20 Hojas de calculo
20.1 Introducción
En Capítulo 7, aprendió a importar datos de archivos de texto sin formato como .csv y .tsv. Ahora es el momento de aprender cómo obtener datos de una hoja de cálculo, ya sea una hoja de cálculo de Excel o una hoja de cálculo de Google. Esto se basará en gran parte de lo que ha aprendido en Capítulo 7, pero también analizaremos consideraciones y complejidades adicionales al trabajar con datos de hojas de cálculo.
Si usted o sus colaboradores utilizan hojas de cálculo para organizar datos, le recomendamos leer el documento “Organización de datos en hojas de cálculo” de Karl Broman y Kara Woo: https://doi.org/10.1080/00031305.2017.1375989. Las mejores prácticas presentadas en este documento le ahorrarán muchos dolores de cabeza cuando importe datos de una hoja de cálculo a R para analizarlos y visualizarlos.
20.2 Excel
Microsoft Excel es un programa de software de hojas de cálculo ampliamente utilizado donde los datos se organizan en hojas de trabajo dentro de archivos de hojas de cálculo.
20.2.1 Requisitos previos
En esta sección, aprenderá a cargar datos de hojas de cálculo de Excel en R con el paquete readxl. Este paquete es tidyverse no central, por lo que debe cargarlo explícitamente, pero se instala automáticamente cuando instala el paquete tidyverse. Más tarde, también usaremos el paquete writexl, que nos permite crear hojas de cálculo de Excel.
20.2.2 Empezando
La mayoría de las funciones de readxl le permiten cargar hojas de cálculo de Excel en R:
-
read_xls()lee archivos de Excel con formatoxls. -
read_xlsx()leer archivos de Excel con formatoxlsx. -
read_excel()puede leer archivos con formatoxlsyxlsx. Adivina el tipo de archivo en función de la entrada.
Todas estas funciones tienen una sintaxis similar al igual que otras funciones que hemos introducido anteriormente para leer otros tipos de archivos, p.ej., read_csv(), read_table(), etc. Para el resto del capítulo nos enfocaremos en usar read_excel().
20.2.3 Lectura de hojas de cálculo de Excel
Figura 20.1 muestra cómo se ve la hoja de cálculo que vamos a leer en R en Excel. Esta hoja de cálculo se puede descargar en un archivo Excel desde https://docs.google.com/spreadsheets/d/1V1nPp1tzOuutXFLb3G9Eyxi3qxeEhnOXUzL5_BcCQ0w/.
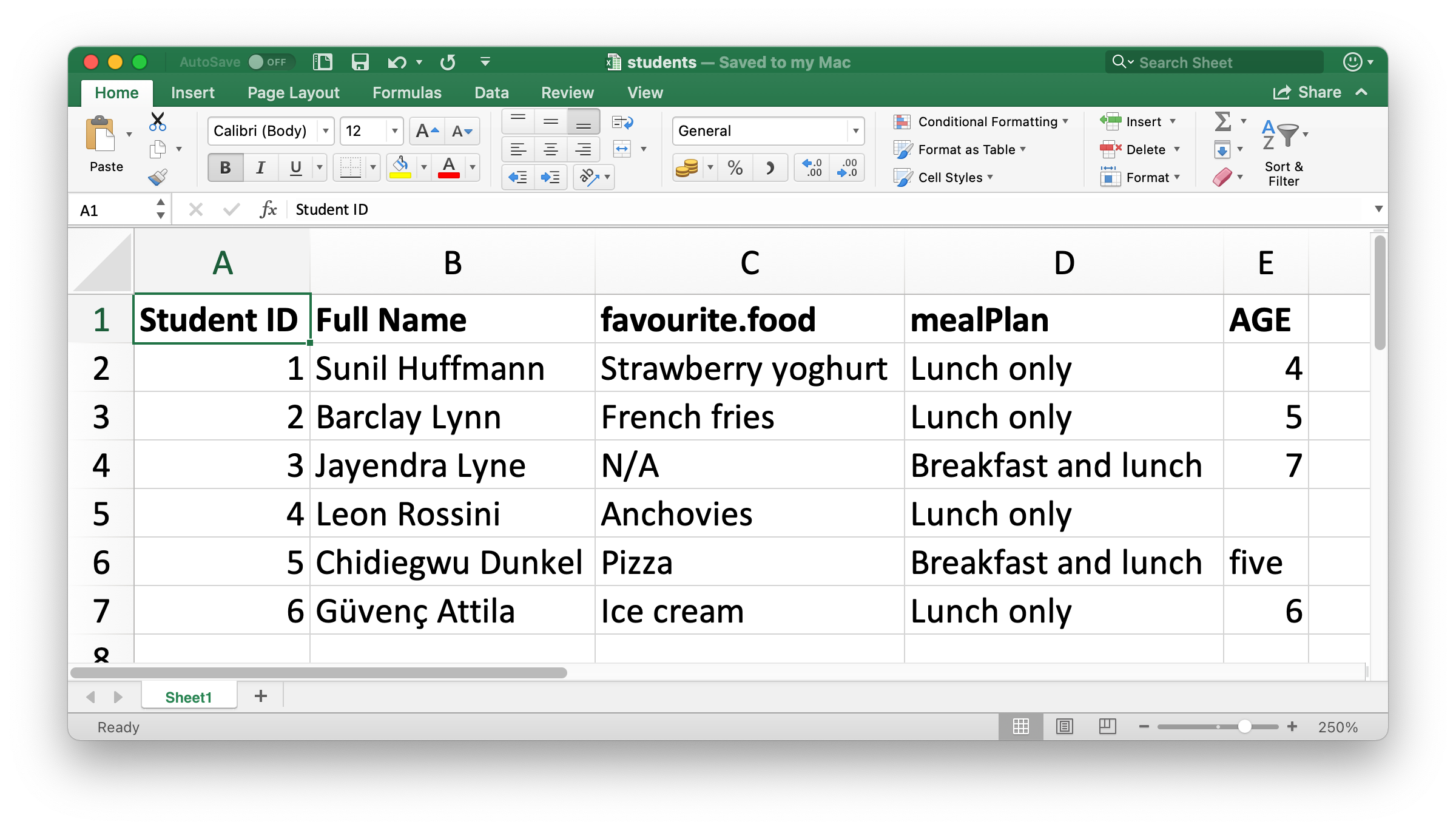
El primer argumento de read_excel() es la ruta al archivo a leer.
students <- read_excel("data/students.xlsx")read_excel() leerá el archivo como un tibble.
