theme_minimal <- function(base_size = 11,
base_family = "",
base_line_size = base_size/22,
base_rect_size = base_size/22) {
theme_bw(
base_size = base_size,
base_family = base_family,
base_line_size = base_line_size,
base_rect_size = base_rect_size
) %+replace%
theme(
axis.ticks = element_blank(),
legend.background = element_blank(),
legend.key = element_blank(),
panel.background = element_blank(),
panel.border = element_blank(),
strip.background = element_blank(),
plot.background = element_blank(),
complete = TRUE
)
}20 Extendiendo ggplot2
You are reading the work-in-progress third edition of the ggplot2 book. This chapter should be readable but is currently undergoing final polishing.
El paquete ggplot2 ha sido diseñado de una manera que hace que sea relativamente fácil ampliar la funcionalidad con nuevos tipos de componentes gramaticales comunes. El sistema de extensiones le permite distribuir estas extensiones como paquetes si así lo desea, pero la facilidad con la que se pueden crear extensiones significa que también es viable escribir extensiones únicas para resolver un desafío de trazado particular. Este capítulo analiza diferentes formas en que se puede ampliar ggplot2 y destaca cuestiones específicas a tener en cuenta. Presentaremos pequeños ejemplos a lo largo del capítulo, pero para ver un ejemplo trabajado de principio a fin, consulte Capítulo 21.
20.1 Nuevos temas
20.1.1 Modificando temas
Los temas son probablemente la forma más sencilla de extensiones, ya que solo requieren que escribas el código que normalmente escribirías al crear gráficos con ggplot2. Si bien es posible crear un nuevo tema desde cero, normalmente es más fácil y menos propenso a errores modificar un tema existente. Este enfoque se adopta a menudo en la fuente ggplot2. Por ejemplo, aquí está el código fuente de theme_minimal():
Como puede ver, el código no se ve muy diferente al código que normalmente escribe cuando diseña un gráfico (?sec-polish). La función theme_minimal() usa theme_bw() como tema base y luego reemplaza ciertas partes con su propio estilo usando el operador %+replace%. Al escribir temas nuevos, es una buena idea proporcionar algunos parámetros al usuario para definir aspectos generales del tema. Un aspecto importante es el tamaño del texto y las líneas, pero otros aspectos podrían ser, p.e. colores clave y de acento del tema. Por ejemplo, podríamos crear una variante de theme_minimal() que permita al usuario especificar el color de fondo de la trama:
theme_background <- function(background = "white", ...) {
theme_minimal(...) %+replace%
theme(
plot.background = element_rect(
fill = background,
colour = background
),
complete = TRUE
)
}
base <- ggplot(mpg, aes(displ, hwy)) + geom_point()
base + theme_minimal(base_size = 14)
base + theme_background(base_size = 14)
base + theme_background(base_size = 14, background = "grey70")
20.1.2 Temas completos
Un punto importante a tener en cuenta es el uso de complete = TRUE en el código para theme_minimal() y theme_background(). Siempre es una buena práctica hacer esto al definir sus propios temas en un paquete de extensión ggplot2: esto asegurará que su tema se comporte de la misma manera que el tema predeterminado y, como consecuencia, será menos probable que sorprenda a los usuarios. Para ver por qué esto es necesario, compare estos dos temas:
# Bueno
theme_predictable <- function(...) {
theme_classic(...) %+replace%
theme(
axis.line.x = element_line(color = "blue"),
axis.line.y = element_line(color = "orange"),
complete = TRUE
)
}
# malo
theme_surprising <- function(...) {
theme_classic(...) %+replace%
theme(
axis.line.x = element_line(color = "blue"),
axis.line.y = element_line(color = "orange")
)
}Ambos temas están destinados a hacer lo mismo: cambiar los valores predeterminados a theme_classic() para que el eje x se dibuje con una línea azul y el eje y se dibuje con una línea naranja. A primera vista, parece que ambas versiones se comportan según las expectativas del usuario:
base + theme_classic()
base + theme_predictable()
base + theme_surprising()
Sin embargo, supongamos que el usuario de su tema quiere eliminar las líneas del eje:
base + theme_classic() + theme(axis.line = element_blank())
base + theme_predictable() + theme(axis.line = element_blank())
base + theme_surprising() + theme(axis.line = element_blank())
El comportamiento de theme_predictable() es el mismo que theme_classic() y las líneas del eje se eliminan, pero para theme_surprising() esto no sucede. La razón de esto es que ggplot2 trata los temas completos como una colección de valores “de respaldo”: cuando el usuario agrega theme(axis.line = element_blank()) a un tema completo, no hay necesidad de confiar en el valor de respaldo para axis.line.x o axis.line.y, porque se heredan de axis.line en el comando de usuario. Esto es una amabilidad para sus usuarios, ya que les permite sobrescribir todo lo que hereda de axis.line usando un comando como theme_predictable() + theme(axis.line = ...). Por el contrario, theme_surprising() no especifica un tema completo. Cuando el usuario llama a theme_surprising(), los valores alternativos se toman de theme_classic(), pero lo más importante es que ggplot2 trata el comando theme() que establece axis.line.x y axis.line.y exactamente como si el usuario lo hubiera escrito. En consecuencia, la especificación de la trama es equivalente a esto:
base +
theme_classic() +
theme(
axis.line.x = element_line(color = "blue"),
axis.line.y = element_line(color = "orange"),
axis.line = element_blank()
)
En este código, se aplica la regla de herencia específica primero y, como tal, la configuración axis.line no anula la regla más específica axis.line.x.
20.1.3 Definición de elementos del tema
En ?sec-polising vimos que la estructura de un tema ggplot2 está definida por el árbol de elementos. El árbol de elementos especifica qué tipo tiene cada elemento del tema y de dónde hereda su valor (puede usar la función get_element_tree() para devolver este árbol como una lista). El sistema de extensión para ggplot2 hace posible definir nuevos elementos de tema registrándolos como parte del árbol de elementos usando la función register_theme_elements(). Digamos que estás escribiendo un nuevo paquete llamado “ggxyz” que incluye una anotación de panel como parte del sistema de coordenadas y quieres que esta anotación de panel sea un elemento del tema:
register_theme_elements(
ggxyz.panel.annotation = element_text(
color = "blue",
hjust = 0.95,
vjust = 0.05
),
element_tree = list(
ggxyz.panel.annotation = el_def(
class = "element_text",
inherit = "text"
)
)
)Hay dos puntos a tener en cuenta aquí al definir nuevos elementos temáticos en un paquete:
Es importante llamar a
register_theme_elements()desde la función.onLoad()de tu paquete, para que los nuevos elementos del tema estén disponibles para cualquiera que use funciones de tu paquete, independientemente de si el paquete se ha adjuntado.Siempre es una buena idea incluir el nombre de su paquete como prefijo para cualquier elemento nuevo del tema. De esa manera, si alguien más escribe un paquete de anotaciones de panel
ggabc, no habrá conflicto potencial entre los elementos del temaggxyz.panel.annotationyggabc.panel.annotation.
