4 Geomas colectivas
You are reading the work-in-progress third edition of the ggplot2 book. This chapter is currently a dumping ground for ideas, and we don’t recommend reading it.
Las geoms se pueden dividir a grandes rasgos en geoms individuales y colectivas. Una geom individual dibuja un objeto gráfico distinto para cada observación (fila). Por ejemplo, el punto geom dibuja un punto por fila. Una geom colectiva muestra múltiples observaciones con un objeto geométrico. Esto puede ser el resultado de un resumen estadístico, como un diagrama de caja, o puede ser fundamental para la visualización de la geom, como un polígono. Las líneas y los caminos se encuentran en algún punto intermedio: cada línea se compone de un conjunto de segmentos rectos, pero cada segmento representa dos puntos. ¿Cómo controlamos la asignación de observaciones a elementos gráficos? Éste es el trabajo de la estética group.
De forma predeterminada, la estética del group se asigna a la interacción de todas las variables discretas en la gráfica. Esto a menudo divide los datos correctamente, pero cuando no lo hace, o cuando no se utiliza ninguna variable discreta en un gráfico, deberá definir explícitamente la estructura de agrupación asignando grupo a una variable que tenga un valor diferente para cada grupo.
Hay tres casos comunes en los que el valor predeterminado no es suficiente y los consideraremos a continuación. En los siguientes ejemplos, utilizaremos un conjunto de datos longitudinal simple, Oxboys, del paquete nlme. Registra las alturas (height) y edades centradas (age) de 26 niños (Subject), medidas en nueve ocasiones (Occasion). Subject y Occasion` se almacenan como factores ordenados.
4.1 Múltiples grupos, una estética
