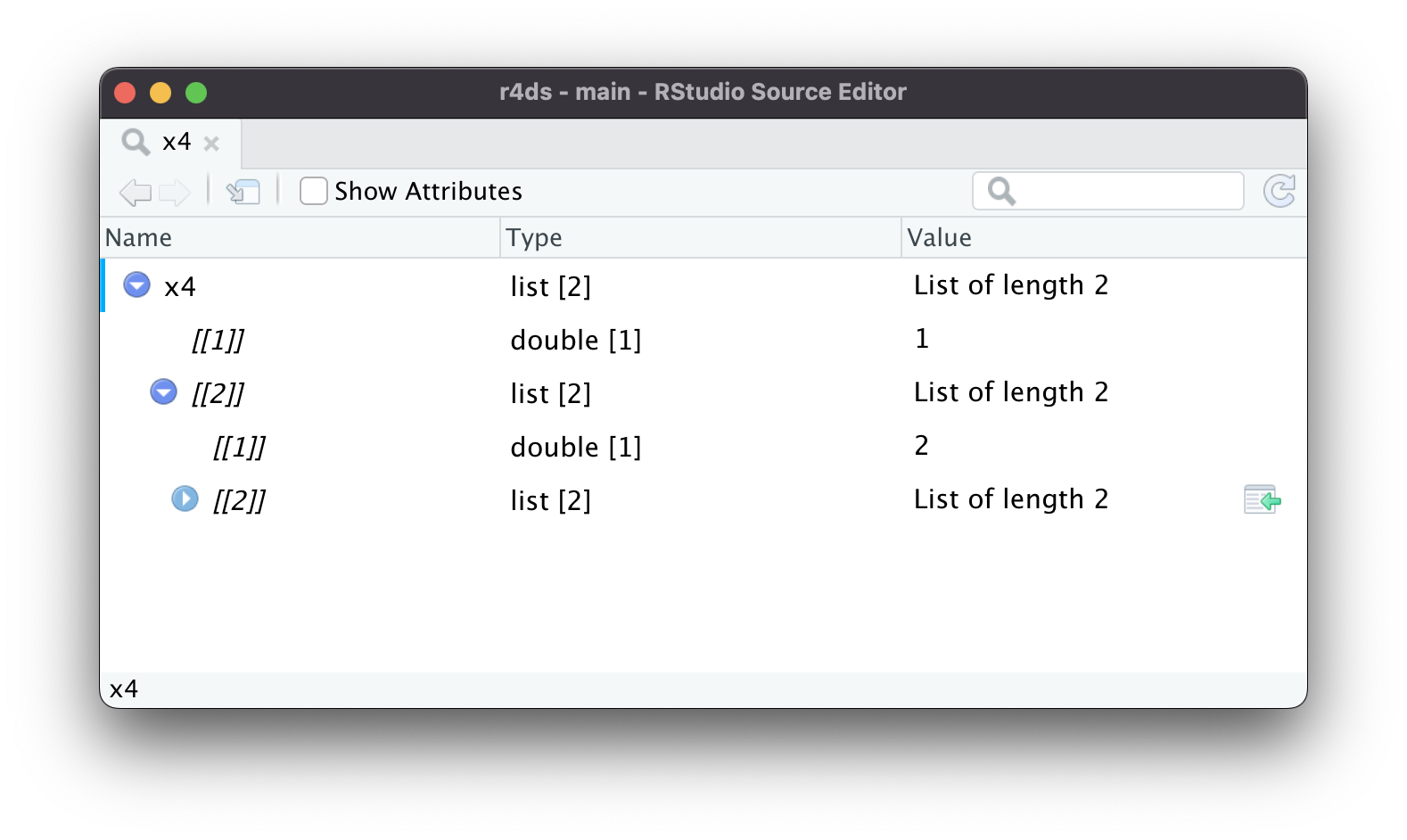
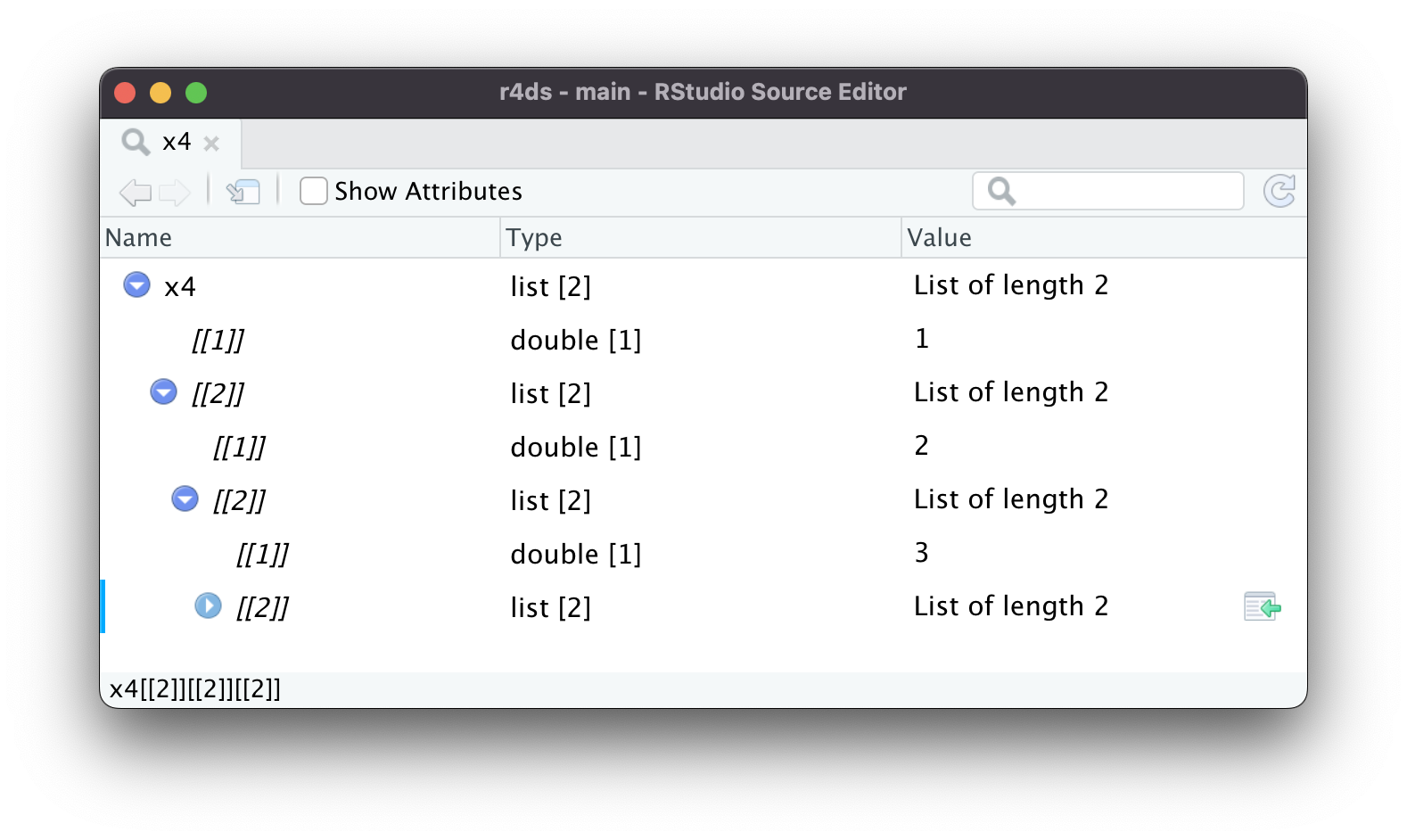
x4[[2]][[2]][[2]].
23.2.2 Lista-columnas
Las listas también pueden vivir dentro de un tibble, donde las llamamos columnas de lista. Las columnas de lista son útiles porque le permiten colocar objetos en un tibble que normalmente no pertenecerían allí. En particular, las columnas de lista se usan mucho en el ecosistema tidymodels, porque le permiten almacenar cosas como resultados de modelos o remuestreos en un marco de datos.
Aquí hay un ejemplo simple de una columna de lista:
No hay nada especial acerca de las listas en un tibble; se comportan como cualquier otra columna:
df |>
filter(x == 1)
#> # A tibble: 1 × 3
#> x y z
#> <int> <chr> <list>
#> 1 1 a <list [2]>Computar con columnas de lista es más difícil, pero eso se debe a que computar con listas es más difícil en general; volveremos a eso en Capítulo 26. En este capítulo, nos centraremos en convertir columnas de lista en variables regulares para que pueda usar sus herramientas existentes en ellas.
El método de impresión predeterminado solo muestra un resumen aproximado del contenido. La columna de la lista podría ser arbitrariamente compleja, por lo que no hay una buena manera de imprimirla. Si desea verlo, deberá extraer solo una columna de la lista y aplicar una de las técnicas que aprendió anteriormente, como df |> pull(z) |> str() o df |> pull(z) |> Ver().
Es posible poner una lista en una columna de un data.frame, pero es mucho más complicado porque data.frame() trata una lista como una lista de columnas:
data.frame(x = list(1:3, 3:5))
#> x.1.3 x.3.5
#> 1 1 3