students
#> # A tibble: 6 × 5
#> `Student ID` `Full Name` favourite.food mealPlan AGE
#> <dbl> <chr> <chr> <chr> <chr>
#> 1 1 Sunil Huffmann Strawberry yoghurt Lunch only 4
#> 2 2 Barclay Lynn French fries Lunch only 5
#> 3 3 Jayendra Lyne N/A Breakfast and lunch 7
#> 4 4 Leon Rossini Anchovies Lunch only <NA>
#> 5 5 Chidiegwu Dunkel Pizza Breakfast and lunch five
#> 6 6 Güvenç Attila Ice cream Lunch only 6Tenemos seis estudiantes en los datos y cinco variables en cada estudiante. Sin embargo, hay algunas cosas que podríamos querer abordar en este conjunto de datos:
-
Los nombres de las columnas están por todas partes. Puede proporcionar nombres de columna que sigan un formato coherente; recomendamos
snake_caseusando el argumentocol_names.read_excel( "data/students.xlsx", col_names = c("student_id", "full_name", "favourite_food", "meal_plan", "age") ) #> # A tibble: 7 × 5 #> student_id full_name favourite_food meal_plan age #> <chr> <chr> <chr> <chr> <chr> #> 1 Student ID Full Name favourite.food mealPlan AGE #> 2 1 Sunil Huffmann Strawberry yoghurt Lunch only 4 #> 3 2 Barclay Lynn French fries Lunch only 5 #> 4 3 Jayendra Lyne N/A Breakfast and lunch 7 #> 5 4 Leon Rossini Anchovies Lunch only <NA> #> 6 5 Chidiegwu Dunkel Pizza Breakfast and lunch five #> 7 6 Güvenç Attila Ice cream Lunch only 6Desafortunadamente, esto no funcionó del todo. Ahora tenemos los nombres de las variables que queremos, pero lo que antes era la fila del encabezado ahora aparece como la primera observación en los datos. Puede omitir explícitamente esa fila usando el argumento
skip.read_excel( "data/students.xlsx", col_names = c("student_id", "full_name", "favourite_food", "meal_plan", "age"), skip = 1 ) #> # A tibble: 6 × 5 #> student_id full_name favourite_food meal_plan age #> <dbl> <chr> <chr> <chr> <chr> #> 1 1 Sunil Huffmann Strawberry yoghurt Lunch only 4 #> 2 2 Barclay Lynn French fries Lunch only 5 #> 3 3 Jayendra Lyne N/A Breakfast and lunch 7 #> 4 4 Leon Rossini Anchovies Lunch only <NA> #> 5 5 Chidiegwu Dunkel Pizza Breakfast and lunch five #> 6 6 Güvenç Attila Ice cream Lunch only 6 -
En la columna
favourite_food, una de las observaciones esN/A, que significa “no disponible”, pero actualmente no se reconoce comoNA(tenga en cuenta el contraste entre esteN/Ay la edad de el cuarto estudiante de la lista). Puede especificar qué cadenas de caracteres deben reconocerse comoNAs con el argumentona. De forma predeterminada, solo""(cadena vacía o, en el caso de leer desde una hoja de cálculo, una celda vacía o una celda con la fórmula=NA()) se reconoce comoNA.read_excel( "data/students.xlsx", col_names = c("student_id", "full_name", "favourite_food", "meal_plan", "age"), skip = 1, na = c("", "N/A") ) #> # A tibble: 6 × 5 #> student_id full_name favourite_food meal_plan age #> <dbl> <chr> <chr> <chr> <chr> #> 1 1 Sunil Huffmann Strawberry yoghurt Lunch only 4 #> 2 2 Barclay Lynn French fries Lunch only 5 #> 3 3 Jayendra Lyne <NA> Breakfast and lunch 7 #> 4 4 Leon Rossini Anchovies Lunch only <NA> #> 5 5 Chidiegwu Dunkel Pizza Breakfast and lunch five #> 6 6 Güvenç Attila Ice cream Lunch only 6 -
Otro problema pendiente es que
agese lee como una variable de carácter, pero en realidad debería ser numérico. Al igual que conread_csv()y amigos para leer datos de archivos planos, puede proporcionar un argumentocol_typesaread_excel()y especificar los tipos de columna para las variables que lee. Sin embargo, la sintaxis es un poco diferente. Sus opciones son"skip","guess","logical","numeric","date","text"o"list".read_excel( "data/students.xlsx", col_names = c("student_id", "full_name", "favourite_food", "meal_plan", "age"), skip = 1, na = c("", "N/A"), col_types = c("numeric", "text", "text", "text", "numeric") ) #> Warning: Expecting numeric in E6 / R6C5: got 'five' #> # A tibble: 6 × 5 #> student_id full_name favourite_food meal_plan age #> <dbl> <chr> <chr> <chr> <dbl> #> 1 1 Sunil Huffmann Strawberry yoghurt Lunch only 4 #> 2 2 Barclay Lynn French fries Lunch only 5 #> 3 3 Jayendra Lyne <NA> Breakfast and lunch 7 #> 4 4 Leon Rossini Anchovies Lunch only NA #> 5 5 Chidiegwu Dunkel Pizza Breakfast and lunch NA #> 6 6 Güvenç Attila Ice cream Lunch only 6Sin embargo, esto tampoco produjo el resultado deseado. Al especificar que la edad,
age, debe ser numérica, hemos convertido la única celda con la entrada no numérica (que tenía el valorfive) enNA. En este caso, deberíamos leer la edad como"texto"y luego hacer el cambio una vez que los datos estén cargados en R.students <- read_excel( "data/students.xlsx", col_names = c("student_id", "full_name", "favourite_food", "meal_plan", "age"), skip = 1, na = c("", "N/A"), col_types = c("numeric", "text", "text", "text", "text") ) students <- students |> mutate( age = if_else(age == "five", "5", age), age = parse_number(age) ) students #> # A tibble: 6 × 5 #> student_id full_name favourite_food meal_plan age #> <dbl> <chr> <chr> <chr> <dbl> #> 1 1 Sunil Huffmann Strawberry yoghurt Lunch only 4 #> 2 2 Barclay Lynn French fries Lunch only 5 #> 3 3 Jayendra Lyne <NA> Breakfast and lunch 7 #> 4 4 Leon Rossini Anchovies Lunch only NA #> 5 5 Chidiegwu Dunkel Pizza Breakfast and lunch 5 #> 6 6 Güvenç Attila Ice cream Lunch only 6
Nos tomó varios pasos y prueba y error para cargar los datos exactamente en el formato que queríamos, y esto no es inesperado. La ciencia de datos es un proceso iterativo, y el proceso de iteración puede ser aún más tedioso cuando se leen datos de hojas de cálculo en comparación con otros archivos de datos rectangulares de texto sin formato porque los humanos tienden a ingresar datos en hojas de cálculo y los usan no solo para el almacenamiento de datos sino también para compartir y comunicar.
No hay forma de saber exactamente cómo se verán los datos hasta que los cargue y los mire. Bueno, hay una manera, en realidad. Puede abrir el archivo en Excel y echar un vistazo. Si va a hacerlo, le recomendamos que haga una copia del archivo de Excel para abrirlo y navegar de forma interactiva mientras deja intacto el archivo de datos original y lee en R desde el archivo intacto. Esto asegurará que no sobrescriba accidentalmente nada en la hoja de cálculo mientras la inspecciona. Tampoco debe tener miedo de hacer lo que hicimos aquí: cargue los datos, eche un vistazo, realice ajustes en su código, cárguelo nuevamente y repita hasta que esté satisfecho con el resultado.
20.2.4 Hojas de trabajo de lectura
Una característica importante que distingue a las hojas de cálculo de los archivos planos es la noción de hojas múltiples, llamadas hojas de trabajo. Figura 20.2 muestra una hoja de cálculo de Excel con varias hojas de trabajo. Los datos provienen del paquete palmerpenguins. Cada hoja de trabajo contiene información sobre pingüinos de una isla diferente donde se recopilaron datos.