En muchas situaciones, querrás separar tus datos en grupos, pero renderizarlos de la misma manera. En otras palabras, se desea poder distinguir sujetos individuales, pero no identificarlos. Esto es común en estudios longitudinales con muchos sujetos, donde las gráficas a menudo se denominan descriptivamente gráficas de espagueti. Por ejemplo, el siguiente gráfico muestra la trayectoria de crecimiento de cada niño (cada Subject):
ggplot(Oxboys, aes(age, height, group = Subject)) +
geom_point() +
geom_line()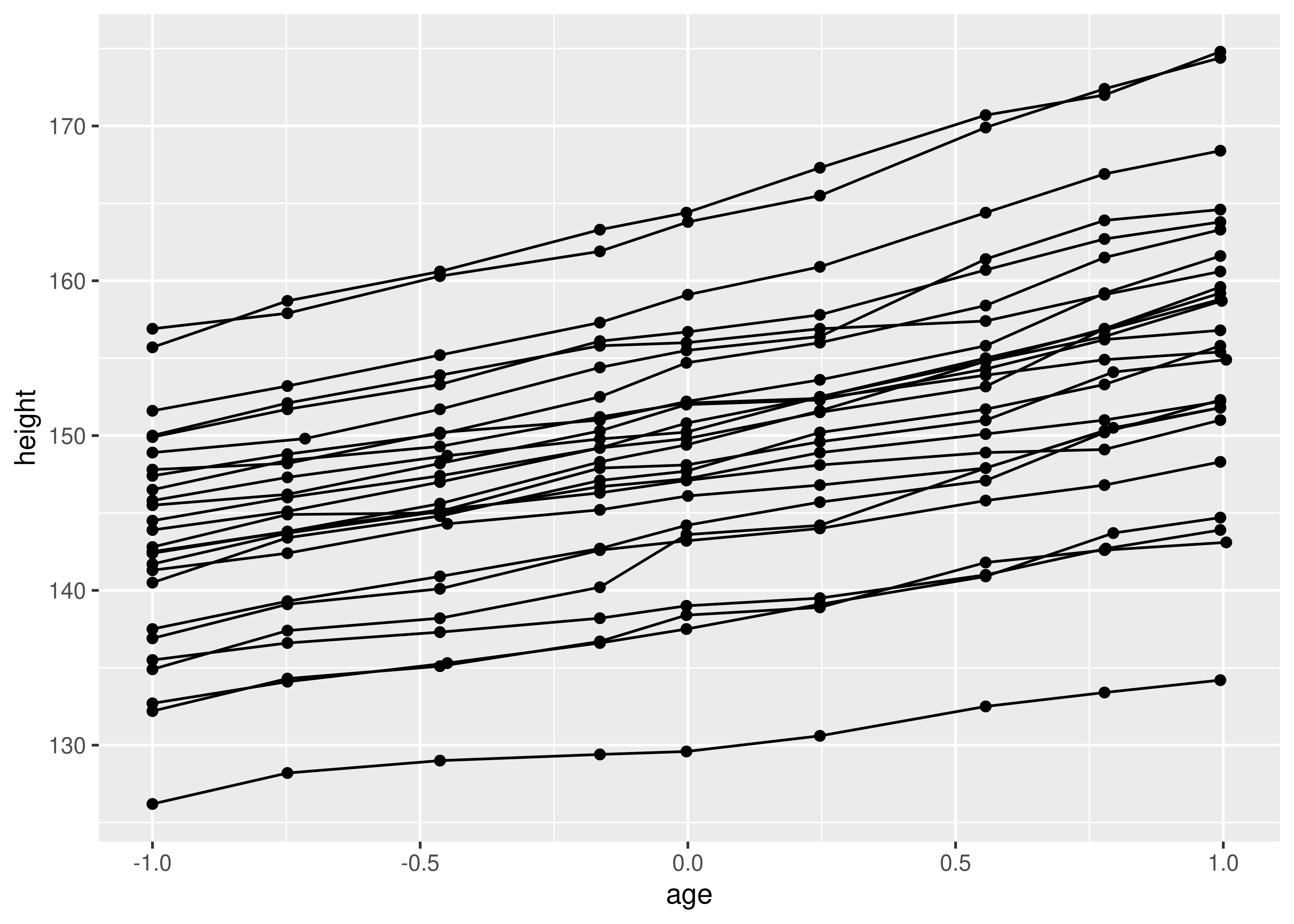
Si especifica incorrectamente la variable de agrupación, obtendrá una apariencia característica de diente de sierra:
ggplot(Oxboys, aes(age, height)) +
geom_point() +
geom_line()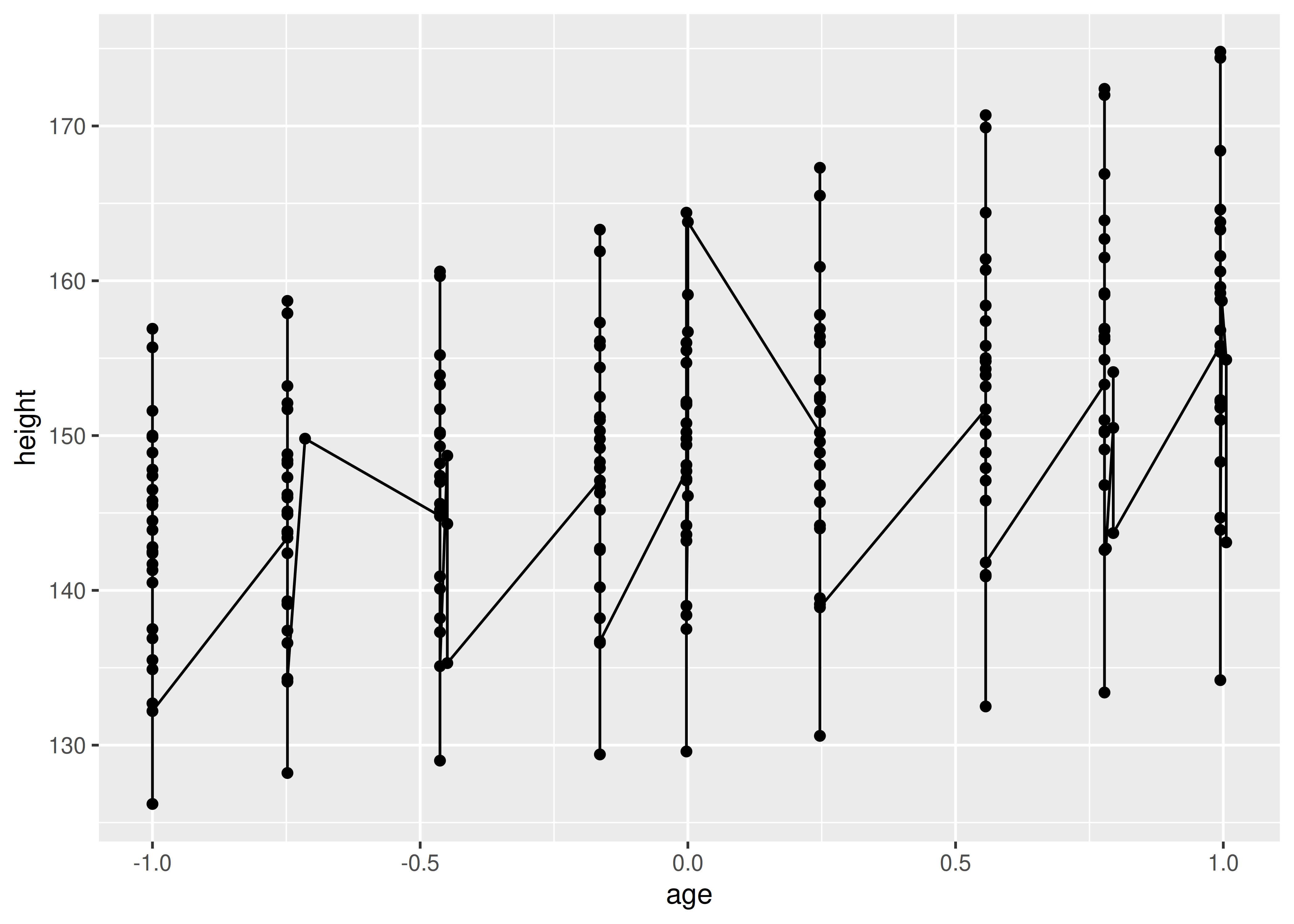
Si un grupo no está definido por una sola variable, sino por una combinación de múltiples variables, use interaction() para combinarlas, p.e. aes(group = interaction(school_id, student_id)).
4.2 Diferentes grupos en diferentes capas.
A veces queremos trazar resúmenes que utilicen diferentes niveles de agregación: una capa puede mostrar individuos, mientras que otra muestra un resumen general. Basándonos en el ejemplo anterior, supongamos que queremos agregar una única línea suave que muestre la tendencia general para todos los niños. Si utilizamos la misma agrupación en ambas capas, obtenemos un liso por niño:
ggplot(Oxboys, aes(age, height, group = Subject)) +
geom_line() +
geom_smooth(method = "lm", se = FALSE)
#> `geom_smooth()` using formula = 'y ~ x'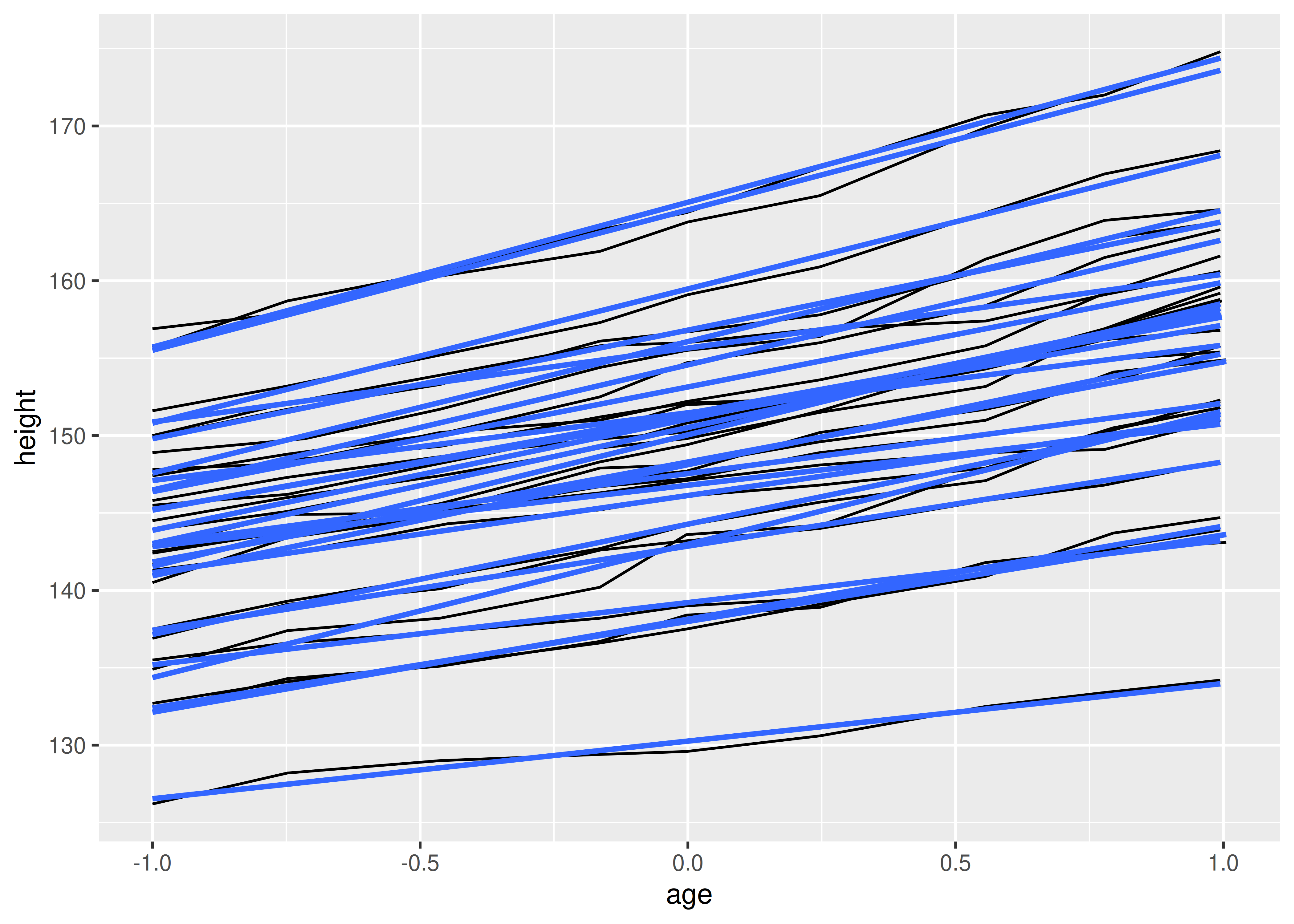
Esto no es lo que queríamos; Sin darnos cuenta, hemos agregado una línea suavizada para cada niño. La agrupación controla tanto la visualización de las geoms como el funcionamiento de las estadísticas: se ejecuta una transformación estadística para cada grupo.