Una vez que se haya actualizado el árbol de elementos, el paquete puede definir un nuevo sistema de coordenadas que utilice el nuevo elemento temático. Una forma sencilla de hacer esto es definir una función que cree una nueva instancia del objeto ggproto CoordCartesian. Hablaremos más sobre esto en Sección 20.4, pero por ahora basta con tener en cuenta que este código funcionará:
coord_annotate <- function(label = "panel annotation") {
ggproto(NULL, CoordCartesian,
limits = list(x = NULL, y = NULL),
expand = TRUE,
default = FALSE,
clip = "on",
render_fg = function(panel_params, theme) {
element_render(
theme = theme,
element = "ggxyz.panel.annotation",
label = label
)
}
)
}Entonces ahora esto funciona:
base + coord_annotate("annotation in blue")
base + coord_annotate("annotation in blue") + theme_dark()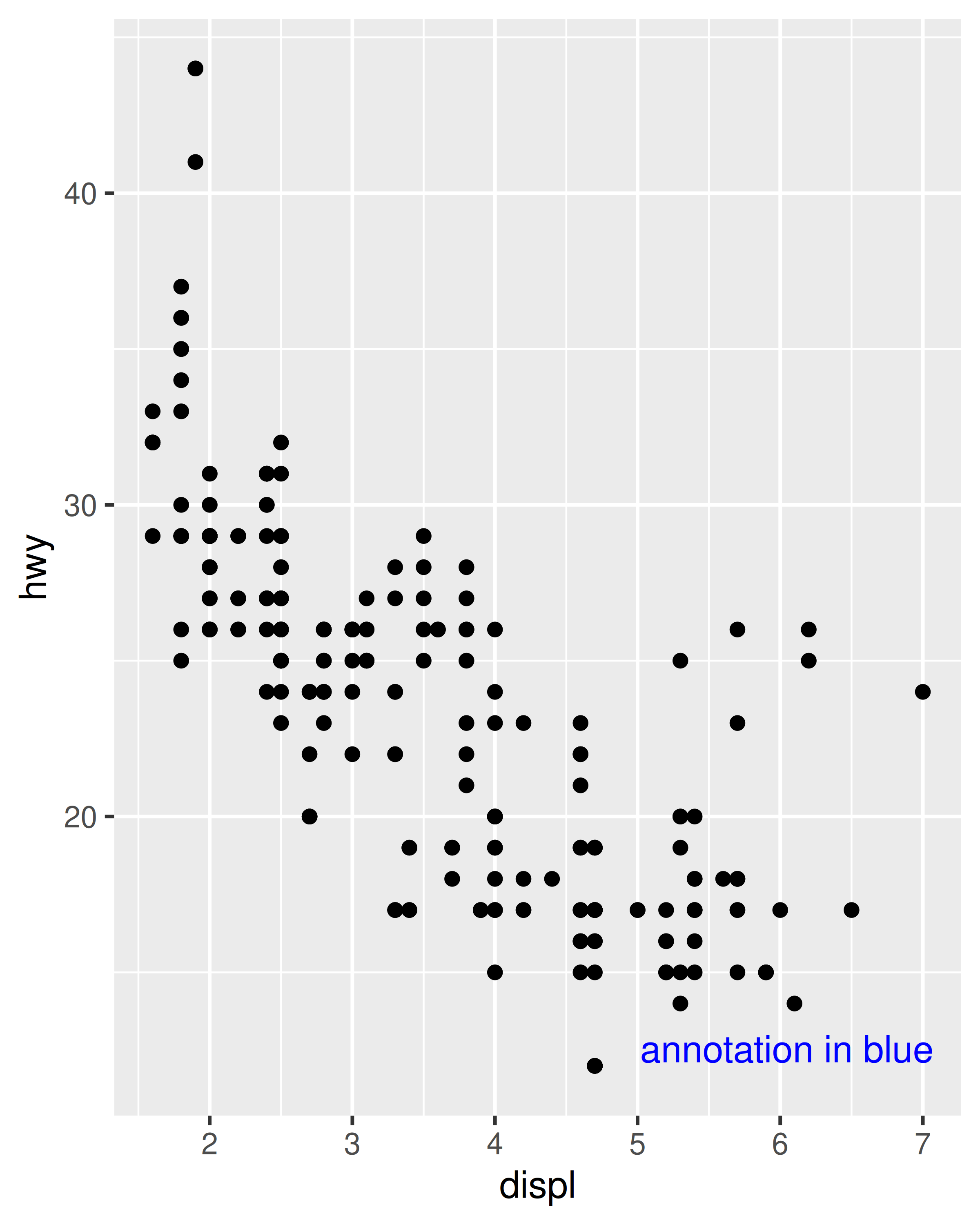
Habiendo modificado el árbol de elementos, vale la pena mencionar que la función reset_theme_settings() restaura el árbol de elementos predeterminado, descarta todas las definiciones de elementos nuevos y (a menos que esté desactivada) restablece el tema actualmente activo al valor predeterminado.
20.2 Nuevas estadísticas
Puede parecer sorprendente, pero crear nuevas estadísticas es una de las formas más útiles de ampliar las capacidades de ggplot2. Cuando los usuarios agregan nuevas capas a un gráfico, con mayor frecuencia usan una función geom, por lo que es tentador como desarrollador pensar que su extensión ggplot2 debería encapsularse como una nueva geom. Hasta cierto punto, esto es cierto, ya que sus usuarios probablemente querrán usar una función de geom, pero en realidad la variedad entre diferentes geoms se debe principalmente a la variedad de diferentes estadísticas. Uno de los beneficios de trabajar con estadísticas es que se trata únicamente de transformaciones de datos. La mayoría de los usuarios y desarrolladores de R se sienten muy cómodos con la transformación de datos, lo que facilita la tarea de definir una nueva estadística. Siempre que el comportamiento deseado pueda encapsularse en una estadística, no hay necesidad de manipular ninguna llamada a la grilla.
20.2.1 Creando estadísticas
Como se analiza en Capítulo 19, el comportamiento principal de una estadística se captura mediante una sucesión escalonada de llamadas a compute_layer(), compute_panel() y compute_group(), todos los cuales son métodos asociados con el Objeto ggproto que define la estadística. De forma predeterminada, las dos funciones principales no hacen mucho, simplemente dividen los datos y luego los pasan a la siguiente función:
-
compute_layer()divide los datos establecidos por la columnaPANEL, llama acompute_panel()y vuelve a ensamblar los resultados. -
compute_panel()divide los datos del panel por la columnagroup, llama acompute_group()y vuelve a ensamblar los resultados.
Debido a esto, el único método que normalmente necesitas especificar como desarrollador es la función compute_group(), cuyo trabajo es tomar los datos de un único grupo y transformarlos apropiadamente. Esto será suficiente para crear una estadística funcional, aunque es posible que no produzca el mejor rendimiento. Como consecuencia, a veces los desarrolladores encuentran valioso descargar parte del trabajo a compute_panel() siempre que sea posible: hacerlo permite vectorizar los cálculos y evitar un costoso paso de división-combinación (veremos un ejemplo de esto más adelante en (seg-primavera-estadística?)). Sin embargo, como regla general es mejor comenzar modificando compute_group() únicamente y ver si el rendimiento es el adecuado.
Para ilustrar esto, comenzaremos creando una estadística que calcule el casco convexo de un conjunto de puntos, usando la función chull() incluida en grDevices. Como es de esperar, la mayor parte del trabajo lo realiza un nuevo objeto ggproto que crearemos:
Como se describe en Sección 19.4, los dos primeros argumentos de ggproto() se usan para indicar que este objeto define una nueva clase (convenientemente llamada "StatChull") que hereda campos y métodos del objeto Stat. Luego especificamos solo aquellos campos y métodos que deben modificarse con respecto a los valores predeterminados proporcionados por Stat, en este caso compute_group() y required_aes. Nuestra función compute_group() toma dos entradas, data y scales—porque esto es lo que ggplot2 espera—pero el cálculo real depende sólo de los data. Tenga en cuenta que debido a que el cálculo necesariamente requiere que ambas estéticas de posición estén presentes, también hemos especificado el campo required_aes para asegurarnos de que ggplot2 sepa que estas estéticas son requeridas.
Al crear este objeto ggproto tenemos una estadística funcional, pero aún no le hemos dado al usuario una forma de acceder a ella. Para solucionar esto escribimos una función de capa, stat_chull(). Todas las funciones de capa tienen la misma forma: usted especifica los valores predeterminados en los argumentos de la función y luego llama a layer(), enviando ... al argumento params. Los argumentos en ... serán argumentos para la geom (si estás creando un contenedor de estadísticas), argumentos para la estadística (si estás creando un contenedor de geom) o la estética que se establecerá. layer() se encarga de separar los diferentes parámetros y asegurarse de que estén almacenados en el lugar correcto. Entonces nuestra función stat_chull() se ve así
stat_chull <- function(mapping = NULL, data = NULL,
geom = "polygon", position = "identity",
na.rm = FALSE, show.legend = NA,
inherit.aes = TRUE, ...) {
layer(
stat = StatChull,
data = data,
mapping = mapping,
geom = geom,
position = position,
show.legend = show.legend,
inherit.aes = inherit.aes,
params = list(na.rm = na.rm, ...)