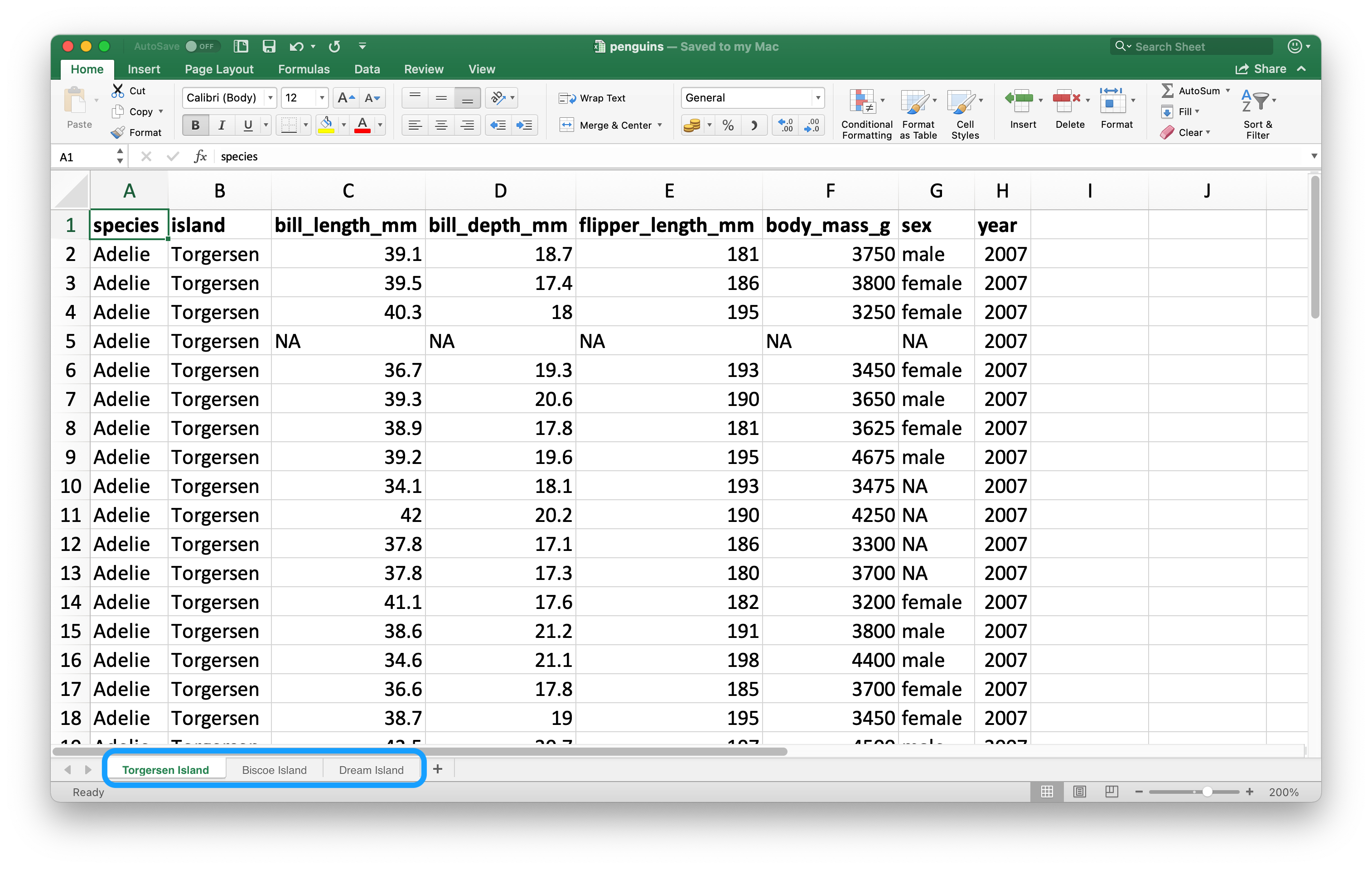
Puede leer una sola hoja de trabajo desde una hoja de cálculo con el argumento sheet en read_excel(). El valor predeterminado, en el que nos hemos basado hasta ahora, es la primera hoja.
read_excel("data/penguins.xlsx", sheet = "Torgersen Island")
#> # A tibble: 52 × 8
#> species island bill_length_mm bill_depth_mm flipper_length_mm
#> <chr> <chr> <chr> <chr> <chr>
#> 1 Adelie Torgersen 39.1 18.7 181
#> 2 Adelie Torgersen 39.5 17.399999999999999 186
#> 3 Adelie Torgersen 40.299999999999997 18 195
#> 4 Adelie Torgersen NA NA NA
#> 5 Adelie Torgersen 36.700000000000003 19.3 193
#> 6 Adelie Torgersen 39.299999999999997 20.6 190
#> # ℹ 46 more rows
#> # ℹ 3 more variables: body_mass_g <chr>, sex <chr>, year <dbl>Algunas variables que parecen contener datos numéricos se leen como caracteres debido a que la cadena de caracteres "NA" no se reconoce como verdadera NA.
penguins_torgersen <- read_excel("data/penguins.xlsx", sheet = "Torgersen Island", na = "NA")
penguins_torgersen
#> # A tibble: 52 × 8
#> species island bill_length_mm bill_depth_mm flipper_length_mm
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Adelie Torgersen 39.1 18.7 181
#> 2 Adelie Torgersen 39.5 17.4 186
#> 3 Adelie Torgersen 40.3 18 195
#> 4 Adelie Torgersen NA NA NA
#> 5 Adelie Torgersen 36.7 19.3 193
#> 6 Adelie Torgersen 39.3 20.6 190
#> # ℹ 46 more rows
#> # ℹ 3 more variables: body_mass_g <dbl>, sex <chr>, year <dbl>Alternativamente, puede usar excel_sheets() para obtener información sobre todas las hojas de trabajo en una hoja de cálculo de Excel y luego leer las que le interesan.
excel_sheets("data/penguins.xlsx")
#> [1] "Torgersen Island" "Biscoe Island" "Dream Island"Una vez que sepa los nombres de las hojas de trabajo, puede leerlas individualmente con read_excel().
penguins_biscoe <- read_excel("data/penguins.xlsx", sheet = "Biscoe Island", na = "NA")
penguins_dream <- read_excel("data/penguins.xlsx", sheet = "Dream Island", na = "NA")En este caso, el conjunto de datos completo de pingüinos se distribuye en tres hojas de trabajo en la hoja de cálculo. Cada hoja de cálculo tiene el mismo número de columnas pero diferente número de filas.
Podemos juntarlos con bind_rows().
penguins <- bind_rows(penguins_torgersen, penguins_biscoe, penguins_dream)
penguins
#> # A tibble: 344 × 8
#> species island bill_length_mm bill_depth_mm flipper_length_mm
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Adelie Torgersen 39.1 18.7 181
#> 2 Adelie Torgersen 39.5 17.4 186
#> 3 Adelie Torgersen 40.3 18 195
#> 4 Adelie Torgersen NA NA NA
#> 5 Adelie Torgersen 36.7 19.3 193
#> 6 Adelie Torgersen 39.3 20.6 190
#> # ℹ 338 more rows
#> # ℹ 3 more variables: body_mass_g <dbl>, sex <chr>, year <dbl>En Capítulo 26 hablaremos sobre formas de realizar este tipo de tareas sin código repetitivo.