#> 2 2 4
#> 3 3 5Puede obligar a data.frame() a tratar una lista como una lista de filas envolviéndola en la lista I(), pero el resultado no se imprime particularmente bien:
data.frame(
x = I(list(1:2, 3:5)),
y = c("1, 2", "3, 4, 5")
)
#> x y
#> 1 1, 2 1, 2
#> 2 3, 4, 5 3, 4, 5Es más fácil usar columnas de lista con tibbles porque tibble() trata las listas como vectores y el método de impresión ha sido diseñado teniendo en cuenta las listas.
23.3 Anidando
Ahora que ha aprendido los conceptos básicos de las listas y las columnas de lista, exploremos cómo puede volver a convertirlas en filas y columnas regulares. Aquí usaremos datos de muestra muy simples para que puedas tener una idea básica; en la siguiente sección cambiaremos a datos reales.
Las columnas de lista tienden a presentarse en dos formas básicas: con nombre y sin nombre. Cuando los niños tienen nombre, tienden a tener los mismos nombres en todas las filas. Por ejemplo, en df1, cada elemento de la columna de lista y tiene dos elementos llamados a y b. Las columnas de lista con nombre se separan naturalmente en columnas: cada elemento con nombre se convierte en una nueva columna con nombre.
Cuando los elementos secundarios no tienen nombre, la cantidad de elementos tiende a variar de una fila a otra. Por ejemplo, en df2, los elementos de la columna de lista y no tienen nombre y varían en longitud de uno a tres. Las columnas de lista sin nombre se anulan naturalmente en filas: obtendrá una fila para cada niño.
tidyr proporciona dos funciones para estos dos casos: unnest_wider() y unnest_longer(). Las siguientes secciones explican cómo funcionan.