)
}y nuestra estadística ahora se puede utilizar en gráficos:
ggplot(mpg, aes(displ, hwy)) +
geom_point() +
stat_chull(fill = NA, colour = "black")
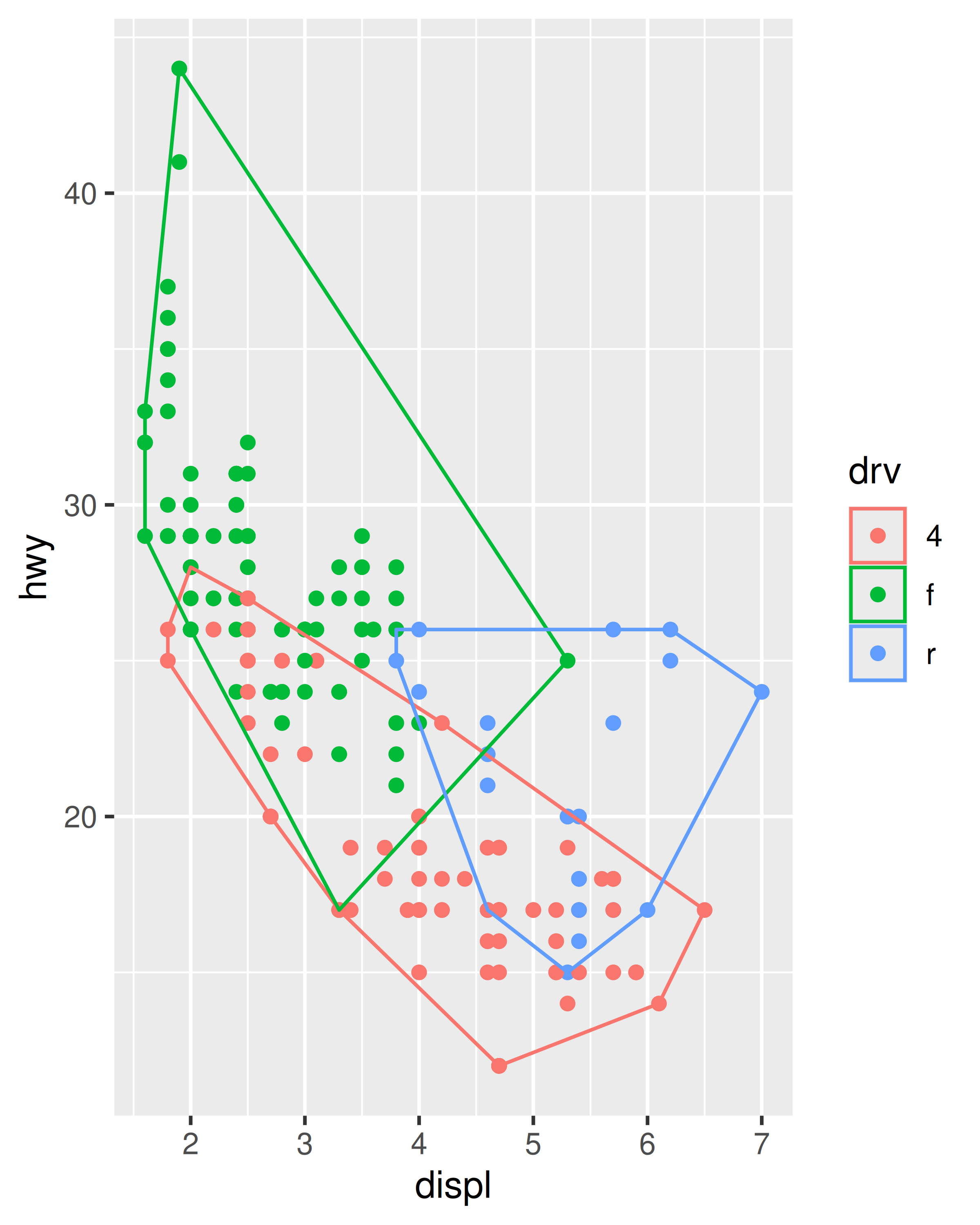
ggplot(mpg, aes(displ, hwy, colour = drv)) +
geom_point() +
stat_chull(fill = NA)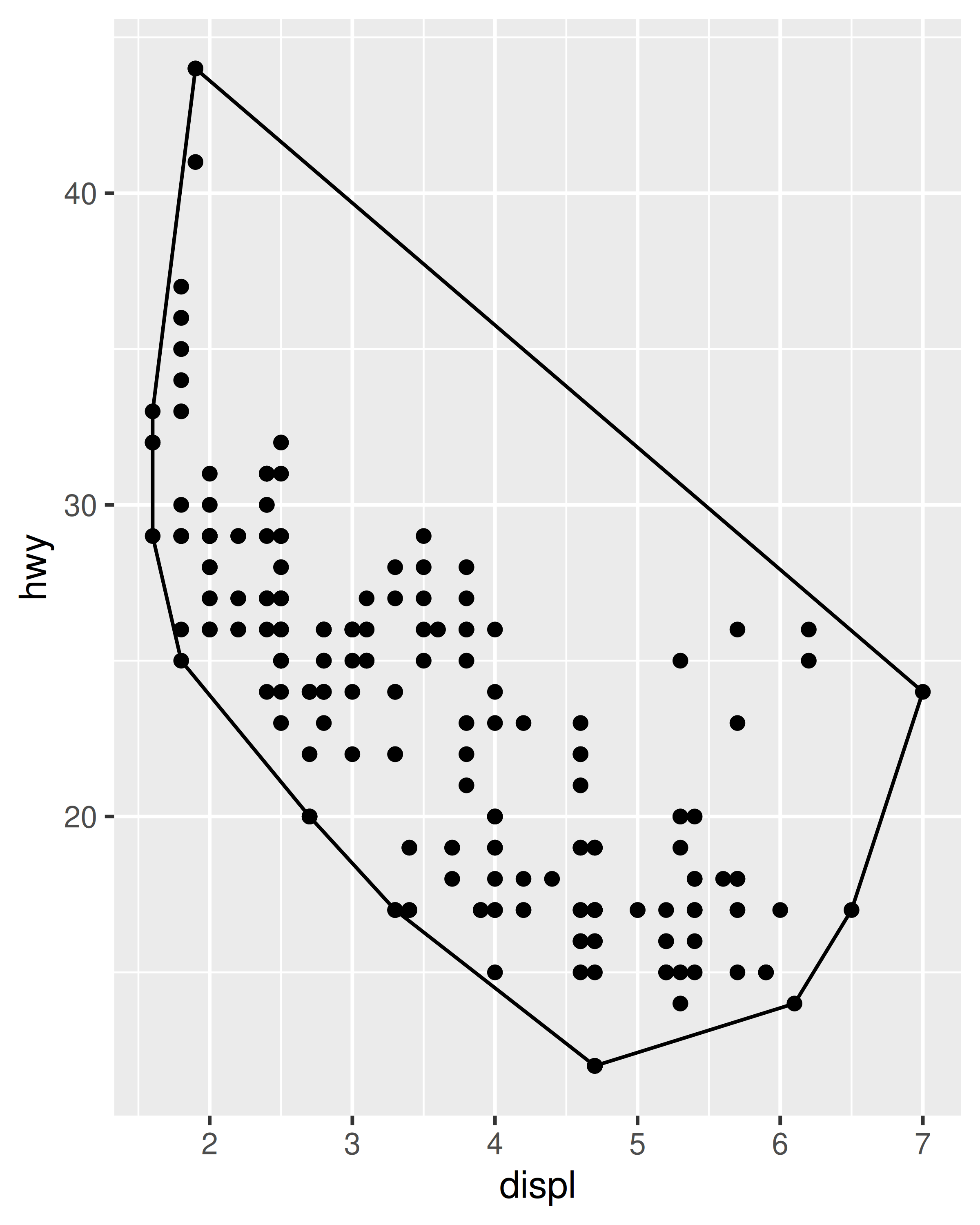
Al crear nuevas estadísticas, suele ser una buena idea proporcionar un constructor geom_*() adjunto, así como el constructor stat_*(), porque la mayoría de los usuarios están acostumbrados a agregar capas de trazado con geoms en lugar de estadísticas. Mostraremos cómo se vería una función geom_chull() en Sección 20.3.
Tenga en cuenta que no siempre es posible definir el constructor geom_*() de forma sensata. Esto puede suceder cuando no hay una geom predeterminada obvia para la nueva estadística, o si la estadística pretende ofrecer una ligera modificación a un par de geom/stat existente. En tales casos, puede ser aconsejable proporcionar sólo una función stat_*().
20.2.2 Modificar parámetros y datos
Al definir nuevas estadísticas, a menudo es necesario especificar las funciones setup_params() y/o setup_data(). Estos se llaman antes de las funciones compute_*() y permiten que la estadística reaccione y se modifique en respuesta a los parámetros y datos (especialmente los datos, ya que no están disponibles cuando se construye la estadística):
- Primero se llama a la función
setup_params(). Toma dos argumentos correspondientes a la capadatay una lista de parámetros (params) especificados durante la construcción, y devuelve una lista modificada de parámetros que se utilizarán en cálculos posteriores. Debido a que los parámetros son utilizados por las funcionescompute_*(), los elementos de la lista deben corresponder a los nombres de los argumentos en las funcionescompute_*()para que estén disponibles. - A continuación se llama a la función
setup_data(). También tomadatayparamscomo entrada, aunque los parámetros que recibe son los parámetros modificados devueltos desdesetup_params(), y devuelve los datos de la capa modificada. Es importante que no importa qué modificaciones ocurran ensetup_data()las columnasPANELygrouppermanezcan intactas.