20.2.5 Leer parte de una hoja
Dado que muchos usan hojas de cálculo de Excel para la presentación, así como para el almacenamiento de datos, es bastante común encontrar entradas de celdas en una hoja de cálculo que no forman parte de los datos que desea leer en R. Figura 20.3 muestra una hoja de cálculo de este tipo: en el medio de la hoja hay lo que parece un marco de datos, pero hay texto superfluo en las celdas por encima y por debajo de los datos.
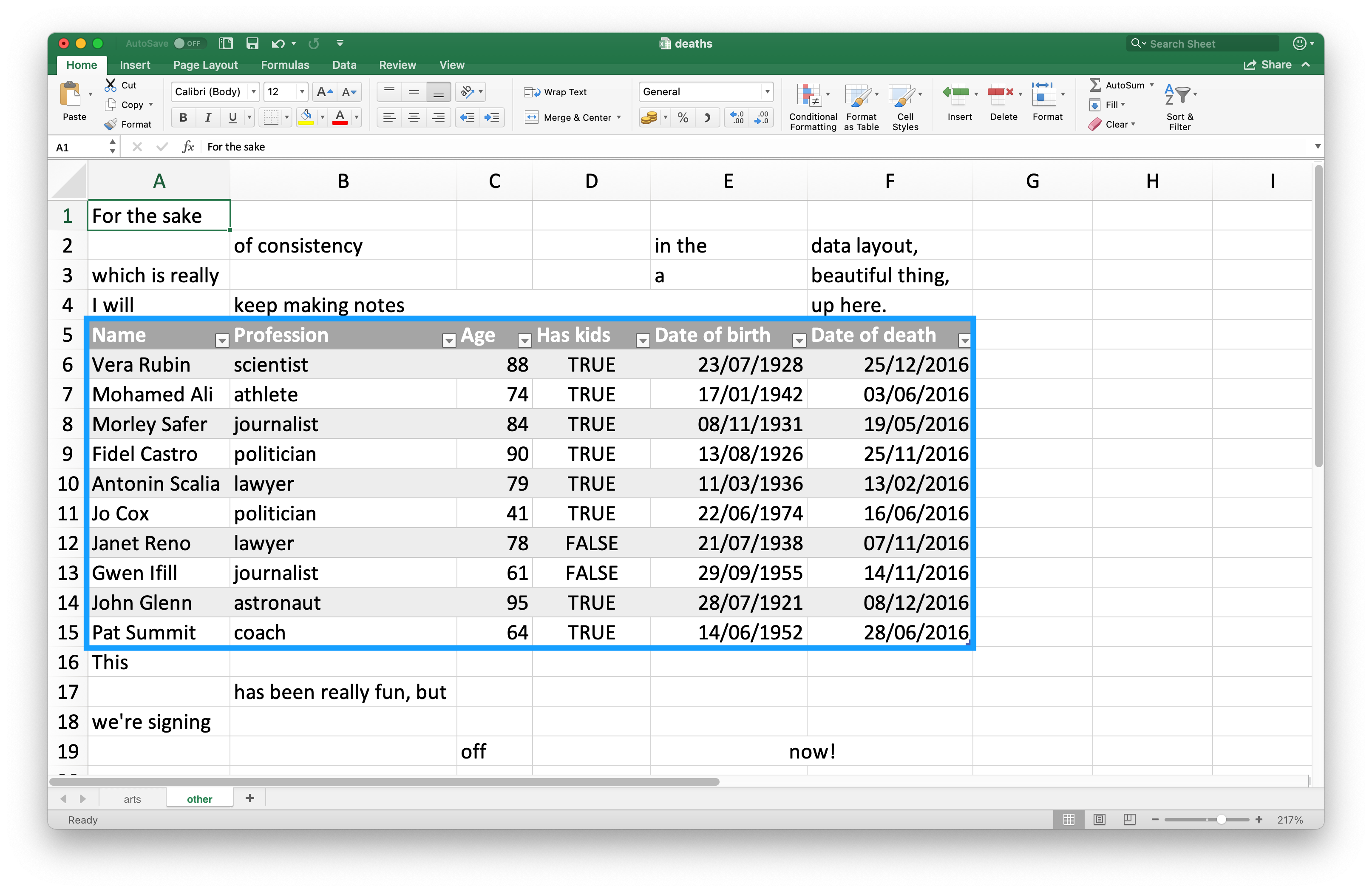
Esta hoja de cálculo es una de las hojas de cálculo de ejemplo proporcionadas en el paquete readxl. Puede usar la función readxl_example() para ubicar la hoja de cálculo en su sistema en el directorio donde está instalado el paquete. Esta función devuelve la ruta a la hoja de cálculo, que puede usar en read_excel() como de costumbre.
deaths_path <- readxl_example("deaths.xlsx")
deaths <- read_excel(deaths_path)
#> New names:
#> • `` -> `...2`
#> • `` -> `...3`
#> • `` -> `...4`
#> • `` -> `...5`
#> • `` -> `...6`
deaths
#> # A tibble: 18 × 6
#> `Lots of people` ...2 ...3 ...4 ...5 ...6
#> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 simply cannot resi… <NA> <NA> <NA> <NA> some notes
#> 2 at the top <NA> of their spreadsh…
#> 3 or merging <NA> <NA> <NA> cells
#> 4 Name Profession Age Has kids Date of birth Date of death
#> 5 David Bowie musician 69 TRUE 17175 42379
#> 6 Carrie Fisher actor 60 TRUE 20749 42731
#> # ℹ 12 more rowsLas tres filas superiores y las cuatro filas inferiores no forman parte del marco de datos. Es posible eliminar estas filas superfluas usando los argumentos skip y n_max, pero recomendamos usar rangos de celdas. En Excel, la celda superior izquierda es A1. A medida que se mueve por las columnas hacia la derecha, la etiqueta de la celda se mueve hacia abajo en el alfabeto, es decir, B1, C1, etc. Y a medida que se mueve hacia abajo en una columna, el número en la etiqueta de la celda aumenta, es decir, A2, A3, etc.
Aquí, los datos que queremos leer comienzan en la celda A5 y terminan en la celda F15. En notación de hoja de cálculo, esto es A5:F15, que proporcionamos al argumento range:
read_excel(deaths_path, range = "A5:F15")
#> # A tibble: 10 × 6
#> Name Profession Age `Has kids` `Date of birth`
#> <chr> <chr> <dbl> <lgl> <dttm>
#> 1 David Bowie musician 69 TRUE 1947-01-08 00:00:00
#> 2 Carrie Fisher actor 60 TRUE 1956-10-21 00:00:00
#> 3 Chuck Berry musician 90 TRUE 1926-10-18 00:00:00
#> 4 Bill Paxton actor 61 TRUE 1955-05-17 00:00:00
#> 5 Prince musician 57 TRUE 1958-06-07 00:00:00
#> 6 Alan Rickman actor 69 FALSE 1946-02-21 00:00:00
#> # ℹ 4 more rows
#> # ℹ 1 more variable: `Date of death` <dttm>20.2.6 Tipos de datos
En los archivos CSV, todos los valores son cadenas. Esto no es particularmente cierto para los datos, pero es simple: todo es una cadena.
Los datos subyacentes en las hojas de cálculo de Excel son más complejos. Una célula puede ser una de cuatro cosas:
Un valor booleano, como
TRUE,FALSEoNA.Un número, como “10” o “10.5”.
Una fecha y hora, que también puede incluir una hora como “1/11/21” o “1/11/21 3:00 PM”.