23.3.1 unnest_wider()
Cuando cada fila tiene la misma cantidad de elementos con los mismos nombres, como df1, es natural poner cada componente en su propia columna con unnest_wider():
df1 |>
unnest_wider(y)
#> # A tibble: 3 × 3
#> x a b
#> <dbl> <dbl> <dbl>
#> 1 1 11 12
#> 2 2 21 22
#> 3 3 31 32Por defecto, los nombres de las nuevas columnas provienen exclusivamente de los nombres de los elementos de la lista, pero puedes usar el argumento names_sep para solicitar que combinen el nombre de la columna y el nombre del elemento. Esto es útil para eliminar la ambigüedad de los nombres repetidos.
df1 |>
unnest_wider(y, names_sep = "_")
#> # A tibble: 3 × 3
#> x y_a y_b
#> <dbl> <dbl> <dbl>
#> 1 1 11 12
#> 2 2 21 22
#> 3 3 31 32
23.3.2 unnest_longer()
Cuando cada fila contiene una lista sin nombre, lo más natural es poner cada elemento en su propia fila con unnest_longer():
df2 |>
unnest_longer(y)
#> # A tibble: 6 × 2
#> x y
#> <dbl> <dbl>
#> 1 1 11
#> 2 1 12
#> 3 1 13
#> 4 2 21
#> 5 3 31
#> 6 3 32Observe cómo x se duplica para cada elemento dentro de y: obtenemos una fila de salida para cada elemento dentro de la columna de lista. Pero, ¿qué sucede si uno de los elementos está vacío, como en el siguiente ejemplo?
df6 <- tribble(
~x, ~y,
"a", list(1, 2),
"b", list(3),
"c", list()
)
df6 |> unnest_longer(y)
#> # A tibble: 3 × 2
#> x y
#> <chr> <dbl>
#> 1 a 1
#> 2 a 2
#> 3 b 3Obtenemos cero filas en la salida, por lo que la fila desaparece efectivamente. Si desea conservar esa fila, agrega NA en y, configure keep_empty = TRUE.
23.3.3 Tipos inconsistentes
¿Qué sucede si anulas una columna de lista que contiene diferentes tipos de vectores? Por ejemplo, tome el siguiente conjunto de datos donde la columna de lista y contiene dos números, un caracter y un lógico, que normalmente no se pueden mezclar en una sola columna.
unnest_longer() siempre mantiene el conjunto de columnas sin cambios, mientras cambia el número de filas. ¿Qué es lo que ocurre? ¿Cómo unnest_longer() produce cinco filas mientras mantiene todo en y?
df4 |>
unnest_longer(y)
#> # A tibble: 4 × 2
#> x y
#> <chr> <list>
#> 1 a <dbl [1]>
#> 2 b <chr [1]>
#> 3 b <lgl [1]>
#> 4 b <dbl [1]>Como puede ver, la salida contiene una columna de lista, pero cada elemento de la columna de lista contiene un solo elemento. Debido a que unnest_longer() no puede encontrar un tipo común de vector, mantiene los tipos originales en una columna de lista. Quizás se pregunte si esto rompe el mandamiento de que todos los elementos de una columna deben ser del mismo tipo. No lo hace: cada elemento es una lista, aunque los contenidos sean de diferentes tipos.
Tratar con tipos inconsistentes es un desafío y los detalles dependen de la naturaleza precisa del problema y sus objetivos, pero lo más probable es que necesite herramientas de Capítulo 26.
23.3.4 Otras funciones
tidyr tiene algunas otras funciones útiles de rectángulos que no vamos a cubrir en este libro:
-
unnest_auto()elige automáticamente entreunnest_longer()yunnest_wider()según la estructura de la columna de la lista. Es excelente para una exploración rápida, pero en última instancia es una mala idea porque no lo obliga a comprender cómo están estructurados sus datos y hace que su código sea más difícil de entender. -
unnest()expande filas y columnas. Es útil cuando tiene una columna de lista que contiene una estructura 2d como un marco de datos, que no ve en este libro, pero que puede encontrar si usa el ecosistema tidymodels.
Es bueno conocer estas funciones, ya que puede encontrarlas al leer el código de otras personas o al abordar desafíos de rectángulos más raros.
23.3.5 Ejercicios
¿Qué sucede cuando usa
unnest_wider()con columnas de lista sin nombre comodf2? ¿Qué argumento es ahora necesario? ¿Qué sucede con los valores perdidos?¿Qué sucede cuando usa
unnest_longer()con columnas de lista con nombre comodf1? ¿Qué información adicional obtienes en la salida? ¿Cómo puedes suprimir ese detalle extra?-
De vez en cuando se encuentra con marcos de datos con varias columnas de lista con valores alineados. Por ejemplo, en el siguiente marco de datos, los valores de
yyzestán alineados (es decir,yyzsiempre tendrán la misma longitud dentro de una fila, y el primer valor deycorresponde a el primer valor dez). ¿Qué sucede si aplica dos llamadasunnest_longer()a este marco de datos? ¿Cómo puedes preservar la relación entrexey? (Sugerencia: lea atentamente la documentación).
23.4 Casos de estudio
La principal diferencia entre los ejemplos simples que usamos anteriormente y los datos reales es que los datos reales generalmente contienen múltiples niveles de anidamiento que requieren múltiples llamadas a unnest_longer() y/o unnest_wider(). Para mostrar eso en acción, esta sección trabaja a través de tres desafíos reales de rectángulos utilizando conjuntos de datos del paquete repurrrsive.