En lugar de configurar la estética de agrupación en ggplot(), donde se aplicará a todas las capas, la configuramos en geom_line() para que se aplique solo a las líneas. No hay variables discretas en el gráfico, por lo que la variable de agrupación predeterminada será una constante y obtenemos una suave:
ggplot(Oxboys, aes(age, height)) +
geom_line(aes(group = Subject)) +
geom_smooth(method = "lm", linewidth = 2, se = FALSE)
#> `geom_smooth()` using formula = 'y ~ x'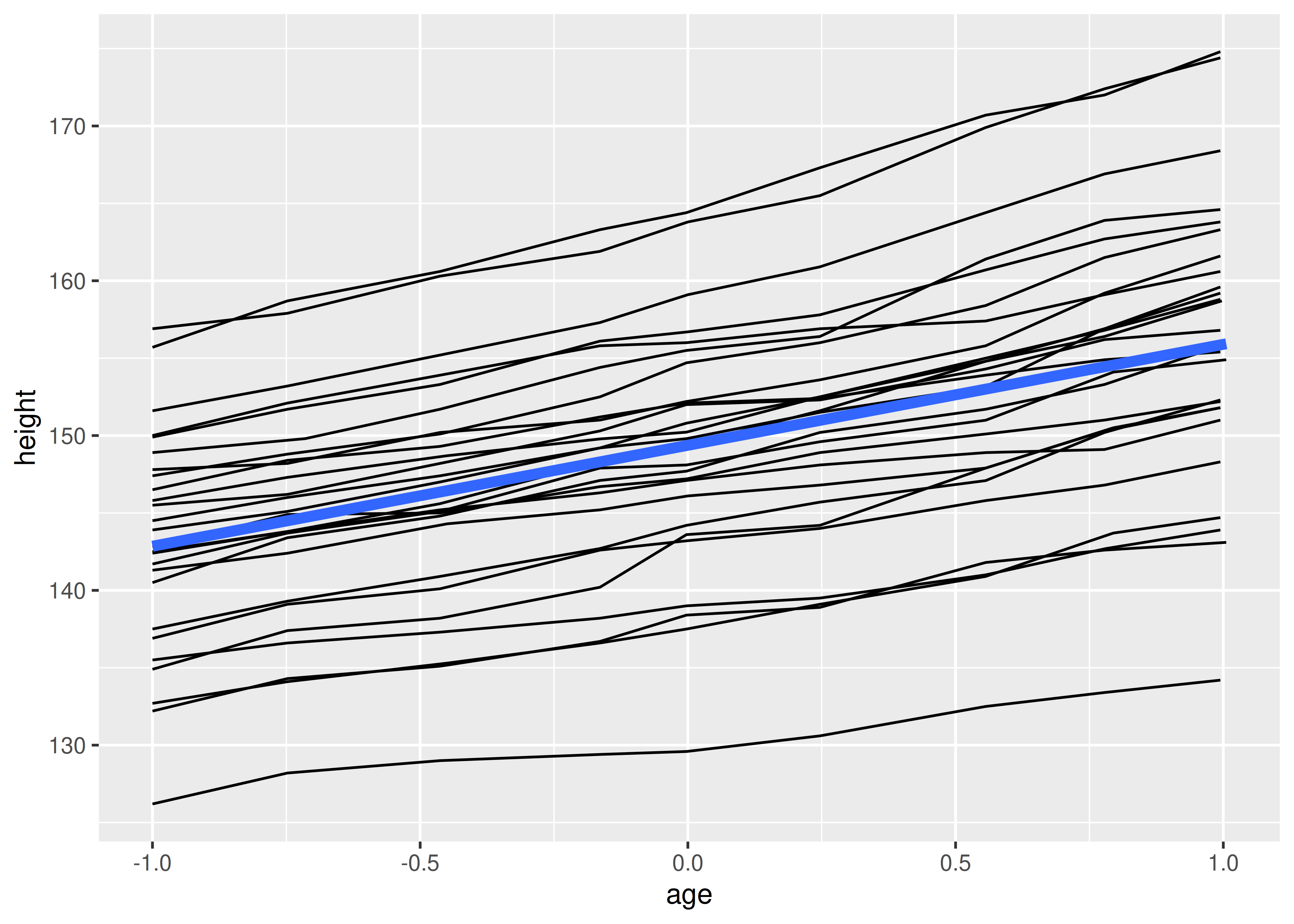
4.3 Anulación de la agrupación predeterminada
Algunos gráficos tienen una escala x discreta, pero aún desea dibujar líneas que conecten entre grupos. Esta es la estrategia utilizada en gráficos de interacción, gráficos de perfil y gráficos de coordenadas paralelas, entre otros. Por ejemplo, imagina que hemos dibujado diagramas de caja de la altura en cada ocasión de medición:
ggplot(Oxboys, aes(Occasion, height)) +
geom_boxplot()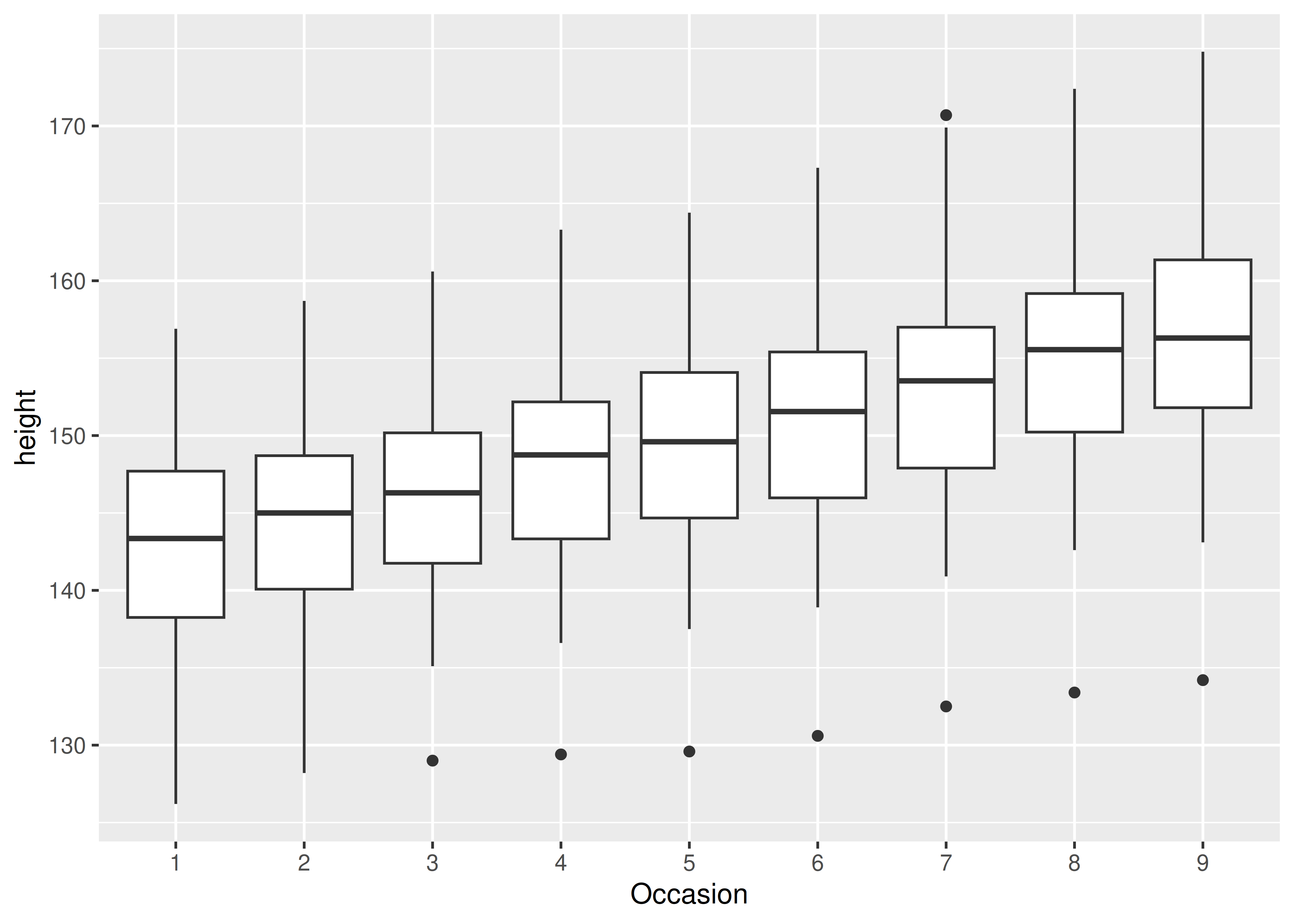