Una cadena de texto, como “diez”.
Al trabajar con datos de hojas de cálculo, es importante tener en cuenta que los datos subyacentes pueden ser muy diferentes de lo que ve en la celda. Por ejemplo, Excel no tiene noción de un número entero. Todos los números se almacenan como puntos flotantes, pero puede optar por mostrar los datos con un número personalizable de puntos decimales. De manera similar, las fechas en realidad se almacenan como números, específicamente la cantidad de segundos desde el 1 de enero de 1970. Puede personalizar cómo muestra la fecha aplicando formato en Excel. De manera confusa, también es posible tener algo que parezca un número pero que en realidad sea una cadena (por ejemplo, escriba '10 en una celda de Excel).
Estas diferencias entre cómo se almacenan los datos subyacentes y cómo se muestran pueden causar sorpresas cuando los datos se cargan en R. Por defecto, readxl adivinará el tipo de datos en una columna determinada. Un flujo de trabajo recomendado es dejar que readxl adivine los tipos de columna, confirme que está satisfecho con los tipos de columna adivinados y, si no, regrese y vuelva a importar especificando col_types como se muestra en Sección 20.2.3.
Otro desafío es cuando tiene una columna en su hoja de cálculo de Excel que tiene una combinación de estos tipos, p.ej., algunas celdas son numéricas, otras de texto, otras de fechas. Al importar los datos a R, readxl tiene que tomar algunas decisiones. En estos casos, puede establecer el tipo de esta columna en "list", lo que cargará la columna como una lista de vectores de longitud 1, donde se adivina el tipo de cada elemento del vector.
A veces, los datos se almacenan de formas más exóticas, como el color del fondo de la celda o si el texto está en negrita o no. En tales casos, puede encontrar útil el paquete tidyxl. Consulte https://nacnudus.github.io/spreadsheet-munging-strategies/ para obtener más información sobre estrategias para trabajar con datos no tabulares de Excel.
20.2.7 Escribir en Excel
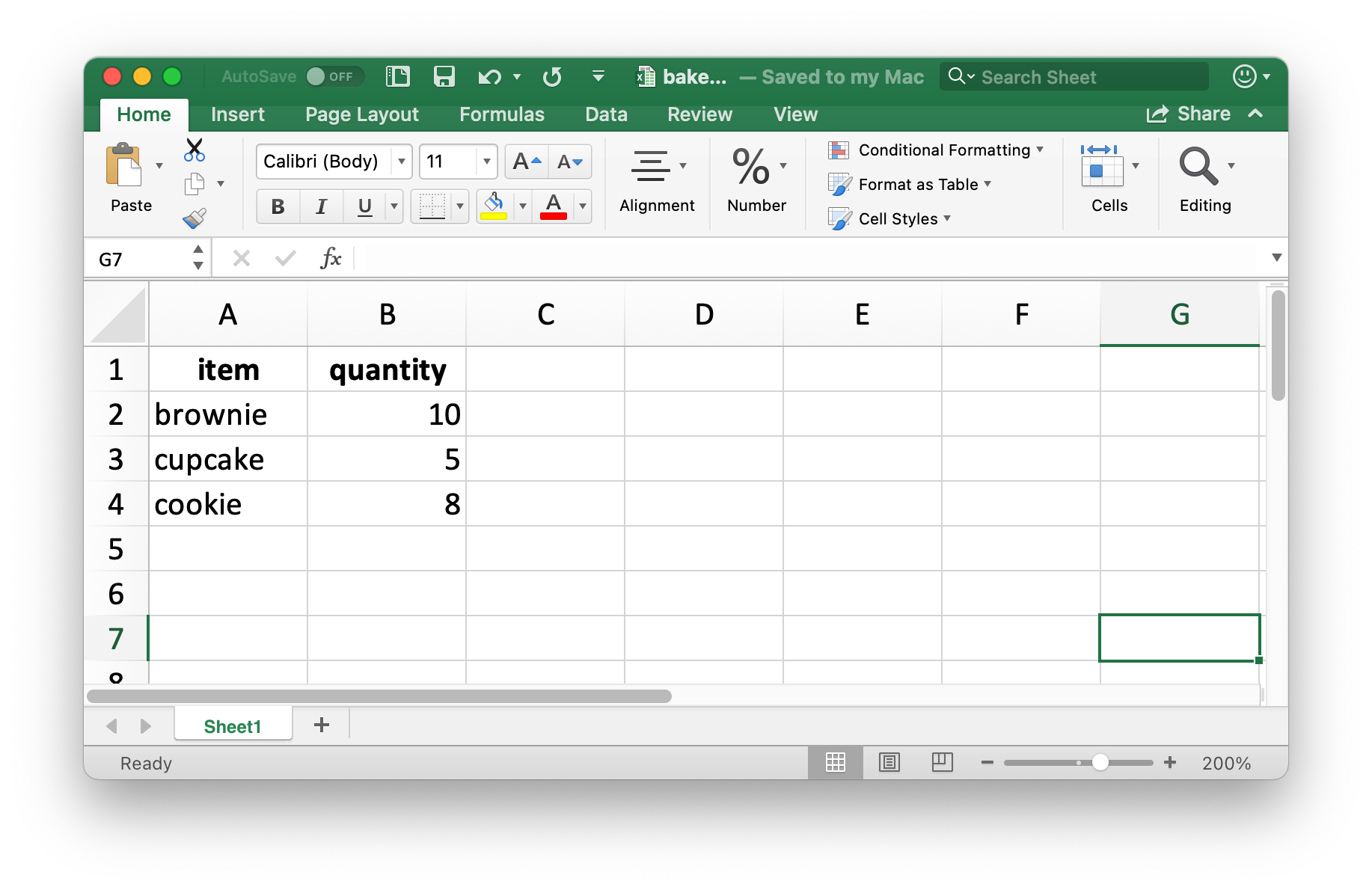
Vamos a crear un pequeño marco de datos que luego podamos escribir. Tenga en cuenta que item es un factor y quantity es un número entero.
Puede volver a escribir datos en el disco como un archivo de Excel usando write_xlsx() del paquete writexl:
write_xlsx(bake_sale, path = "data/bake-sale.xlsx")Figura 20.4 muestra cómo se ven los datos en Excel. Tenga en cuenta que los nombres de las columnas están incluidos y en negrita. Estos se pueden desactivar configurando los argumentos col_names y format_headers en FALSE.
Al igual que la lectura de un CSV, la información sobre el tipo de datos se pierde cuando volvemos a leer los datos. Esto hace que los archivos de Excel no sean confiables para almacenar en caché los resultados intermedios. Para ver alternativas, consulte Sección 7.5.
read_excel("data/bake-sale.xlsx")
#> # A tibble: 3 × 2
#> item quantity
#> <chr> <dbl>
#> 1 brownie 10
#> 2 cupcake 5
#> 3 cookie 820.2.8 Salida formateada
El paquete writexl es una solución liviana para escribir una hoja de cálculo de Excel simple, pero si está interesado en funciones adicionales como escribir en hojas dentro de una hoja de cálculo y diseñar, querrá usar el paquete openxlsx. No entraremos en los detalles del uso de este paquete aquí, pero recomendamos leer https://ycphs.github.io/openxlsx/articles/Formatting.html para una discusión extensa sobre la funcionalidad de formato adicional para los datos escritos desde R a Excel con openxlsx.