23.4.1 Datos muy amplios
Empezaremos con gh_repos. Esta es una lista que contiene datos sobre una colección de repositorios de GitHub recuperados mediante la API de GitHub. Es una lista muy anidada, por lo que es difícil mostrar la estructura en este libro; recomendamos explorar un poco por su cuenta con View(gh_repos) antes de continuar.
gh_repos es una lista, pero nuestras herramientas funcionan con columnas de lista, por lo que comenzaremos poniéndola en un tibble. Llamamos a esta columna json por razones que veremos más adelante.
repos <- tibble(json = gh_repos)
repos
#> # A tibble: 6 × 1
#> json
#> <list>
#> 1 <list [30]>
#> 2 <list [30]>
#> 3 <list [30]>
#> 4 <list [26]>
#> 5 <list [30]>
#> 6 <list [30]>Este tibble contiene 6 filas, una fila para cada hijo de gh_repos. Cada fila contiene una lista sin nombre con 26 o 30 filas. Como estos no tienen nombre, comenzaremos con unnest_longer() para poner a cada niño en su propia fila:
repos |>
unnest_longer(json)
#> # A tibble: 176 × 1
#> json
#> <list>
#> 1 <named list [68]>
#> 2 <named list [68]>
#> 3 <named list [68]>
#> 4 <named list [68]>
#> 5 <named list [68]>
#> 6 <named list [68]>
#> # ℹ 170 more rowsA primera vista, puede parecer que no hemos mejorado la situación: aunque tenemos más filas (176 en lugar de 6), cada elemento de json sigue siendo una lista. Sin embargo, hay una diferencia importante: ahora cada elemento es una lista nombrada, por lo que podemos usar unnest_wider() para poner cada elemento en su propia columna:
repos |>
unnest_longer(json) |>
unnest_wider(json)
#> # A tibble: 176 × 68
#> id name full_name owner private html_url
#> <int> <chr> <chr> <list> <lgl> <chr>
#> 1 61160198 after gaborcsardi/after <named list> FALSE https://github…
#> 2 40500181 argufy gaborcsardi/argu… <named list> FALSE https://github…
#> 3 36442442 ask gaborcsardi/ask <named list> FALSE https://github…
#> 4 34924886 baseimports gaborcsardi/base… <named list> FALSE https://github…
#> 5 61620661 citest gaborcsardi/cite… <named list> FALSE https://github…
#> 6 33907457 clisymbols gaborcsardi/clis… <named list> FALSE https://github…
#> # ℹ 170 more rows
#> # ℹ 62 more variables: description <chr>, fork <lgl>, url <chr>, …Esto ha funcionado, pero el resultado es un poco abrumador: ¡hay tantas columnas que tibble ni siquiera las imprime todas! Podemos verlos todos con names(); y aquí nos fijamos en los 10 primeros:
repos |>
unnest_longer(json) |>
unnest_wider(json) |>
names() |>
head(10)
#> [1] "id" "name" "full_name" "owner" "private"
#> [6] "html_url" "description" "fork" "url" "forks_url"Vamos a sacar algunos que parecen interesantes:
repos |>
unnest_longer(json) |>
unnest_wider(json) |>
select(id, full_name, owner, description)
#> # A tibble: 176 × 4
#> id full_name owner description
#> <int> <chr> <list> <chr>
#> 1 61160198 gaborcsardi/after <named list [17]> Run Code in the Backgro…
#> 2 40500181 gaborcsardi/argufy <named list [17]> Declarative function ar…
#> 3 36442442 gaborcsardi/ask <named list [17]> Friendly CLI interactio…
#> 4 34924886 gaborcsardi/baseimports <named list [17]> Do we get warnings for …
#> 5 61620661 gaborcsardi/citest <named list [17]> Test R package and repo…
#> 6 33907457 gaborcsardi/clisymbols <named list [17]> Unicode symbols for CLI…
#> # ℹ 170 more rowsPuede usar esto para volver a comprender cómo se estructuró gh_repos: cada niño era un usuario de GitHub que contenía una lista de hasta 30 repositorios de GitHub que crearon.
owner es otra columna de lista, y dado que contiene una lista con nombre, podemos usar unnest_wider() para obtener los valores:
repos |>
unnest_longer(json) |>
unnest_wider(json) |>
select(id, full_name, owner, description) |>
unnest_wider(owner)
#> Error in `unnest_wider()`:
#> ! Can't duplicate names between the affected columns and the original
#> data.
#> ✖ These names are duplicated:
#> ℹ `id`, from `owner`.
#> ℹ Use `names_sep` to disambiguate using the column name.
#> ℹ Or use `names_repair` to specify a repair strategy.Oh, oh, esta columna de lista también contiene una columna id y no podemos tener dos columnas id en el mismo marco de datos. Como se sugiere, usemos names_sep para resolver el problema:
repos |>
unnest_longer(json) |>
unnest_wider(json) |>
select(id, full_name, owner, description) |>
unnest_wider(owner, names_sep = "_")
#> # A tibble: 176 × 20
#> id full_name owner_login owner_id owner_avatar_url
#> <int> <chr> <chr> <int> <chr>
#> 1 61160198 gaborcsardi/after gaborcsardi 660288 https://avatars.gith…
#> 2 40500181 gaborcsardi/argufy gaborcsardi 660288 https://avatars.gith…
#> 3 36442442 gaborcsardi/ask gaborcsardi 660288 https://avatars.gith…
#> 4 34924886 gaborcsardi/baseimports gaborcsardi 660288 https://avatars.gith…
#> 5 61620661 gaborcsardi/citest gaborcsardi 660288 https://avatars.gith…
#> 6 33907457 gaborcsardi/clisymbols gaborcsardi 660288 https://avatars.gith…
#> # ℹ 170 more rows
#> # ℹ 15 more variables: owner_gravatar_id <chr>, owner_url <chr>, …Esto proporciona otro amplio conjunto de datos, pero puede tener la sensación de que owner parece contener una gran cantidad de datos adicionales sobre la persona que “posee” el repositorio.