Hay una variable discreta en este gráfico, Occasion, por lo que obtenemos un diagrama de caja para cada valor x único. Ahora queremos superponer líneas que conecten a cada niño individualmente. Simplemente agregar geom_line() no funciona: las líneas se dibujan dentro de cada ocasión, no en cada tema:
ggplot(Oxboys, aes(Occasion, height)) +
geom_boxplot() +
geom_line(colour = "#3366FF", alpha = 0.5)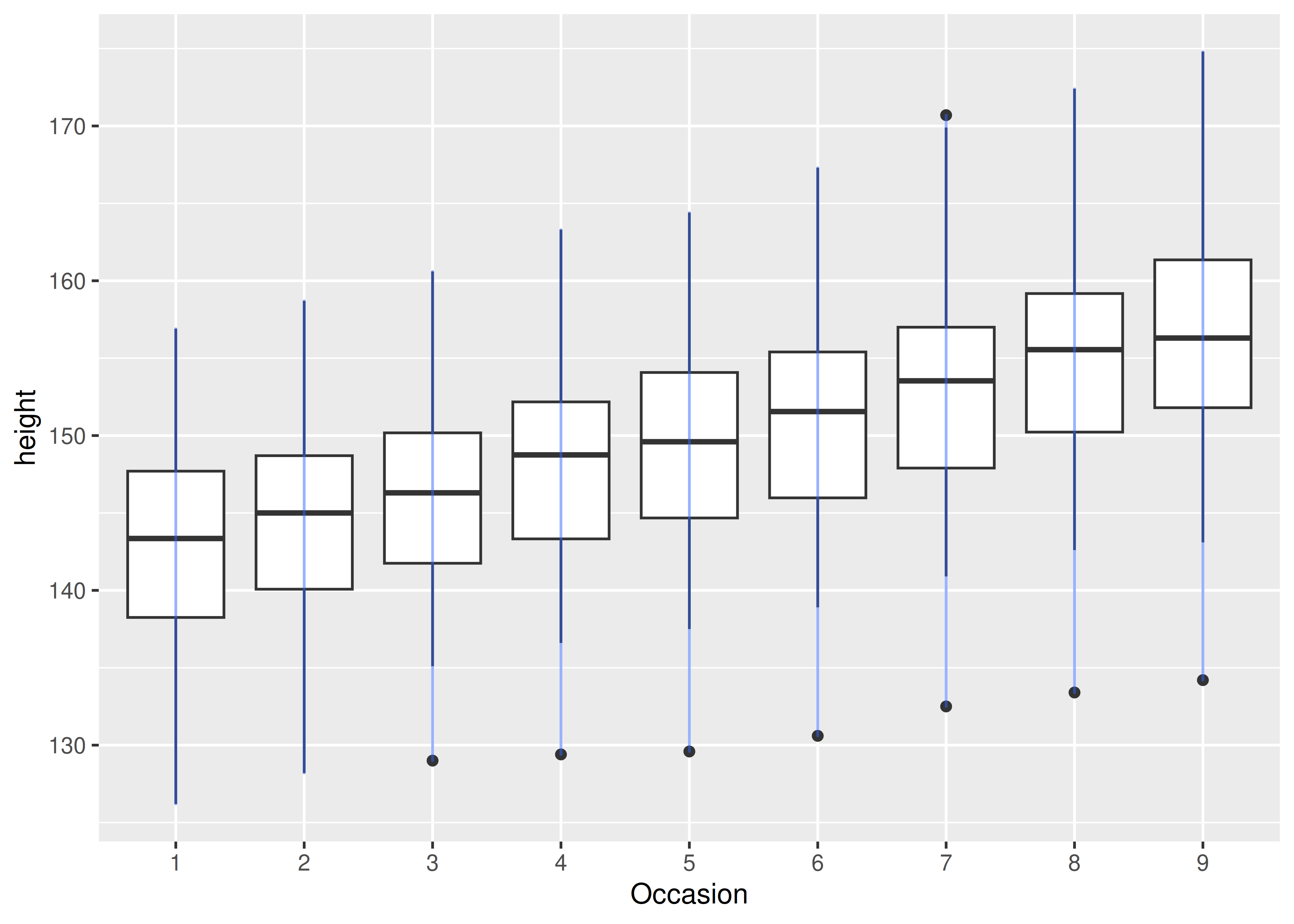
Para obtener la gráfica que queremos, debemos anular la agrupación para decir que queremos una línea por niño:
ggplot(Oxboys, aes(Occasion, height)) +
geom_boxplot() +
geom_line(aes(group = Subject), colour = "#3366FF", alpha = 0.5)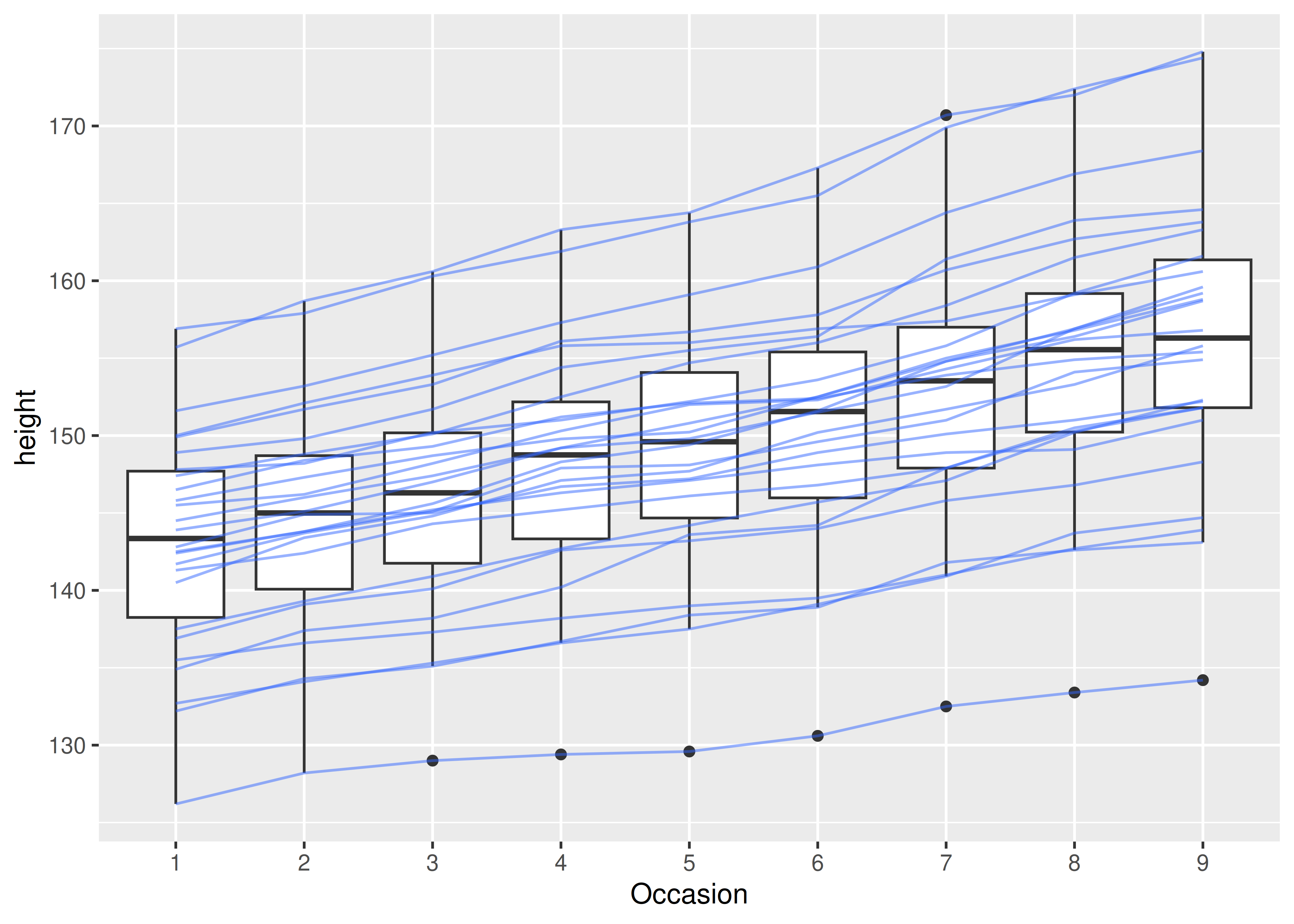
4.4 Combinar la estética con los objetos gráficos
Una última cuestión importante con las geomas colectivas es cómo la estética de las observaciones individuales se relaciona con la estética de la entidad completa. ¿Qué sucede cuando se asignan diferentes estéticas a un solo elemento geométrico?