Tenga en cuenta que este paquete no forma parte de tidyverse, por lo que las funciones y los flujos de trabajo pueden parecerle desconocidos. Por ejemplo, los nombres de las funciones son camelCase, varias funciones no se pueden componer en canalizaciones y los argumentos están en un orden diferente al que suelen tener en el tidyverse. Sin embargo, esto está bien. A medida que su aprendizaje y uso de R se expanda fuera de este libro, encontrará muchos estilos diferentes utilizados en varios paquetes de R que puede usar para lograr objetivos específicos en R. Una buena manera de familiarizarse con el estilo de codificación utilizado en un nuevo paquete es ejecutar los ejemplos proporcionados en la documentación de la función para tener una idea de la sintaxis y los formatos de salida, así como leer cualquier viñeta que pueda venir con el paquete.
20.2.9 Ejercicios
-
En un archivo de Excel, cree el siguiente conjunto de datos y guárdelo como
survey.xlsx. Como alternativa, puede descargarlo como un archivo de Excel desde aquí.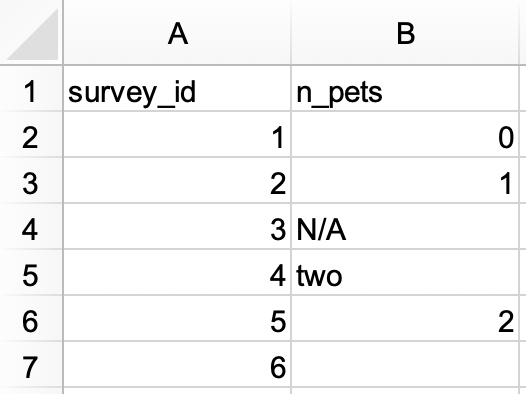
Luego, léalo en R, con
survey_idcomo variable de carácter yn_petscomo variable numérica.#> # A tibble: 6 × 2 #> survey_id n_pets #> <chr> <dbl> #> 1 1 0 #> 2 2 1 #> 3 3 NA #> 4 4 2 #> 5 5 2 #> 6 6 NA -
En otro archivo de Excel, cree el siguiente conjunto de datos y guárdelo como
roster.xlsx. Como alternativa, puede descargarlo como un archivo de Excel desde aquí.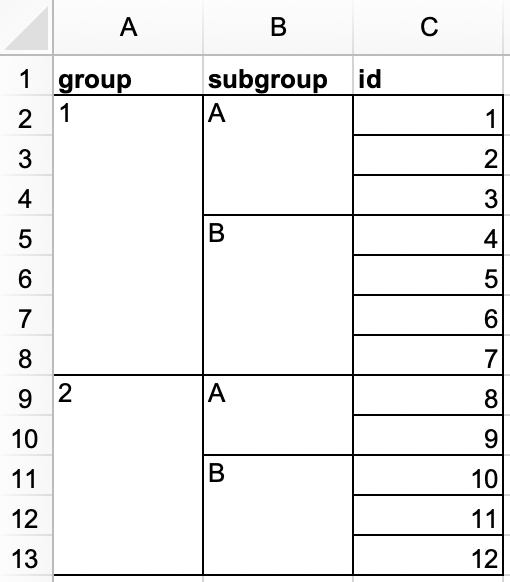
Luego, léalo en R. El marco de datos resultante debe llamarse
rostery debe tener el siguiente aspecto.#> # A tibble: 12 × 3 #> group subgroup id #> <dbl> <chr> <dbl> #> 1 1 A 1 #> 2 1 A 2 #> 3 1 A 3 #> 4 1 B 4 #> 5 1 B 5 #> 6 1 B 6 #> 7 1 B 7 #> 8 2 A 8 #> 9 2 A 9 #> 10 2 B 10 #> 11 2 B 11 #> 12 2 B 12 -
En un nuevo archivo de Excel, cree el siguiente conjunto de datos y guárdelo como
sales.xlsx. Como alternativa, puede descargarlo como un archivo de Excel desde aquí.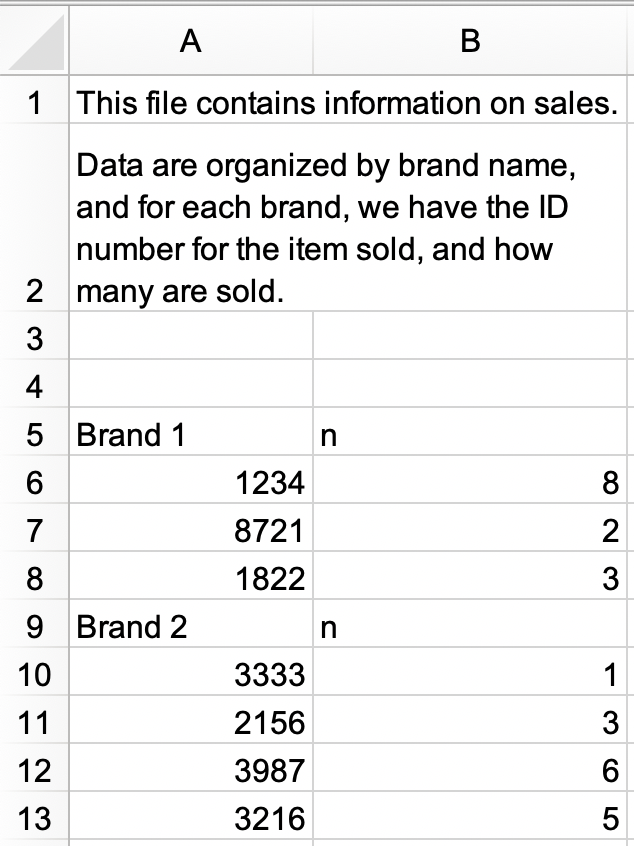
a. Lea
sales.xlsxy guárdelo comosales. El marco de datos debería verse como el siguiente, conidyncomo nombres de columna y con 9 filas.#> # A tibble: 9 × 2 #> id n #> <chr> <chr> #> 1 Brand 1 n #> 2 1234 8 #> 3 8721 2 #> 4 1822 3 #> 5 Brand 2 n #> 6 3333 1 #> 7 2156 3 #> 8 3987 6 #> 9 3216 5b. Modifique
salesaún más para obtener el siguiente formato ordenado con tres columnas (brand,idyn) y 7 filas de datos. Tenga en cuenta queidynson numéricos,brandes una variable de carácter.#> # A tibble: 7 × 3 #> brand id n #> <chr> <dbl> <dbl> #> 1 Brand 1 1234 8 #> 2 Brand 1 8721 2 #> 3 Brand 1 1822 3 #> 4 Brand 2 3333 1 #> 5 Brand 2 2156 3 #> 6 Brand 2 3987 6 #> 7 Brand 2 3216 5 Vuelva a crear el marco de datos
bake_sale, escríbalo en un archivo de Excel usando la funciónwrite.xlsx()del paquete openxlsx.En Capítulo 7, aprendió sobre la función
janitor::clean_names()para convertir los nombres de las columnas en mayúsculas y minúsculas. Lea el archivostudents.xlsxque presentamos anteriormente en esta sección y use esta función para “limpiar” los nombres de las columnas.¿Qué sucede si intentas leer un archivo con la extensión
.xlsxconread_xls()?