23.4.2 Datos relacionales
Los datos anidados a veces se usan para representar datos que normalmente distribuiríamos en varios marcos de datos. Por ejemplo, tome got_chars que contiene datos sobre los personajes que aparecen en los libros y series de televisión de Game of Thrones. Al igual que gh_repos, es una lista, por lo que comenzamos convirtiéndola en una columna de lista de un tibble:
chars <- tibble(json = got_chars)
chars
#> # A tibble: 30 × 1
#> json
#> <list>
#> 1 <named list [18]>
#> 2 <named list [18]>
#> 3 <named list [18]>
#> 4 <named list [18]>
#> 5 <named list [18]>
#> 6 <named list [18]>
#> # ℹ 24 more rowsLa columna json contiene elementos con nombre, por lo que comenzaremos ampliándola:
chars |>
unnest_wider(json)
#> # A tibble: 30 × 18
#> url id name gender culture born
#> <chr> <int> <chr> <chr> <chr> <chr>
#> 1 https://www.anapio… 1022 Theon Greyjoy Male "Ironborn" "In 278 AC or …
#> 2 https://www.anapio… 1052 Tyrion Lannist… Male "" "In 273 AC, at…
#> 3 https://www.anapio… 1074 Victarion Grey… Male "Ironborn" "In 268 AC or …
#> 4 https://www.anapio… 1109 Will Male "" ""
#> 5 https://www.anapio… 1166 Areo Hotah Male "Norvoshi" "In 257 AC or …
#> 6 https://www.anapio… 1267 Chett Male "" "At Hag's Mire"
#> # ℹ 24 more rows
#> # ℹ 12 more variables: died <chr>, alive <lgl>, titles <list>, …Y seleccionando algunas columnas para que sea más fácil de leer:
characters <- chars |>
unnest_wider(json) |>
select(id, name, gender, culture, born, died, alive)
characters
#> # A tibble: 30 × 7
#> id name gender culture born died
#> <int> <chr> <chr> <chr> <chr> <chr>
#> 1 1022 Theon Greyjoy Male "Ironborn" "In 278 AC or 27… ""
#> 2 1052 Tyrion Lannister Male "" "In 273 AC, at C… ""
#> 3 1074 Victarion Greyjoy Male "Ironborn" "In 268 AC or be… ""
#> 4 1109 Will Male "" "" "In 297 AC, at…
#> 5 1166 Areo Hotah Male "Norvoshi" "In 257 AC or be… ""
#> 6 1267 Chett Male "" "At Hag's Mire" "In 299 AC, at…
#> # ℹ 24 more rows
#> # ℹ 1 more variable: alive <lgl>Este conjunto de datos también contiene muchas columnas de lista:
chars |>
unnest_wider(json) |>
select(id, where(is.list))
#> # A tibble: 30 × 8
#> id titles aliases allegiances books povBooks tvSeries playedBy
#> <int> <list> <list> <list> <list> <list> <list> <list>
#> 1 1022 <chr [2]> <chr [4]> <chr [1]> <chr [3]> <chr> <chr> <chr>
#> 2 1052 <chr [2]> <chr [11]> <chr [1]> <chr [2]> <chr> <chr> <chr>
#> 3 1074 <chr [2]> <chr [1]> <chr [1]> <chr [3]> <chr> <chr> <chr>
#> 4 1109 <chr [1]> <chr [1]> <NULL> <chr [1]> <chr> <chr> <chr>
#> 5 1166 <chr [1]> <chr [1]> <chr [1]> <chr [3]> <chr> <chr> <chr>
#> 6 1267 <chr [1]> <chr [1]> <NULL> <chr [2]> <chr> <chr> <chr>
#> # ℹ 24 more rowsExploremos la columna títulos. Es una columna de lista sin nombre, por lo que la dividiremos en filas:
chars |>
unnest_wider(json) |>
select(id, titles) |>
unnest_longer(titles)
#> # A tibble: 59 × 2
#> id titles
#> <int> <chr>
#> 1 1022 Prince of Winterfell
#> 2 1022 Lord of the Iron Islands (by law of the green lands)
#> 3 1052 Acting Hand of the King (former)
#> 4 1052 Master of Coin (former)
#> 5 1074 Lord Captain of the Iron Fleet
#> 6 1074 Master of the Iron Victory
#> # ℹ 53 more rowsEs posible que espere ver estos datos en su propia tabla porque sería fácil unirlos a los datos de los caracteres según sea necesario. Hagámoslo, lo que requiere poca limpieza: eliminar las filas que contienen cadenas vacías y cambiar el nombre de titles a title ya que cada fila ahora solo contiene un solo título.
titles <- chars |>
unnest_wider(json) |>
select(id, titles) |>
unnest_longer(titles) |>
filter(titles != "") |>
rename(title = titles)
titles
#> # A tibble: 52 × 2
#> id title
#> <int> <chr>
#> 1 1022 Prince of Winterfell
#> 2 1022 Lord of the Iron Islands (by law of the green lands)
#> 3 1052 Acting Hand of the King (former)
#> 4 1052 Master of Coin (former)
#> 5 1074 Lord Captain of the Iron Fleet
#> 6 1074 Master of the Iron Victory
#> # ℹ 46 more rowsPodría imaginarse crear una tabla como esta para cada una de las columnas de la lista y luego usar uniones para combinarlas con los datos de los caracteres según lo necesite.