En ggplot2, esto se maneja de manera diferente para diferentes geoms colectivas. Las líneas y caminos operan según el principio de “primer valor”: cada segmento está definido por dos observaciones, y ggplot2 aplica el valor estético (por ejemplo, color) asociado con la primera observación al dibujar el segmento. Es decir, la estética de la primera observación se utiliza al dibujar el primer segmento, la segunda observación se utiliza al dibujar el segundo segmento y así sucesivamente. No se utiliza el valor estético de la última observación:
df <- data.frame(x = 1:3, y = 1:3, colour = c(1, 3, 5))
ggplot(df, aes(x, y, colour = factor(colour))) +
geom_line(aes(group = 1), linewidth = 2) +
geom_point(size = 5)
ggplot(df, aes(x, y, colour = colour)) +
geom_line(aes(group = 1), linewidth = 2) +
geom_point(size = 5)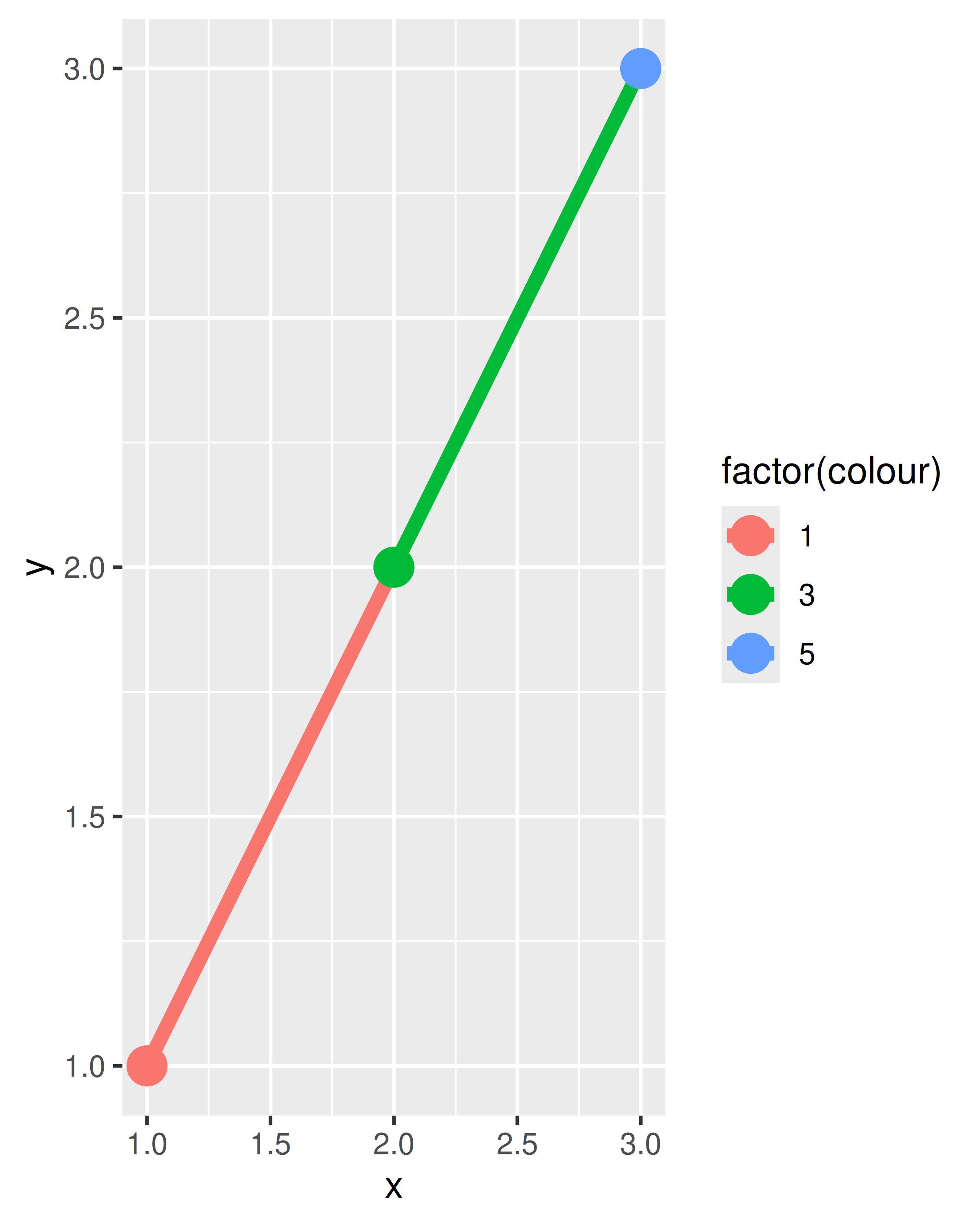
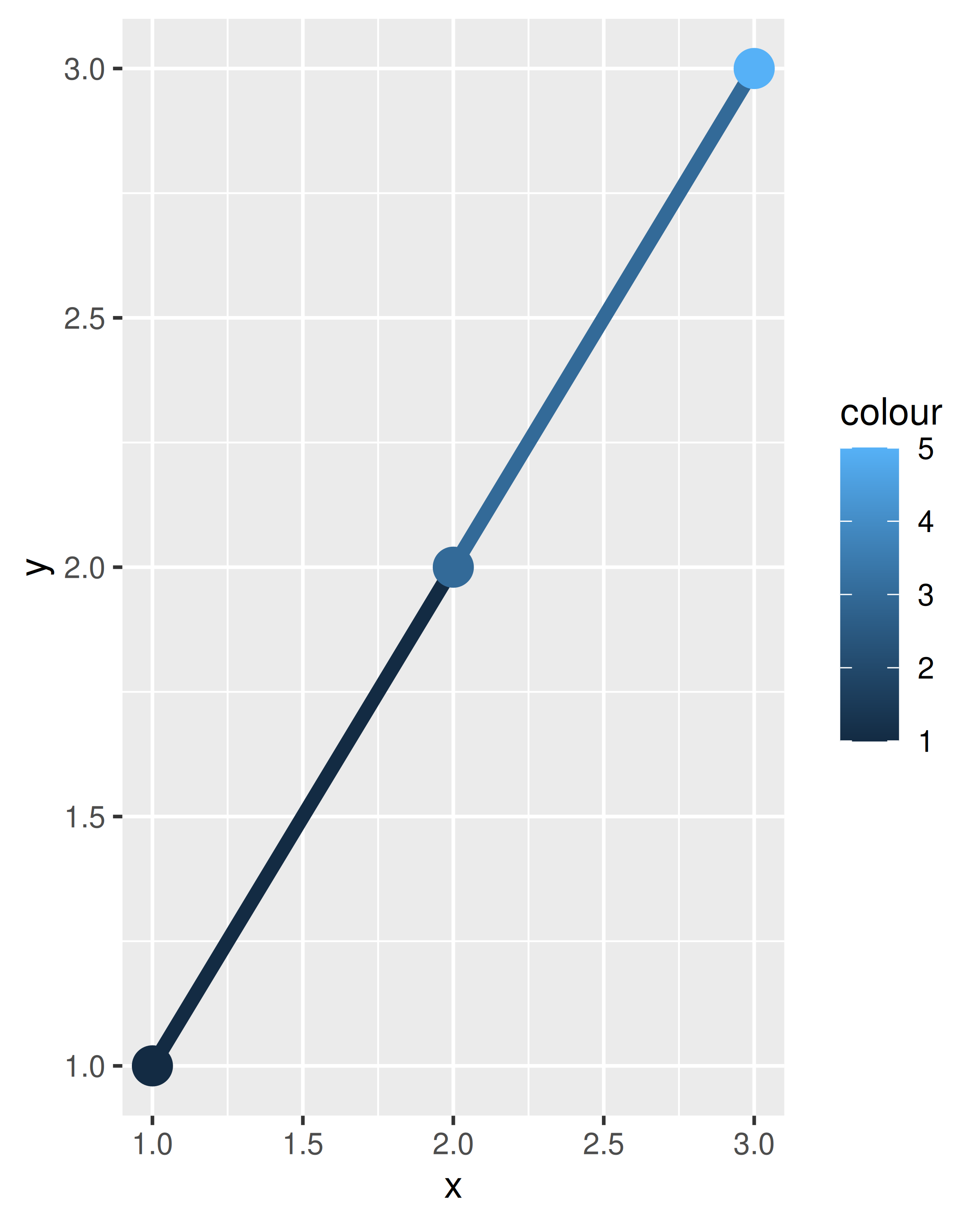