En el siguiente ejemplo, mostramos cómo utilizar el método setup_params() para definir una nueva estadística. Más adelante se incluye un ejemplo de modificación del método setup_data(), en Sección 20.3.2.
Supongamos que queremos crear StatDensityCommon, una estadística que calcula una estimación de densidad de una variable después de estimar un ancho de banda predeterminado para aplicar a todos los grupos de los datos. Esto se puede hacer de muchas maneras diferentes, pero para simplificar, imaginemos que tenemos una función common_bandwidth() que estima el ancho de banda por separado para cada grupo usando la función bw.nrd0() y luego devuelve el promedio:
Lo que queremos de StatDensityCommon es usar la función common_bandwith() para establecer un ancho de banda común antes de que los datos se separen por grupo y se pasen a la función compute_group(). Aquí es donde el método setup_params() resulta útil:
StatDensityCommon <- ggproto("StatDensityCommon", Stat,
required_aes = "x",
setup_params = function(data, params) {
if(is.null(params$bandwith)) {
params$bandwidth <- common_bandwidth(data)
message("Picking bandwidth of ", signif(params$bandwidth, 3))
}
return(params)
},
compute_group = function(data, scales, bandwidth = 1) {
d <- density(data$x, bw = bandwidth)
return(data.frame(x = d$x, y = d$y))
}
)Luego definimos una función stat_*() de la forma habitual:
stat_density_common <- function(mapping = NULL, data = NULL,
geom = "line", position = "identity",
na.rm = FALSE, show.legend = NA,
inherit.aes = TRUE, bandwidth = NULL, ...) {
layer(
stat = StatDensityCommon,
data = data,
mapping = mapping,
geom = geom,
position = position,
show.legend = show.legend,
inherit.aes = inherit.aes,
params = list(
bandwidth = bandwidth,
na.rm = na.rm,
...
)
)
}Ahora podemos aplicar nuestra nueva estadística
ggplot(mpg, aes(displ, colour = drv)) +
stat_density_common()
#> Picking bandwidth of 0.345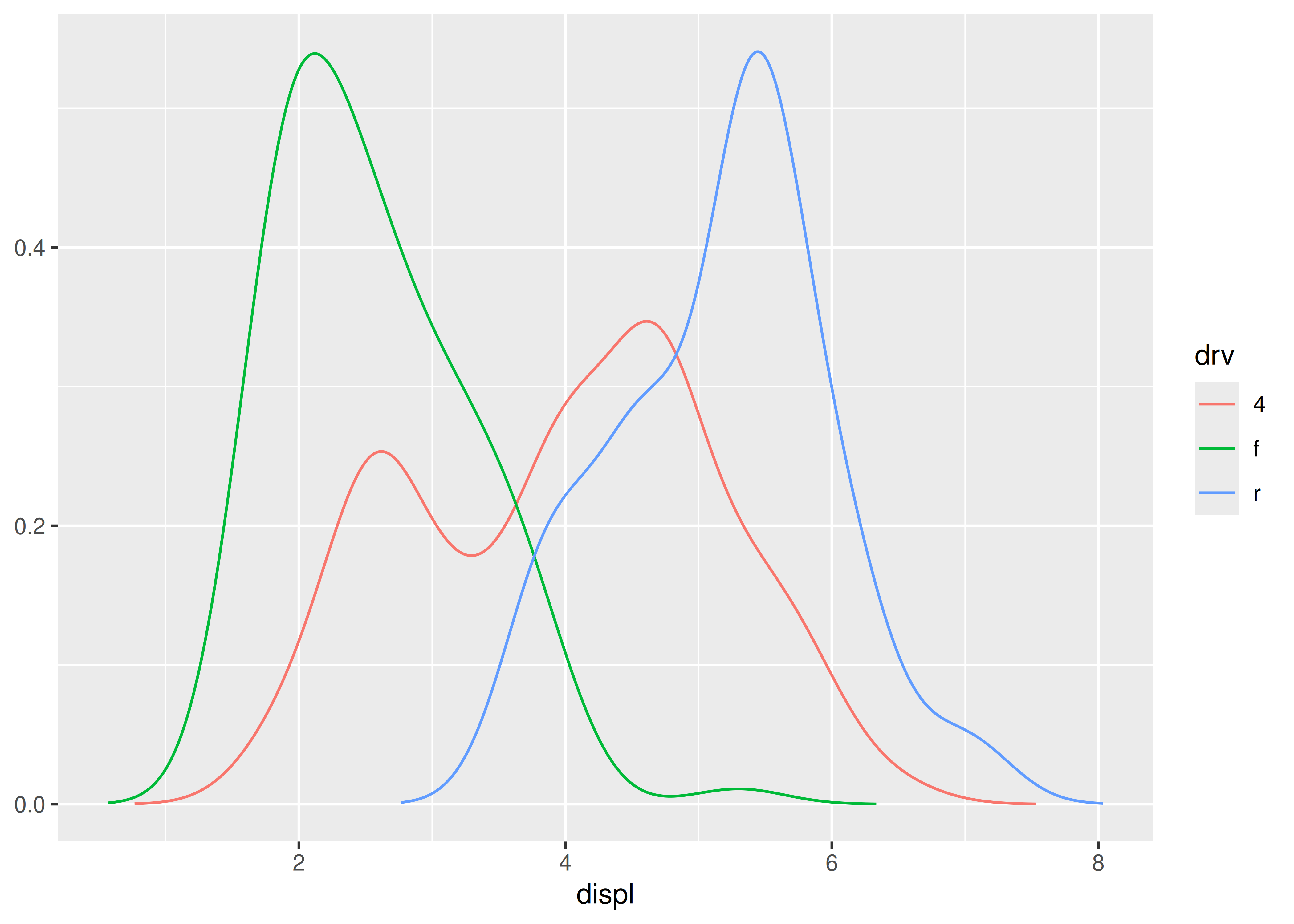
20.3 Nuevos geoms
Si bien se pueden lograr muchas cosas creando nuevas estadísticas, hay situaciones en las que es necesario crear una nueva geom. Algunos de estos son
- No tiene sentido devolver datos de la estadística en una forma que sea comprensible para cualquier geom actual.
- La capa necesita combinar la salida de múltiples geoms.
- La geom necesita devolver grobs que actualmente no están disponibles en las geoms existentes.
Crear nuevas geoms puede resultar un poco más desalentador que crear nuevas estadísticas, ya que el resultado final es una colección de grobs en lugar de un marco de datos modificado y esto es algo fuera de la zona de confort de muchos desarrolladores. Aún así, aparte del último punto anterior, es posible arreglárselas sin tener que pensar demasiado en la cuadrícula y los grobs.
20.3.1 Modificar los valores predeterminados de la geom
En muchas situaciones, su nueva geom puede ser simplemente una geom existente que espera entradas ligeramente diferentes o tiene valores de parámetros predeterminados diferentes. El ejemplo stat_chull() de la sección anterior es un buen ejemplo de esto. Tenga en cuenta que al crear gráficos usando stat_chull() teníamos que especificar manualmente los parámetros fill y color si no estaban asignados a la estética. La razón de esto es que GeomPolygon crea un polígono relleno sin bordes de forma predeterminada, y esto no se adapta bien a las necesidades de nuestra geom de casco convexo. Para hacernos la vida un poco más fácil, podemos crear una subclase de GeomPolygon que modifique los valores predeterminados para que produzca un polígono hueco de forma predeterminada. Podemos hacer esto de forma sencilla anulando el valor default_aes:
GeomPolygonHollow <- ggproto("GeomPolygonHollow", GeomPolygon,
default_aes = aes(
colour = "black",
fill = NA,
linewidth = 0.5,
linetype = 1,
alpha = NA
)
)Ahora podemos definir nuestra función constructora geom_chull() usando GeomPolygonHollow como geom predeterminado:
geom_chull <- function(mapping = NULL, data = NULL, stat = "chull",
position = "identity", na.rm = FALSE,
show.legend = NA, inherit.aes = TRUE, ...) {
layer(
geom = GeomPolygonHollow,
data = data,
mapping = mapping,
stat = stat,
position = position,
show.legend = show.legend,
inherit.aes = inherit.aes,
params = list(na.rm = na.rm, ...)