23.4.3 Profundamente anidado
Terminaremos estos estudios de caso con una columna de lista que está muy anidada y requiere rondas repetidas de unnest_wider() y unnest_longer() para desentrañar: gmaps_cities. Este es un tibble de dos columnas que contiene cinco nombres de ciudades y los resultados del uso de la API de codificación geográfica de Google para determinar su ubicación:
gmaps_cities
#> # A tibble: 5 × 2
#> city json
#> <chr> <list>
#> 1 Houston <named list [2]>
#> 2 Washington <named list [2]>
#> 3 New York <named list [2]>
#> 4 Chicago <named list [2]>
#> 5 Arlington <named list [2]>json es una columna de lista con nombres internos, por lo que comenzamos con un unnest_wider():
gmaps_cities |>
unnest_wider(json)
#> # A tibble: 5 × 3
#> city results status
#> <chr> <list> <chr>
#> 1 Houston <list [1]> OK
#> 2 Washington <list [2]> OK
#> 3 New York <list [1]> OK
#> 4 Chicago <list [1]> OK
#> 5 Arlington <list [2]> OKEsto nos da el estado, status, y los resultados, results. Dejaremos la columna de estado ya que todos están OK; en un análisis real, también querrá capturar todas las filas donde status != "OK" y descubrir qué salió mal. results es una lista sin nombre, con uno o dos elementos (veremos por qué en breve), así que la dividiremos en filas:
gmaps_cities |>
unnest_wider(json) |>
select(-status) |>
unnest_longer(results)
#> # A tibble: 7 × 2
#> city results
#> <chr> <list>
#> 1 Houston <named list [5]>
#> 2 Washington <named list [5]>
#> 3 Washington <named list [5]>
#> 4 New York <named list [5]>
#> 5 Chicago <named list [5]>
#> 6 Arlington <named list [5]>
#> # ℹ 1 more rowAhora results es una lista con nombre, así que usaremos unnest_wider():
locations <- gmaps_cities |>
unnest_wider(json) |>
select(-status) |>
unnest_longer(results) |>
unnest_wider(results)
locations
#> # A tibble: 7 × 6
#> city address_components formatted_address geometry
#> <chr> <list> <chr> <list>
#> 1 Houston <list [4]> Houston, TX, USA <named list [4]>
#> 2 Washington <list [2]> Washington, USA <named list [4]>
#> 3 Washington <list [4]> Washington, DC, USA <named list [4]>
#> 4 New York <list [3]> New York, NY, USA <named list [4]>
#> 5 Chicago <list [4]> Chicago, IL, USA <named list [4]>
#> 6 Arlington <list [4]> Arlington, TX, USA <named list [4]>
#> # ℹ 1 more row
#> # ℹ 2 more variables: place_id <chr>, types <list>Ahora podemos ver por qué dos ciudades obtuvieron dos resultados: Washington igualó tanto al estado de Washington como a Washington, DC, y Arlington igualó a Arlington, Virginia y Arlington, Texas.
Hay pocos lugares diferentes a los que podríamos ir desde aquí. Es posible que deseemos determinar la ubicación exacta de la coincidencia, que se almacena en la columna de la lista geometry:
locations |>
select(city, formatted_address, geometry) |>
unnest_wider(geometry)
#> # A tibble: 7 × 6
#> city formatted_address bounds location location_type
#> <chr> <chr> <list> <list> <chr>
#> 1 Houston Houston, TX, USA <named list [2]> <named list> APPROXIMATE
#> 2 Washington Washington, USA <named list [2]> <named list> APPROXIMATE
#> 3 Washington Washington, DC, USA <named list [2]> <named list> APPROXIMATE
#> 4 New York New York, NY, USA <named list [2]> <named list> APPROXIMATE
#> 5 Chicago Chicago, IL, USA <named list [2]> <named list> APPROXIMATE
#> 6 Arlington Arlington, TX, USA <named list [2]> <named list> APPROXIMATE
#> # ℹ 1 more row
#> # ℹ 1 more variable: viewport <list>Eso nos da nuevos límites, bounds, (una región rectangular) y ubicación, location, (un punto). Podemos anular location para ver la latitud (lat) y la longitud (lng):
locations |>
select(city, formatted_address, geometry) |>
unnest_wider(geometry) |>
unnest_wider(location)
#> # A tibble: 7 × 7
#> city formatted_address bounds lat lng location_type
#> <chr> <chr> <list> <dbl> <dbl> <chr>
#> 1 Houston Houston, TX, USA <named list [2]> 29.8 -95.4 APPROXIMATE
#> 2 Washington Washington, USA <named list [2]> 47.8 -121. APPROXIMATE
#> 3 Washington Washington, DC, USA <named list [2]> 38.9 -77.0 APPROXIMATE
#> 4 New York New York, NY, USA <named list [2]> 40.7 -74.0 APPROXIMATE
#> 5 Chicago Chicago, IL, USA <named list [2]> 41.9 -87.6 APPROXIMATE
#> 6 Arlington Arlington, TX, USA <named list [2]> 32.7 -97.1 APPROXIMATE
#> # ℹ 1 more row
#> # ℹ 1 more variable: viewport <list>Extraer los límites requiere algunos pasos más:
locations |>
select(city, formatted_address, geometry) |>
unnest_wider(geometry) |>
# focus on the variables of interest
select(!location:viewport) |>
unnest_wider(bounds)
#> # A tibble: 7 × 4
#> city formatted_address northeast southwest
#> <chr> <chr> <list> <list>
#> 1 Houston Houston, TX, USA <named list [2]> <named list [2]>
#> 2 Washington Washington, USA <named list [2]> <named list [2]>
#> 3 Washington Washington, DC, USA <named list [2]> <named list [2]>
#> 4 New York New York, NY, USA <named list [2]> <named list [2]>
#> 5 Chicago Chicago, IL, USA <named list [2]> <named list [2]>
#> 6 Arlington Arlington, TX, USA <named list [2]> <named list [2]>
#> # ℹ 1 more rowLuego renombramos southwest y northeast (las esquinas del rectángulo) para que podamos usar names_sep para crear nombres cortos pero evocadores:
locations |>
select(city, formatted_address, geometry) |>
unnest_wider(geometry) |>
select(!location:viewport) |>
unnest_wider(bounds) |>
rename(ne = northeast, sw = southwest) |>
unnest_wider(c(ne, sw), names_sep = "_")
#> # A tibble: 7 × 6
#> city formatted_address ne_lat ne_lng sw_lat sw_lng
#> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 Houston Houston, TX, USA 30.1 -95.0 29.5 -95.8
#> 2 Washington Washington, USA 49.0 -117. 45.5 -125.