20.3 Hojas de cálculo de Google
Google Sheets es otro programa de hoja de cálculo ampliamente utilizado. Es gratis y está basado en la web. Al igual que con Excel, en Hojas de cálculo de Google, los datos se organizan en hojas de trabajo (también llamadas hojas) dentro de archivos de hojas de cálculo.
20.3.1 Requisitos previos
Esta sección también se centrará en las hojas de cálculo, pero esta vez cargará datos de una hoja de cálculo de Google con el paquete googlesheets4. Este paquete también es tidyverse no central, debe cargarlo explícitamente.
Una nota rápida sobre el nombre del paquete: googlesheets4 usa v4 de Sheets API v4 para proporcionar una interfaz R a Google Sheets, de ahí el nombre.
20.3.2 Empezando
La función principal del paquete googlesheets4 es read_sheet(), que lee una hoja de cálculo de Google desde una URL o una identificación de archivo. Esta función también se conoce con el nombre range_read().
También puede crear una hoja nueva con gs4_create() o escribir en una hoja existente con sheet_write() y amigos.
En esta sección, trabajaremos con los mismos conjuntos de datos que los de la sección de Excel para resaltar las similitudes y diferencias entre los flujos de trabajo para leer datos de Excel y Hojas de cálculo de Google. Los paquetes readxl y googlesheets4 están diseñados para imitar la funcionalidad del paquete readr, que proporciona la función read_csv() que ha visto en Capítulo 7. Por lo tanto, muchas de las tareas se pueden realizar simplemente cambiando read_excel() por read_sheet(). Sin embargo, también verá que Excel y Google Sheets no se comportan exactamente de la misma manera, por lo tanto, otras tareas pueden requerir más actualizaciones en las llamadas a funciones.
20.3.3 Leer Hojas de cálculo de Google
Figura 20.5 muestra cómo se ve la hoja de cálculo que vamos a leer en R en Hojas de cálculo de Google. Este es el mismo conjunto de datos que en Figura 20.1, excepto que está almacenado en una hoja de Google en lugar de Excel.
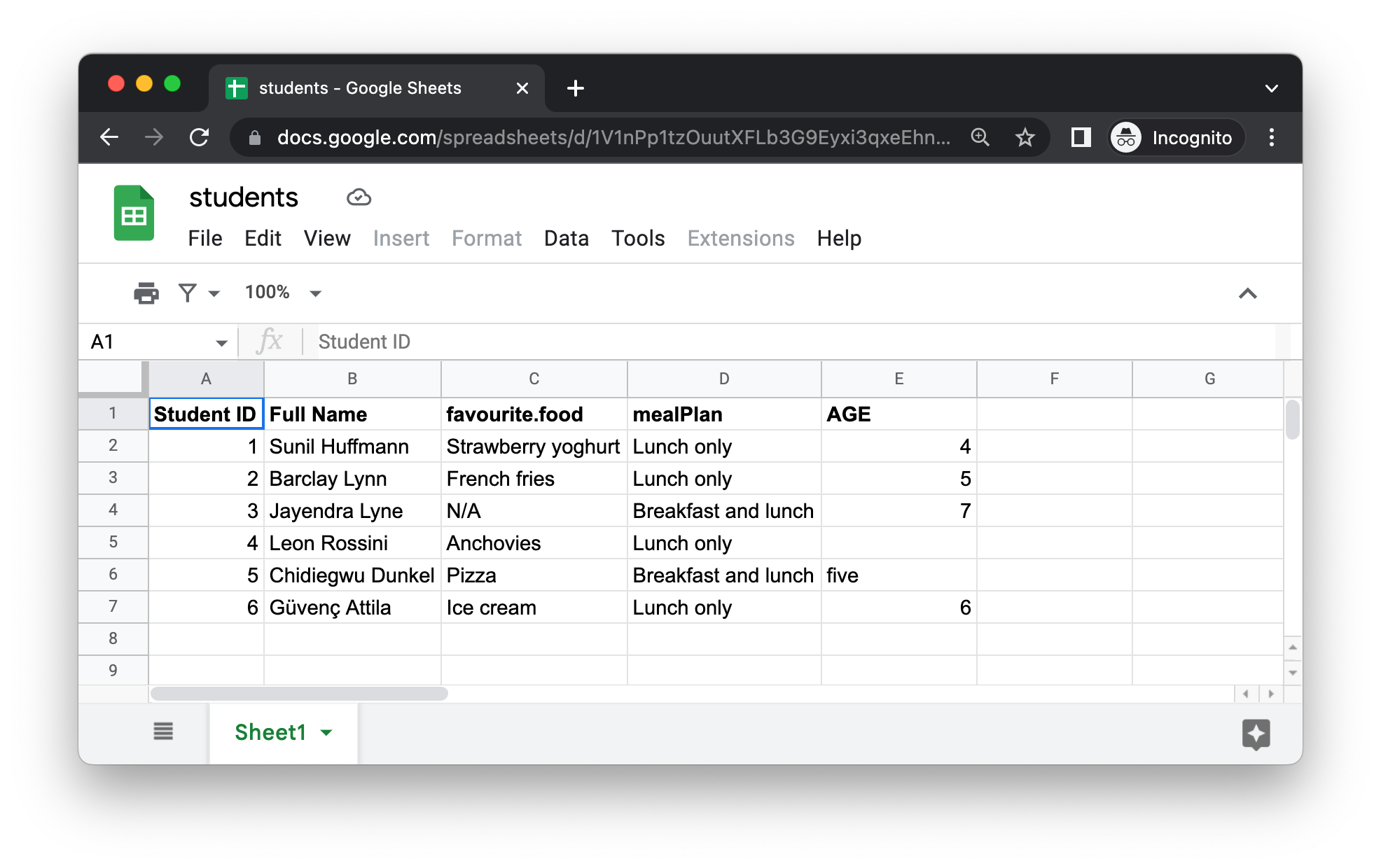
El primer argumento de read_sheet() es la URL del archivo a leer, y devuelve un tibble:<https://docs.google.com/spreadsheets/d/1V1nPp1tzOuutXFLb3G9Eyxi3qxeEhnOXUzL5_BcCQ0w>. No es agradable trabajar con estas URL, por lo que a menudo querrá identificar una hoja por su ID.
students_sheet_id <- "1V1nPp1tzOuutXFLb3G9Eyxi3qxeEhnOXUzL5_BcCQ0w"
students <- read_sheet(students_sheet_id)
#> ✔ Reading from students.
#> ✔ Range Sheet1.
students
#> # A tibble: 6 × 5
#> `Student ID` `Full Name` favourite.food mealPlan AGE
#> <dbl> <chr> <chr> <chr> <list>
#> 1 1 Sunil Huffmann Strawberry yoghurt Lunch only <dbl>
#> 2 2 Barclay Lynn French fries Lunch only <dbl>
#> 3 3 Jayendra Lyne N/A Breakfast and lunch <dbl>
#> 4 4 Leon Rossini Anchovies Lunch only <NULL>
#> 5 5 Chidiegwu Dunkel Pizza Breakfast and lunch <chr>
#> 6 6 Güvenç Attila Ice cream Lunch only <dbl>Al igual que hicimos con read_excel(), podemos proporcionar nombres de columnas, cadenas NA y tipos de columnas a read_sheet().
students <- read_sheet(
students_sheet_id,
col_names = c("student_id", "full_name", "favourite_food", "meal_plan", "age"),
skip = 1,
na = c("", "N/A"),
col_types = "dcccc"
)
#> ✔ Reading from students.