)
} En aras de la coherencia, también definiríamos stat_chull() para usarlo como valor predeterminado. En cualquier caso, ahora tenemos una nueva función geom_chull() que funciona bastante bien sin que el usuario necesite configurar parámetros:
ggplot(mpg, aes(displ, hwy)) +
geom_chull() +
geom_point()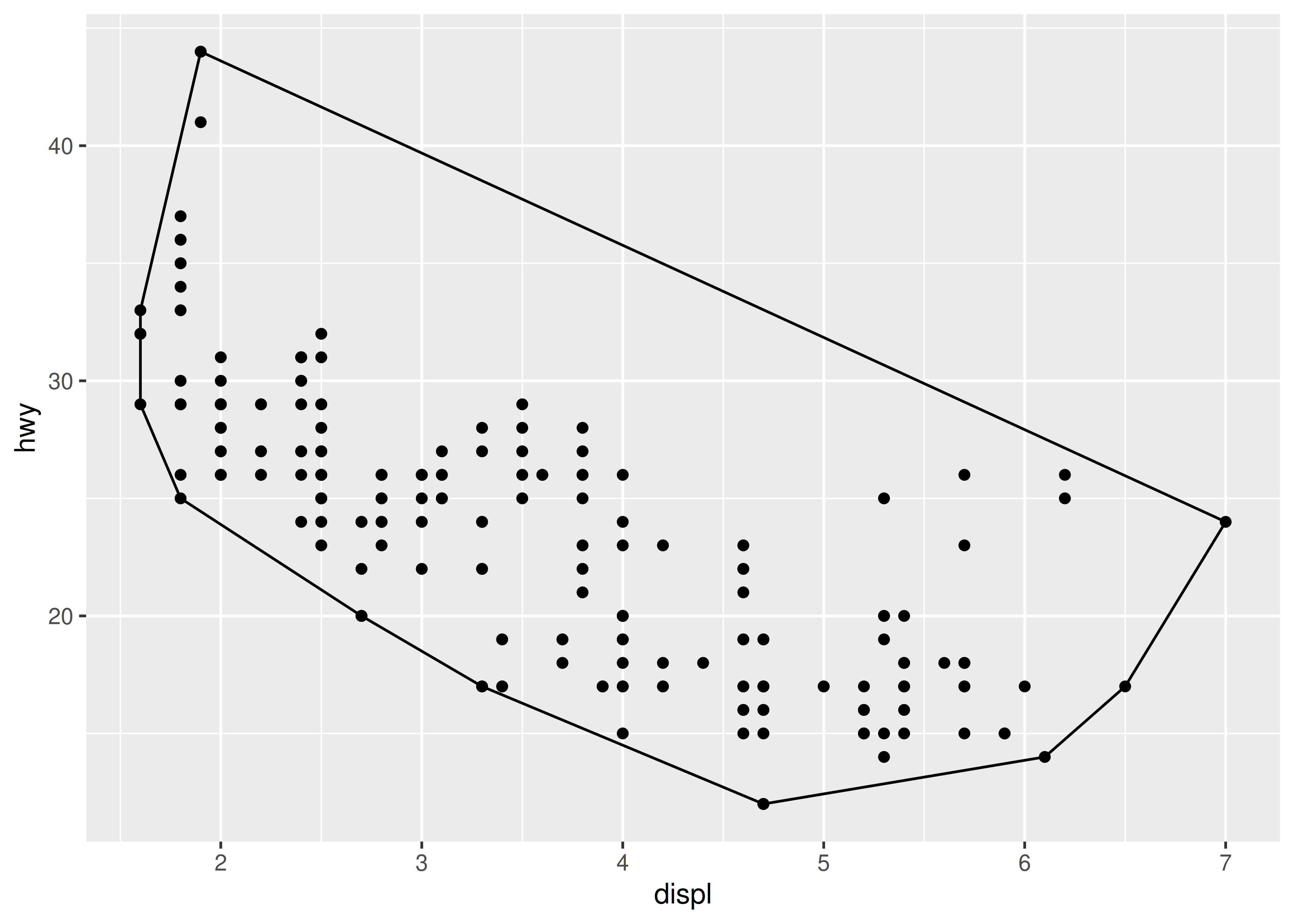
20.3.2 Modificando datos de geom
En otros casos, es posible que desee definir una geom que sea visualmente equivalente a una geom existente, pero que acepte datos en un formato diferente. Un ejemplo de esto en el código fuente de ggplot2 es geom_spoke(), una variación de geom_segment() que acepta datos en coordenadas polares. Para que esto funcione, el objeto ggproto GeomSpoke tiene una subclase de GeomSegment y utiliza el método setup_data() para tomar datos de coordenadas polares del usuario y luego transformarlos al formato que espera GeomSegment. Para ilustrar esta técnica, crearemos geom_spike(), una geom que vuelve a implementar la funcionalidad de geom_spoke(). Esto requiere que sobrescribamos el campo required_aes así como el método setup_data():
GeomSpike <- ggproto("GeomSpike", GeomSegment,
# Especificar la estética requerida
required_aes = c("x", "y", "angle", "radius"),
# Transforme los datos antes de realizar cualquier dibujo
setup_data = function(data, params) {
transform(data,
xend = x + cos(angle) * radius,
yend = y + sin(angle) * radius
)
}
)Ahora escribimos la función geom_spike() frente al usuario:
geom_spike <- function(mapping = NULL, data = NULL,
stat = "identity", position = "identity",
..., na.rm = FALSE, show.legend = NA,
inherit.aes = TRUE) {
layer(
data = data,
mapping = mapping,
geom = GeomSpike,
stat = stat,
position = position,
show.legend = show.legend,
inherit.aes = inherit.aes,
params = list(na.rm = na.rm, ...)
)
}Ahora podemos usar geom_spike() en los gráficos:
df <- data.frame(
x = 1:10,
y = 0,
angle = seq(from = 0, to = 2 * pi, length.out = 10),
radius = seq(from = 0, to = 2, length.out = 10)
)
ggplot(df, aes(x, y)) +
geom_spike(aes(angle = angle, radius = radius)) +
coord_equal()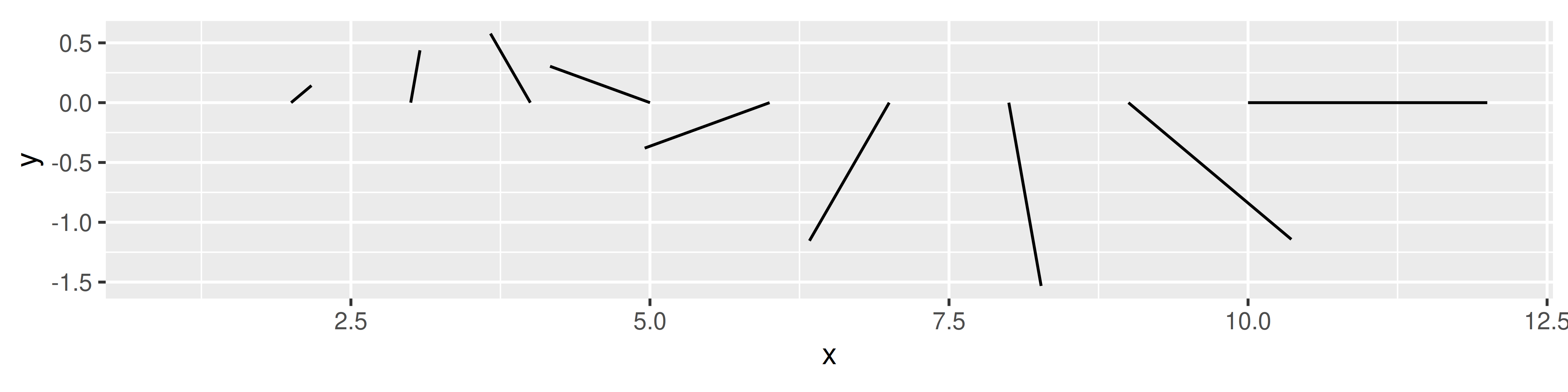
Al igual que con las estadísticas, las geoms tienen un método setup_params() además del método setup_data(), que se puede utilizar para modificar los parámetros antes de realizar cualquier dibujo (consulte Sección 20.2.2 para ver un ejemplo). Sin embargo, una cosa a tener en cuenta en el contexto geom es que se llama a setup_data() antes de realizar cualquier ajuste de posición.
20.3.3 Combinando múltiples geoms
Una técnica útil para definir nuevas geoms es combinar la funcionalidad de diferentes geoms. Por ejemplo, la función geom_smooth() para dibujar líneas de regresión no paramétricas usa la funcionalidad de geom_line() para dibujar la línea de regresión y geom_ribbon() para dibujar las bandas de error sombreadas. Para hacer esto dentro de su nueva geom, es útil considerar el proceso de dibujo. De la misma manera que una estadística funciona mediante una sucesión escalonada de llamadas a compute_layer(), luego a compute_panel() y finalmente a compute_group(), una geom se construye mediante llamadas a draw_layer(), draw_panel (), y draw_group().