#> 3 Washington Washington, DC, USA 39.0 -76.9 38.8 -77.1
#> 4 New York New York, NY, USA 40.9 -73.7 40.5 -74.3
#> 5 Chicago Chicago, IL, USA 42.0 -87.5 41.6 -87.9
#> 6 Arlington Arlington, TX, USA 32.8 -97.0 32.6 -97.2
#> # ℹ 1 more rowTenga en cuenta cómo desanidamos dos columnas simultáneamente proporcionando un vector de nombres de variables a unnest_wider().
Una vez que haya descubierto la ruta para llegar a los componentes que le interesan, puede extraerlos directamente usando otra función tidyr, hoist():
Si estos casos de estudio han abierto su apetito por más rectangulares de la vida real, puede ver algunos ejemplos más en `vignette(“rectangling”, package = “tidyr”)
23.4.4 Ejercicios
Calcula aproximadamente cuándo se creó
gh_repos. ¿Por qué solo puedes estimar aproximadamente la fecha?La columna
ownersdegh_repocontiene mucha información duplicada porque cada propietario puede tener muchos repositorios. ¿Puede construir un marco de datos deownersque contenga una fila para cada propietario? (Pista: ¿distinct()funciona conlist-cols?)Siga los pasos utilizados para los
titlespara crear tablas similares para los alias, lealtades, libros y series de televisión de los personajes de Game of Thrones.-
Explique el siguiente código línea por línea. ¿Por qué es interesante? ¿Por qué funciona para
got_charspero podría no funciona en general?tibble(json = got_chars) |> unnest_wider(json) |> select(id, where(is.list)) |> pivot_longer( where(is.list), names_to = "name", values_to = "value" ) |> unnest_longer(value) En
gmaps_cities, ¿qué contieneaddress_components? ¿Por qué varía la longitud entre filas? Des anidalo apropiadamente para averiguarlo. (Pista:typessiempre parece contener dos elementos. ¿Hace que sea más fácil trabajar conunnest_wider()que conunnest_longer()?) .
23.5 JSON
Todos los estudios de casos de la sección anterior se obtuvieron de JSON. JSON es la abreviatura de javascript object notation y es la forma en que la mayoría de las API web devuelven datos. Es importante comprenderlo porque, si bien los tipos de datos de JSON y R son bastante similares, no existe un mapeo 1 a 1 perfecto, por lo que es bueno comprender un poco acerca de JSON si algo sale mal.
23.5.1 Tipos de datos
JSON es un formato simple diseñado para ser leído y escrito fácilmente por máquinas, no por humanos. Tiene seis tipos de datos clave. Cuatro de ellos son escalares:
- El tipo más simple es nulo (
null) que juega el mismo papel queNAen R. Representa la ausencia de datos. - Una cadena es muy parecida a una cadena en R, pero siempre debe usar comillas dobles.
- Un número es similar a los números de R: pueden usar notación entera (por ejemplo, 123), decimal (por ejemplo, 123,45) o científica (por ejemplo, 1,23e3). JSON no es compatible con
Inf,-InfoNaN. - Un booleano es similar a
TRUEyFALSEde R, pero usatrueyfalseen minúsculas.
Las cadenas, los números y los valores booleanos de JSON son bastante similares a los vectores de caracteres, numéricos y lógicos de R. La principal diferencia es que los escalares de JSON solo pueden representar un único valor. Para representar múltiples valores, debe usar uno de los dos tipos restantes: matrices y objetos.
Tanto las matrices como los objetos son similares a las listas en R; la diferencia es si tienen nombre o no. Una matriz es como una lista sin nombre y se escribe con []. Por ejemplo, [1, 2, 3] es una matriz que contiene 3 números, y [null, 1, "string", false] es una matriz que contiene un valor nulo, un número, una cadena y un valor booleano. Un objeto es como una lista con nombre y se escribe con {}. Los nombres (claves en terminología JSON) son cadenas, por lo que deben estar entre comillas. Por ejemplo, {"x": 1, "y": 2} es un objeto que asigna x a 1 e y a 2.