#> ✔ Range 2:10000000.
students
#> # A tibble: 6 × 5
#> student_id full_name favourite_food meal_plan age
#> <dbl> <chr> <chr> <chr> <chr>
#> 1 1 Sunil Huffmann Strawberry yoghurt Lunch only 4
#> 2 2 Barclay Lynn French fries Lunch only 5
#> 3 3 Jayendra Lyne <NA> Breakfast and lunch 7
#> 4 4 Leon Rossini Anchovies Lunch only <NA>
#> 5 5 Chidiegwu Dunkel Pizza Breakfast and lunch five
#> 6 6 Güvenç Attila Ice cream Lunch only 6Tenga en cuenta que aquí definimos los tipos de columna de manera un poco diferente, usando códigos cortos. Por ejemplo, “dcccc” significa “doble, carácter, carácter, carácter, carácter”.
También es posible leer hojas individuales de Google Sheets. Leamos la hoja “Isla Torgersen” de la Hoja de Google de pingüinos:
penguins_sheet_id <- "1aFu8lnD_g0yjF5O-K6SFgSEWiHPpgvFCF0NY9D6LXnY"
read_sheet(penguins_sheet_id, sheet = "Torgersen Island")
#> ✔ Reading from penguins.
#> ✔ Range ''Torgersen Island''.
#> # A tibble: 52 × 8
#> species island bill_length_mm bill_depth_mm flipper_length_mm
#> <chr> <chr> <list> <list> <list>
#> 1 Adelie Torgersen <dbl [1]> <dbl [1]> <dbl [1]>
#> 2 Adelie Torgersen <dbl [1]> <dbl [1]> <dbl [1]>
#> 3 Adelie Torgersen <dbl [1]> <dbl [1]> <dbl [1]>
#> 4 Adelie Torgersen <chr [1]> <chr [1]> <chr [1]>
#> 5 Adelie Torgersen <dbl [1]> <dbl [1]> <dbl [1]>
#> 6 Adelie Torgersen <dbl [1]> <dbl [1]> <dbl [1]>
#> # ℹ 46 more rows
#> # ℹ 3 more variables: body_mass_g <list>, sex <chr>, year <dbl>Puede obtener una lista de todas las hojas dentro de una Hoja de Google con sheet_names():
sheet_names(penguins_sheet_id)
#> [1] "Torgersen Island" "Biscoe Island" "Dream Island"Finalmente, al igual que con read_excel(), podemos leer una parte de una hoja de cálculo de Google definiendo un range en read_sheet(). Tenga en cuenta que también estamos usando la función gs4_example() a continuación para ubicar una hoja de cálculo de Google de ejemplo que viene con el paquete googlesheets4.
deaths_url <- gs4_example("deaths")
deaths <- read_sheet(deaths_url, range = "A5:F15")
#> ✔ Reading from deaths.
#> ✔ Range A5:F15.
deaths
#> # A tibble: 10 × 6
#> Name Profession Age `Has kids` `Date of birth`
#> <chr> <chr> <dbl> <lgl> <dttm>
#> 1 David Bowie musician 69 TRUE 1947-01-08 00:00:00
#> 2 Carrie Fisher actor 60 TRUE 1956-10-21 00:00:00
#> 3 Chuck Berry musician 90 TRUE 1926-10-18 00:00:00
#> 4 Bill Paxton actor 61 TRUE 1955-05-17 00:00:00
#> 5 Prince musician 57 TRUE 1958-06-07 00:00:00
#> 6 Alan Rickman actor 69 FALSE 1946-02-21 00:00:00
#> # ℹ 4 more rows
#> # ℹ 1 more variable: `Date of death` <dttm>20.3.4 Escribir en Hojas de cálculo de Google
Puede escribir desde R a Hojas de cálculo de Google con write_sheet(). El primer argumento es el marco de datos para escribir, y el segundo argumento es el nombre (u otro identificador) de la Hoja de Google para escribir:
write_sheet(bake_sale, ss = "bake-sale")Si desea escribir sus datos en una hoja (de trabajo) específica dentro de una hoja de cálculo de Google, también puede especificarlo con el argumento sheet.
write_sheet(bake_sale, ss = "bake-sale", sheet = "Sales")20.3.5 Autenticación
Si bien puede leer una hoja de Google pública sin autenticarse con su cuenta de Google y con gs4_deauth(), leer una hoja privada o escribir en una hoja requiere autenticación para que googlesheets4 pueda ver y administrar sus hojas de Google.
Cuando intenta leer una hoja que requiere autenticación, googlesheets4 lo dirigirá a un navegador web con un mensaje para iniciar sesión en su cuenta de Google y otorgar permiso para operar en su nombre con Hojas de cálculo de Google. Sin embargo, si desea especificar una cuenta de Google específica, el alcance de la autenticación, etc., puede hacerlo con gs4_auth(), p.ej., gs4_auth(email = "mine@example.com"), que forzará el uso de un token asociado con un correo electrónico específico. Para obtener más detalles de autenticación, recomendamos leer la documentación googlesheets4 auth viñeta: https://googlesheets4.tidyverse.org/articles/auth.html.
20.3.6 Ejercicios
Lea el conjunto de datos de
studentsanterior en el capítulo de Excel y también de Hojas de cálculo de Google, sin proporcionar argumentos adicionales a las funcionesread_excel()yread_sheet(). ¿Los marcos de datos resultantes en R son exactamente iguales? Si no, ¿en qué se diferencian?Lea la encuesta titulada Google Sheet de https://pos.it/r4ds-survey, con
survey_idcomo variable de carácter yn_petscomo variable numérica.-
Lea la lista de Google Sheet titulada de https://pos.it/r4ds-roster. El marco de datos resultante debe llamarse
rostery debe tener el siguiente aspecto.#> # A tibble: 12 × 3 #> group subgroup id #> <dbl> <chr> <dbl> #> 1 1 A 1 #> 2 1 A 2 #> 3 1 A 3 #> 4 1 B 4 #> 5 1 B 5 #> 6 1 B 6 #> 7 1 B 7 #> 8 2 A 8 #> 9 2 A 9 #> 10 2 B 10 #> 11 2 B 11 #> 12 2 B 12
20.4 Resumen
Microsoft Excel y Google Sheets son dos de los sistemas de hojas de cálculo más populares. ¡Poder interactuar con datos almacenados en archivos de Excel y Google Sheets directamente desde R es un superpoder! En este capítulo, aprendió a leer datos en R desde hojas de cálculo de Excel con read_excel() del paquete readxl y de Google Sheets con read_sheet() del paquete googlesheets4. Estas funciones funcionan de manera muy similar entre sí y tienen argumentos similares para especificar nombres de columnas, cadenas NA, filas para omitir en la parte superior del archivo que está leyendo, etc. Además, ambas funciones también permiten leer una sola hoja de una hoja de cálculo.
Por otro lado, escribir en un archivo de Excel requiere un paquete y una función diferentes (writexl::write_xlsx()), mientras que puede escribir en una hoja de cálculo de Google con el paquete googlesheets4, con write_sheet().
En el próximo capítulo, aprenderá sobre una fuente de datos diferente y cómo leer datos de esa fuente en R: bases de datos.