A la izquierda, donde el color es discreto, el primer punto y el primer segmento de línea son rojos, el segundo punto y el segundo segmento de línea son verdes y el punto final (sin segmento correspondiente) es azul. A la derecha, donde el color es continuo, se aplica el mismo principio a los tres tonos diferentes de azul. Tenga en cuenta que, aunque la variable de color es continua, ggplot2 no combina suavemente de un valor estético a otro. Si este es el comportamiento que deseas, puedes realizar la interpolación lineal tú mismo:
xgrid <- with(df, seq(min(x), max(x), length = 50))
interp <- data.frame(
x = xgrid,
y = approx(df$x, df$y, xout = xgrid)$y,
colour = approx(df$x, df$colour, xout = xgrid)$y
)
ggplot(interp, aes(x, y, colour = colour)) +
geom_line(linewidth = 2) +
geom_point(data = df, size = 5)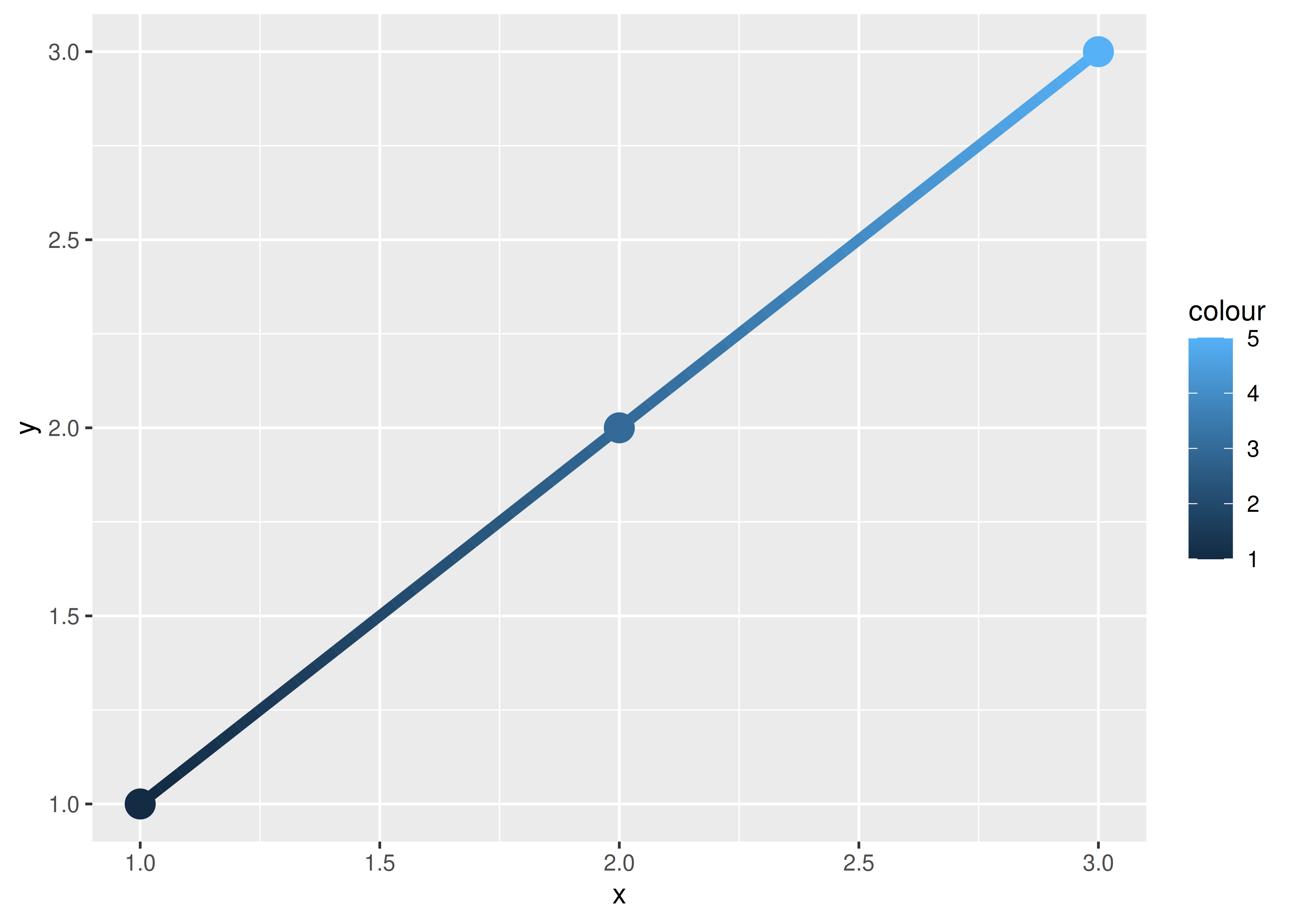
Vale la pena señalar una limitación adicional para rutas y líneas: el tipo de línea debe ser constante en cada línea individual. En R no hay forma de dibujar una línea que tenga diferentes tipos de línea.