Tenga en cuenta que JSON no tiene ninguna forma nativa de representar fechas o fechas y horas, por lo que a menudo se almacenan como cadenas y deberá usar readr::parse_date() o readr::parse_datetime() para convertirlos en la estructura de datos correcta. De manera similar, las reglas de JSON para representar números de punto flotante en JSON son un poco imprecisas, por lo que a veces también encontrará números almacenados en cadenas. Aplique readr::parse_double() según sea necesario para obtener el tipo de variable correcto.
23.5.2 jsonlite
Para convertir JSON en estructuras de datos R, recomendamos el paquete jsonlite, de Jeroen Ooms. Usaremos solo dos funciones jsonlite: read_json() y parse_json(). En la vida real, usará read_json() para leer un archivo JSON del disco. Por ejemplo, el paquete repurrsive también proporciona la fuente de gh_user como un archivo JSON y puede leerlo con read_json():
# Una ruta a un archivo json dentro del paquete:
gh_users_json()
#> [1] "/home/runner/work/_temp/renv/cache/v5/linux-ubuntu-noble/R-4.4/x86_64-pc-linux-gnu/repurrrsive/1.1.0/83cf8bf4ada1dca8cfe94111c2a691d7/repurrrsive/extdata/gh_users.json"
# Léalo con read_json()
gh_users2 <- read_json(gh_users_json())
# Verifique que sea igual a los datos que estábamos usando anteriormente
identical(gh_users, gh_users2)
#> [1] TRUEEn este libro, también usaremos parse_json(), ya que toma una cadena que contiene JSON, lo que lo hace bueno para generar ejemplos simples. Para comenzar, aquí hay tres conjuntos de datos JSON simples, comenzando con un número, luego colocando algunos números en una matriz y luego colocando esa matriz en un objeto:
str(parse_json('1'))
#> int 1
str(parse_json('[1, 2, 3]'))
#> List of 3
#> $ : int 1
#> $ : int 2
#> $ : int 3
str(parse_json('{"x": [1, 2, 3]}'))
#> List of 1
#> $ x:List of 3
#> ..$ : int 1
#> ..$ : int 2
#> ..$ : int 3jsonlite tiene otra función importante llamada fromJSON(). No lo usamos aquí porque realiza una simplificación automática (simplifyVector = TRUE). Esto a menudo funciona bien, particularmente en casos simples, pero creemos que es mejor que usted mismo haga el rectángulo para que sepa exactamente lo que está sucediendo y pueda manejar más fácilmente las estructuras anidadas más complicadas.
23.5.3 Comenzando el proceso de rectangular
En la mayoría de los casos, los archivos JSON contienen una única matriz de nivel superior porque están diseñados para proporcionar datos sobre varias “cosas”, p.ej., varias páginas, varios registros o varios resultados. En este caso, comenzará su rectángulo con tibble(json) para que cada elemento se convierta en una fila:
json <- '[
{"name": "John", "age": 34},
{"name": "Susan", "age": 27}
]'
df <- tibble(json = parse_json(json))
df
#> # A tibble: 2 × 1
#> json
#> <list>
#> 1 <named list [2]>
#> 2 <named list [2]>
df |>
unnest_wider(json)
#> # A tibble: 2 × 2
#> name age
#> <chr> <int>
#> 1 John 34
#> 2 Susan 27En casos más raros, el archivo JSON consta de un solo objeto JSON de nivel superior, que representa una “cosa”. En este caso, deberá iniciar el proceso de rectangular envolviéndolo en una lista, antes de colocarlo en un tibble.
json <- '{
"status": "OK",
"results": [
{"name": "John", "age": 34},
{"name": "Susan", "age": 27}
]
}
'
df <- tibble(json = list(parse_json(json)))
df
#> # A tibble: 1 × 1
#> json
#> <list>
#> 1 <named list [2]>
df |>
unnest_wider(json) |>
unnest_longer(results) |>
unnest_wider(results)
#> # A tibble: 2 × 3
#> status name age
#> <chr> <chr> <int>
#> 1 OK John 34
#> 2 OK Susan 27Alternativamente, puede acceder al JSON analizado y comenzar con la parte que realmente le interesa:
df <- tibble(results = parse_json(json)$results)
df |>
unnest_wider(results)
#> # A tibble: 2 × 2
#> name age
#> <chr> <int>
#> 1 John 34
#> 2 Susan 2723.5.4 Ejercicios
-
Rectángulo
df_colydf_rowa continuación. Representan las dos formas de codificar un marco de datos en JSON.json_col <- parse_json(' { "x": ["a", "x", "z"], "y": [10, null, 3] } ') json_row <- parse_json(' [ {"x": "a", "y": 10}, {"x": "x", "y": null}, {"x": "z", "y": 3} ] ') df_col <- tibble(json = list(json_col)) df_row <- tibble(json = json_row)
23.6 Resumen
En este capítulo, aprendió qué son las listas, cómo puede generarlas a partir de archivos JSON y cómo convertirlas en marcos de datos rectangulares. Sorprendentemente, solo necesitamos dos funciones nuevas: unnest_longer() para colocar los elementos de la lista en filas y unnest_wider() para colocar los elementos de la lista en columnas. No importa cuán profundamente anidada esté la columna de la lista, todo lo que necesita hacer es llamar repetidamente a estas dos funciones.
JSON es el formato de datos más común devuelto por las API web. ¿Qué sucede si el sitio web no tiene una API, pero puede ver los datos que desea en el sitio web? Ese es el tema del próximo capítulo: web scraping, extracción de datos de páginas web HTML.
Esta es una característica de RStudio.↩︎