Si desea combinar la funcionalidad de varias geoms, generalmente puede lograrlo preparando los datos para cada una de las geoms dentro de la llamada draw_*() y enviándolos a las diferentes geoms, recopilando la salida usando grid:: gList() cuando se necesita una lista de grobs o grid::gTree() si se requiere un único grob con varios hijos. Como ejemplo relativamente mínimo, considere el objeto ggproto GeomBarbell que crea geoms que constan de dos puntos conectados por una barra:
GeomBarbell <- ggproto("GeomBarbell", Geom,
required_aes = c("x", "y", "xend", "yend"),
default_aes = aes(
colour = "black",
linewidth = .5,
size = 2,
linetype = 1,
shape = 19,
fill = NA,
alpha = NA,
stroke = 1
),
draw_panel = function(data, panel_params, coord, ...) {
# Datos transformados para los puntos
point1 <- transform(data)
point2 <- transform(data, x = xend, y = yend)
# Devolver los tres componentes
grid::gList(
GeomSegment$draw_panel(data, panel_params, coord, ...),
GeomPoint$draw_panel(point1, panel_params, coord, ...),
GeomPoint$draw_panel(point2, panel_params, coord, ...)
)
}
) En este ejemplo, el método draw_panel() devuelve una lista de tres grobs, uno generado a partir de GeomSegment y dos de GeomPoint. Como es habitual, si queremos que la geom esté expuesta al usuario, agregamos una función contenedora:
geom_barbell <- function(mapping = NULL, data = NULL,
stat = "identity", position = "identity",
..., na.rm = FALSE, show.legend = NA,
inherit.aes = TRUE) {
layer(
data = data,
mapping = mapping,
stat = stat,
geom = GeomBarbell,
position = position,
show.legend = show.legend,
inherit.aes = inherit.aes,
params = list(na.rm = na.rm, ...)
)
}Ahora podemos utilizar la geom compuesta:
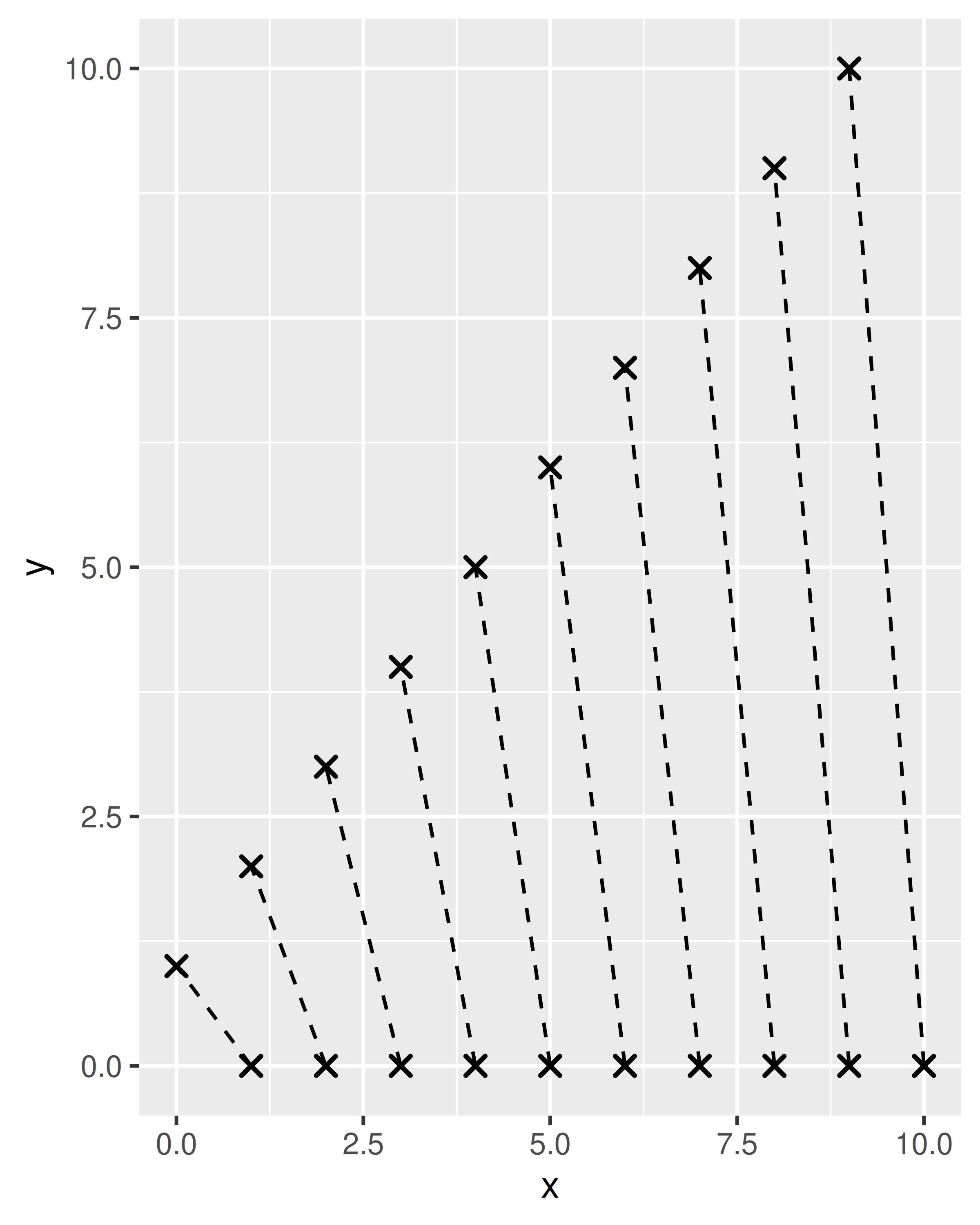
df <- data.frame(x = 1:10, xend = 0:9, y = 0, yend = 1:10)
base <- ggplot(df, aes(x, y, xend = xend, yend = yend))
base + geom_barbell()
base + geom_barbell(shape = 4, linetype = "dashed") 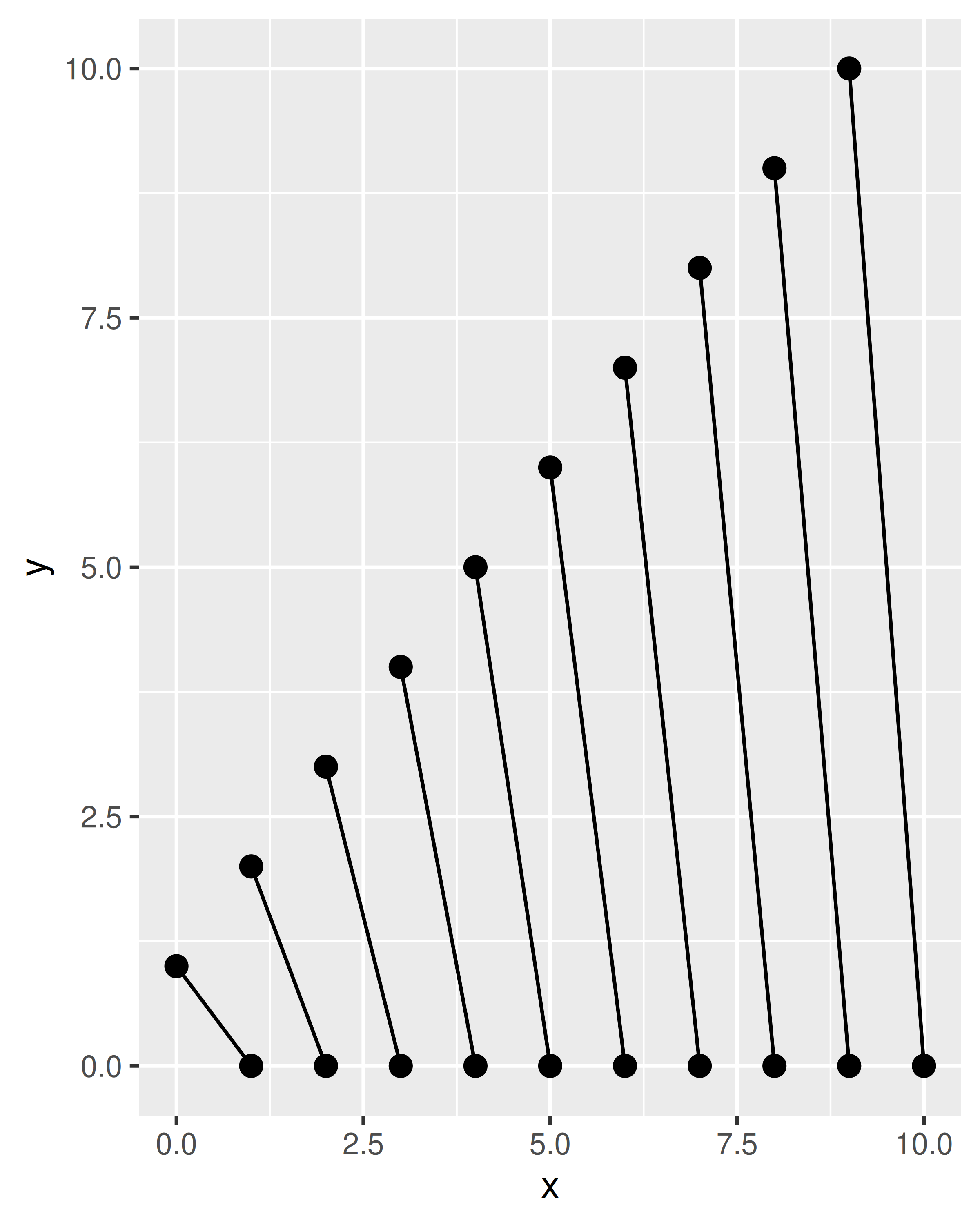
Si no puede aprovechar ninguna implementación de geom existente para crear los grobs, tendrá que implementar el método draw_*() completo desde cero, lo que requiere un poco más de comprensión del paquete grid. Para obtener más información sobre la cuadrícula y un ejemplo que usa esto para construir una geom a partir de primitivas de cuadrícula, consulte Capítulo 21.