¿Qué pasa con otras geomas colectivas, como los polígonos? La mayoría de las geomas colectivas son más complicadas que las líneas y los caminos, y un solo objeto geométrico puede corresponder a muchas observaciones. En tales casos no resulta obvio cómo combinar la estética de las observaciones individuales. Por ejemplo, ¿cómo colorearías un polígono que tuviera un color de relleno diferente para cada punto de su borde? Debido a esta ambigüedad, ggplot2 adopta una regla simple: la estética de los componentes individuales se usa solo si todos son iguales. Si la estética difiere para cada componente, ggplot2 usa un valor predeterminado.
Estas cuestiones son más relevantes cuando se asigna la estética a variables continuas. Para variables discretas, el comportamiento predeterminado de ggplot2 es tratar la variable como parte de la estética del grupo, como se describió anteriormente. Esto tiene el efecto de dividir la geom colectiva en pedazos más pequeños. Esto funciona particularmente bien para gráficos de barras y áreas, porque al apilar las piezas individuales se produce la misma forma que los datos originales desagrupados:
ggplot(mpg, aes(class)) +
geom_bar()
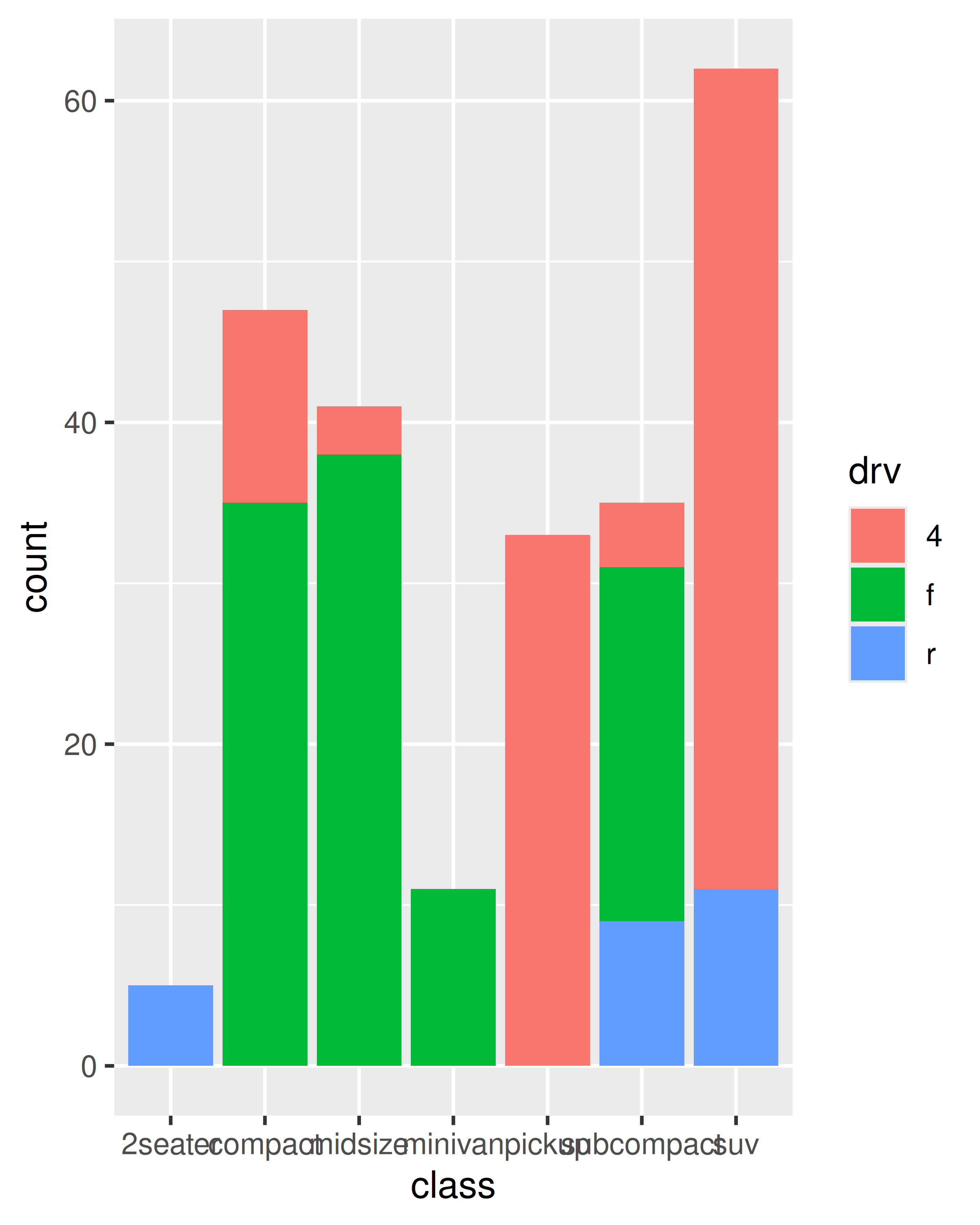
ggplot(mpg, aes(class, fill = drv)) +
geom_bar()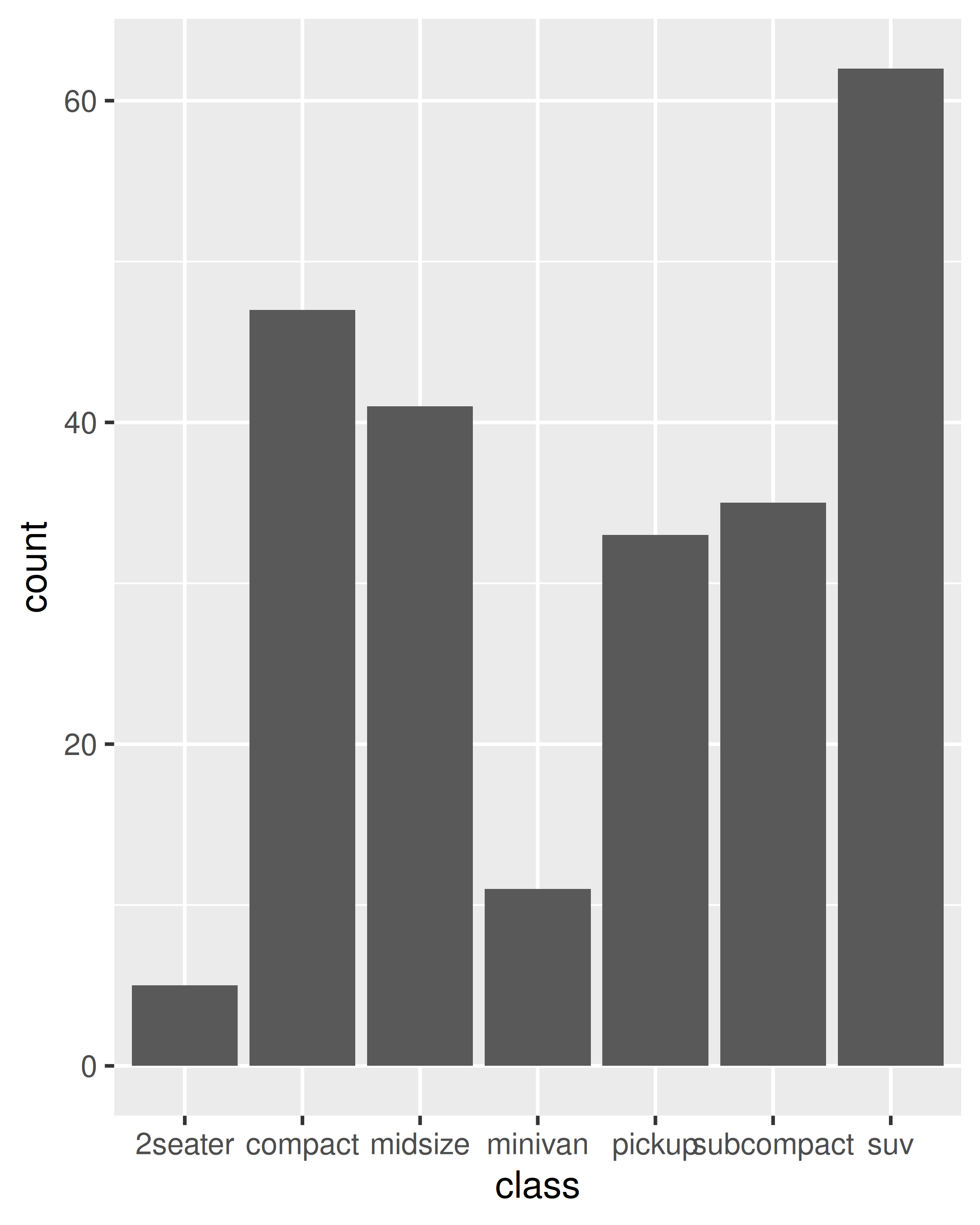
Si intenta asignar la estética del relleno a una variable continua (por ejemplo, hwy) de la misma manera, no funciona. La agrupación predeterminada solo se basará en class, por lo que cada barra ahora está asociada con varios colores (dependiendo del valor de hwy para las observaciones en cada clase). Debido a que una barra solo puede mostrar un color, ggplot2 vuelve al gris predeterminado en este caso. Para mostrar varios colores, necesitamos varias barras para cada class, que podemos obtener anulando la agrupación:
ggplot(mpg, aes(class, fill = hwy)) +
geom_bar()
#> Warning: The following aesthetics were dropped during statistical transformation: fill.