20.4 Nuevas coordenadas
La función principal de la coord es reescalar la estética de la posición en el rango [0, 1], transformándola potencialmente en el proceso. Definir nuevas coordenadas es relativamente raro: las coordenadas descritas en Capítulo 15 son adecuadas para la mayoría de los casos no cartográficos, y con la introducción de coord_sf() discutida en Capítulo 6, ggplot2 es capaz de capturar la mayoría de las proyecciones cartográficas. De la caja.
La situación más común en la que los desarrolladores pueden necesitar conocer los aspectos internos de los sistemas de coordenadas es al definir nuevas geoms. No es raro que uno de los métodos draw_*() en una geom llame al método transform() de la coord. Por ejemplo, el método transform() para CoordCartesian se usa para cambiar la escala de los datos de posición pero no los transforma de ninguna otra manera, y es posible que el geom necesite aplicar este cambio de escala para dibujar el grob correctamente. Un ejemplo de este uso aparece en Capítulo 21.
Además de transformar los datos de posición, el coordinador tiene la responsabilidad de representar los ejes, las etiquetas de los ejes, el primer plano y el fondo del panel. Además, la coord puede interceptar y modificar los datos de la capa y el diseño de las facetas. Gran parte de esta funcionalidad está disponible para que los desarrolladores la aprovechen si es absolutamente necesaria (se muestra un ejemplo en Sección 20.1.3), pero en la mayoría de los casos es mejor dejar esta funcionalidad como está.
20.5 Nuevas escalas
Hay tres formas en las que uno podría querer extender ggplot2 con nuevas escalas. El caso más simple es cuando desea proporcionar un envoltorio conveniente para una nueva paleta, generalmente para una estética de color o relleno. Como ejemplo poco práctico, supongamos que desea tomar muestras de colores aleatorios para llenar un violín o un diagrama de caja, utilizando una función de paleta como esta:
Luego podemos escribir una función constructora scale_fill_random() que pase la paleta a discrete_scale() y luego usarla en los gráficos:
scale_fill_random <- function(..., aesthetics = "fill") {
discrete_scale(
aesthetics = aesthetics,
scale_name = "random",
palette = random_colours
)
}
ggplot(mpg, aes(hwy, class, fill = class)) +
geom_violin(show.legend = FALSE) +
scale_fill_random()
#> Warning: The `scale_name` argument of `discrete_scale()` is deprecated as of ggplot2
#> 3.5.0.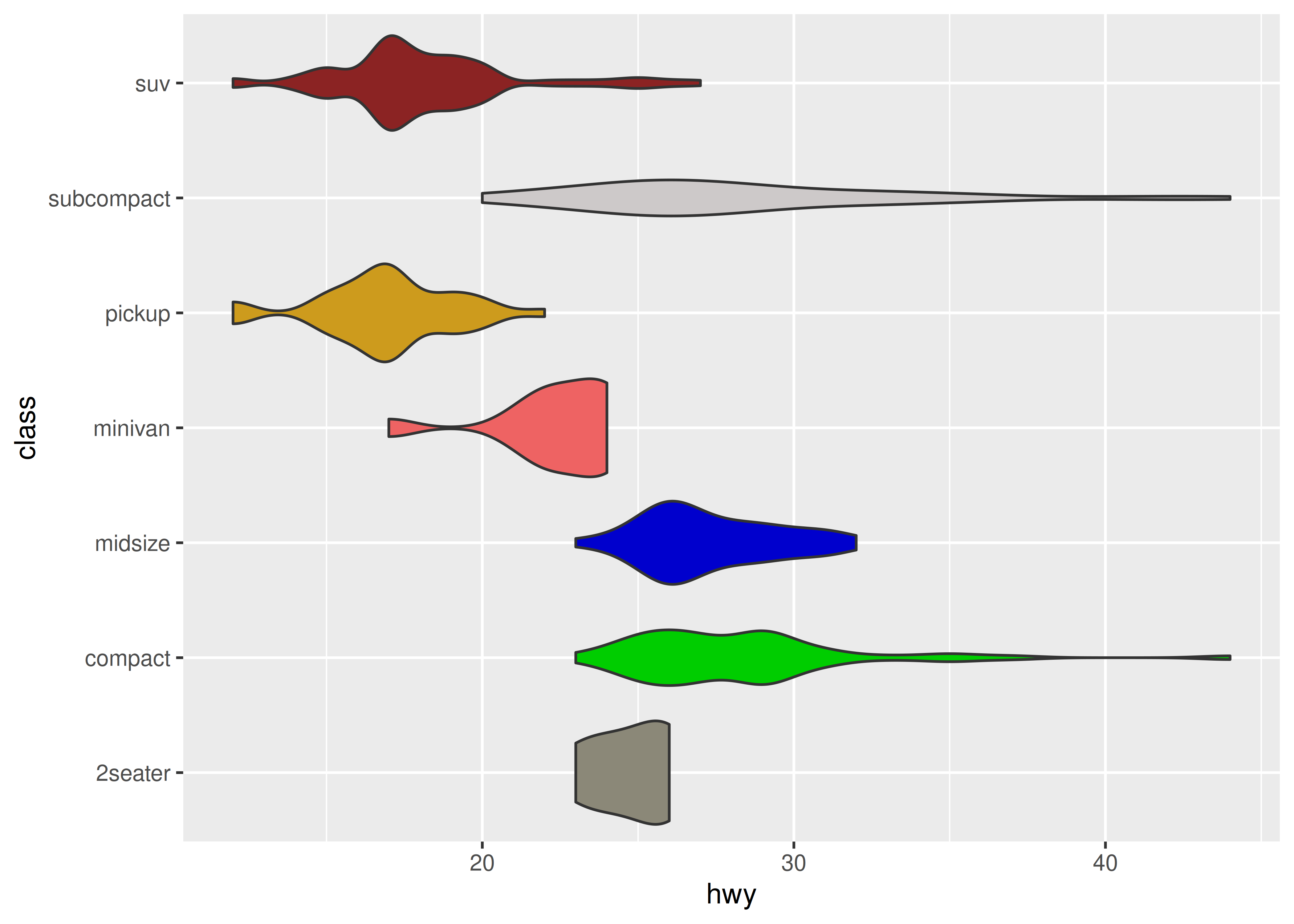
Otro caso relativamente simple es cuando proporcionas una geom que requiere un nuevo tipo de estética que necesita ser ampliada. Digamos que creaste una nueva línea geom y en lugar de la estética de size decidiste usar una estética de with. Para poder escalar el with de la misma manera que esperas la escala del size, debes proporcionar una escala predeterminada para la estética. Las escalas predeterminadas se encuentran según su nombre y el tipo de datos proporcionados a la estética. Si asigna valores continuos a la estética de with, ggplot2 buscará una función scale_width_continuous() y la usará si no se ha agregado otra escala de ancho al gráfico. Si no se encuentra dicha función (y no se agregó explícitamente ninguna escala de ancho), la estética no se escalará.