#> ℹ This can happen when ggplot fails to infer the correct grouping structure in
#> the data.
#> ℹ Did you forget to specify a `group` aesthetic or to convert a numerical
#> variable into a factor?
ggplot(mpg, aes(class, fill = hwy, group = hwy)) +
geom_bar()
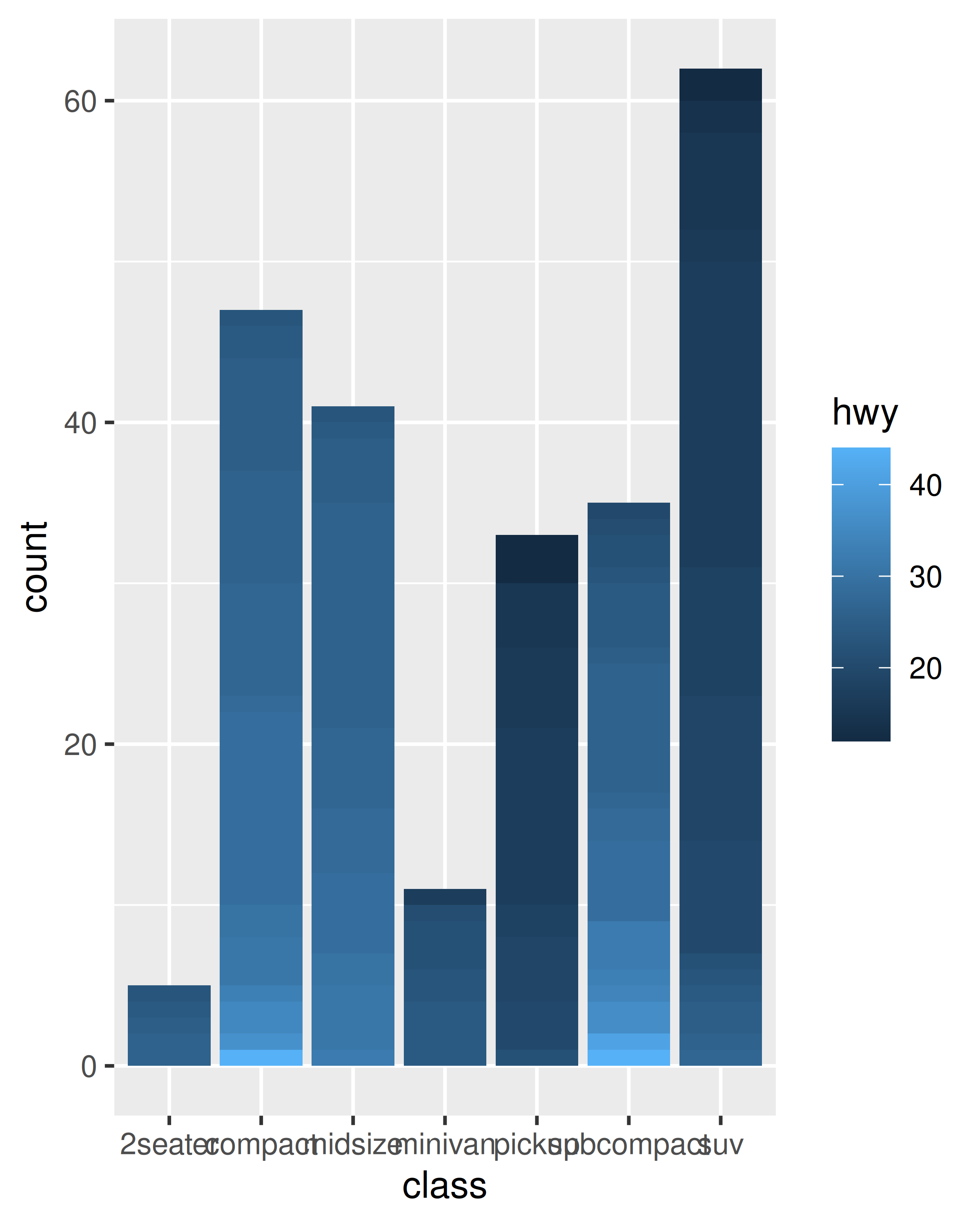
En el gráfico de la derecha, las “barras sombreadas” para cada class se construyeron apilando muchas barras distintas una encima de la otra, cada una rellena con un tono diferente según el valor de hwy. Tenga en cuenta que cuando hace esto, las barras se apilan en el orden definido por la variable de agrupación (en este ejemplo, hwy). Si necesita un control preciso sobre este comportamiento, deberá crear un factor con niveles ordenados según sea necesario.
4.5 Ejercicios
Dibuja un diagrama de caja de
hwypara cada valor decyl, sin convertircylen un factor. ¿Qué estética extra necesitas configurar?-
Modifique el siguiente gráfico para obtener un diagrama de caja por valor entero de
displ.ggplot(mpg, aes(displ, cty)) + geom_boxplot() Al ilustrar la diferencia entre asignar colores continuos y discretos a una línea, el ejemplo discreto necesitaba
aes (grupo = 1). ¿Por qué? ¿Qué pasa si eso se omite? ¿Cuál es la diferencia entreaes(grupo = 1)yaes(grupo = 2)? ¿Por qué?-
¿Cuántas barras hay en cada una de las siguientes gráficas?
(Sugerencia: intente agregar un contorno alrededor de cada barra con
colour = "white") -
Instale el paquete babynames. Contiene datos sobre la popularidad de los nombres de bebés en Estados Unidos. Ejecute el siguiente código y corrija el gráfico resultante. ¿Por qué este gráfico nos hace infelices?