Una última posibilidad que vale la pena mencionar, pero fuera del alcance de este libro, es la posibilidad de crear un nuevo tipo de escala primaria. Históricamente, ggplot2 ha tenido dos tipos de escala principales, continua y discreta. Recientemente se unió el tipo de escala agrupada que permite agrupar datos continuos en contenedores discretos. Es posible desarrollar más escalas primarias siguiendo el ejemplo de ScaleBinned. Requiere subclasificar Scale o una de las escalas primarias proporcionadas, y crear nuevos métodos train() y map(), entre otros.
20.6 Nuevas posiciones
La clase ggproto Position es algo más simple que otras clases ggproto, lo que refleja el hecho de que las funciones position_*() tienen un alcance muy limitado. La función del puesto es recibir y modificar los datos inmediatamente antes de pasarlos a cualquier función de dibujo. Estrictamente hablando, la posición puede modificar los datos de cualquier forma, pero existe una expectativa implícita de que sólo modifica la estética de la posición. Una posición posee métodos compute_layer() y compute_panel() que se comportan de manera análoga a los métodos equivalentes para una estadística, pero no posee un método compute_group(). También contiene los métodos setup_params() y setup_data() que son similares a los métodos setup_*() para otras clases de ggproto, con una excepción notable: el método setup_params() solo recibe los datos como entrada, y no una lista de parámetros. La razón de esto es que las funciones position_*() nunca se usan solas en ggplot2: más bien, siempre se llaman dentro del comando principal geom_*() o stat_*() que especifica la capa y los parámetros del comando principal no se pasan a la llamada de función position_*().
Para dar un ejemplo simple, implementaremos una versión ligeramente simplificada de la función position_jitternormal() del paquete ggforce, que se comporta de la misma manera que position_jitter() excepto que las perturbaciones se muestrean a partir de una distribución normal en lugar de que una distribución uniforme. Para mantener la exposición simple, asumiremos que tenemos definida la siguiente función de conveniencia:
Cuando se llama, normal_transformer() devuelve una función que perturba el vector de entrada agregando ruido aleatorio con media cero y desviación estándar sd. El primer paso al crear nuestra nueva posición es crear una subclase del objeto Position:
PositionJitterNormal <- ggproto('PositionJitterNormal', Position,
# Necesitamos una estética de posición xey
required_aes = c('x', 'y'),
# Al usar el argumento "self" podemos acceder a los parámetros que el
# usuario ha pasado a la posición y agregarlos como parámetros de capa.
setup_params = function(self, data) {
list(
sd_x = self$sd_x,
sd_y = self$sd_y
)
},
# Al calcular la capa, podemos leer los parámetros de desviación estándar
# de la lista de parámetros y usarlos para transformar la estética de la
# posición.
compute_layer = function(data, params, panel) {
# construir transformadores para las escalas de posición x e y
x_transformer <- normal_transformer(x, params$sd_x)
y_transformer <- normal_transformer(y, params$sd_y)
# devolver los datos transformados
transform_position(
df = data,
trans_x = x_transformer,
trans_y = y_transformer
)
}
)El método compute_layer() hace uso de transform_position(), una función conveniente proporcionada por ggplot2 cuya función es aplicar las funciones proporcionadas por el usuario a toda la estética asociada con la escala de posición relevante (por ejemplo, no solo x e y, pero también xend y yend).
En una implementación realista, el constructor position_jitternormal() aplicaría alguna validación de entrada para asegurarse de que el usuario no haya especificado desviaciones estándar negativas, pero en este contexto lo mantendremos simple:
position_jitternormal <- function(sd_x = .15, sd_y = .15) {
ggproto(NULL, PositionJitterNormal, sd_x = sd_x, sd_y = sd_y)
}Ahora podemos utilizar nuestra nueva función de posición al crear gráficos. Para ver la diferencia entre position_jitter() y la función position_jitternormal() que acabamos de definir, compare los siguientes gráficos:
df <- data.frame(
x = sample(1:3, 1500, TRUE),
y = sample(1:3, 1500, TRUE)
)
ggplot(df, aes(x, y)) + geom_point(position = position_jitter())
ggplot(df, aes(x, y)) + geom_point(position = position_jitternormal())
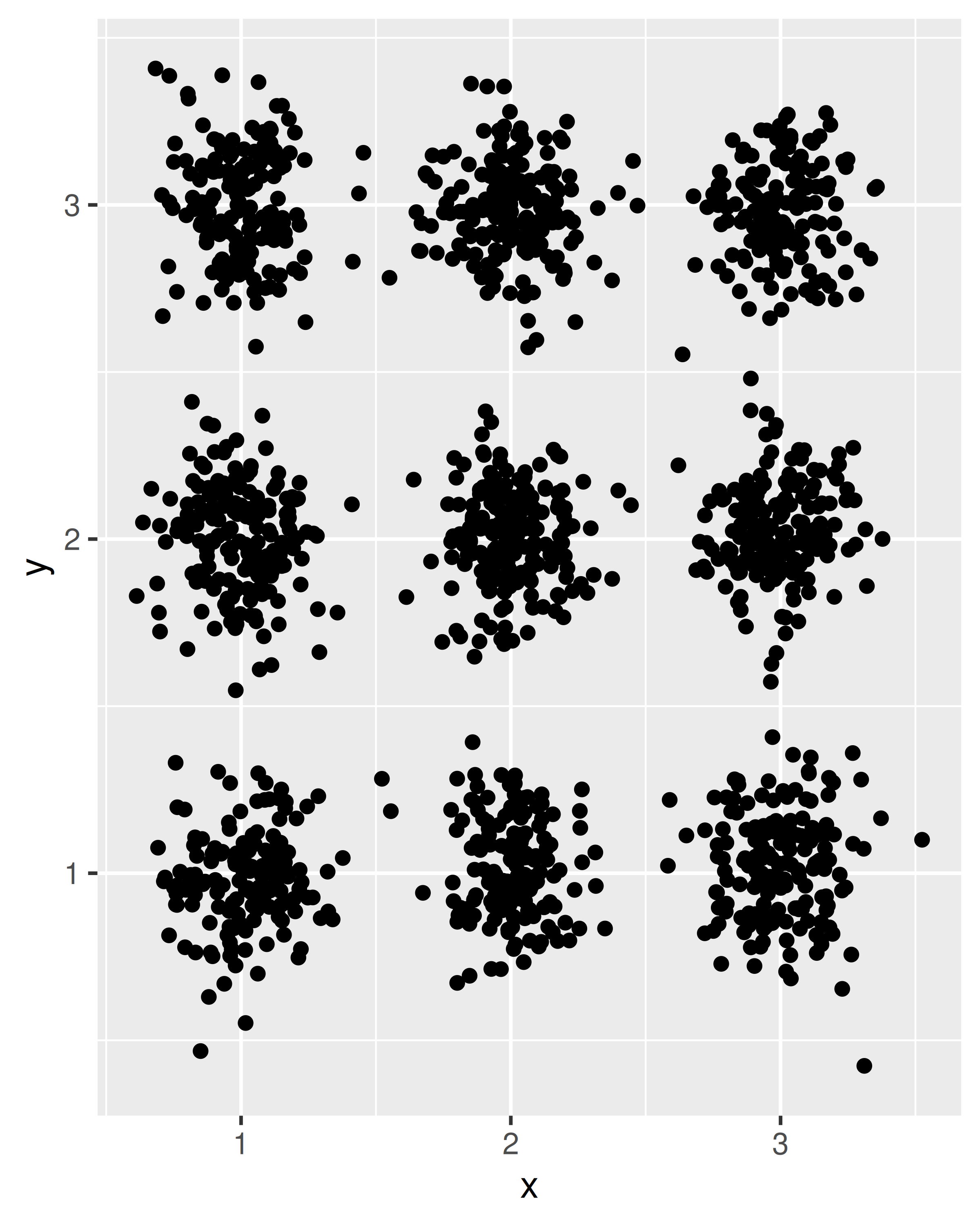
Una consideración práctica a tener en cuenta al diseñar nuevas posiciones es que los usuarios rara vez llaman directamente al constructor de posiciones. Es más probable que el comando que especifica la capa incluya una expresión como position = "dodge" en lugar de position = position_dodge(), y es incluso menos probable que anule los valores predeterminados, como ocurriría si el usuario especificara position = position_dodge (width = 0,9). Como consecuencia, es importante pensar detenidamente y, si es posible, hacer que los valores predeterminados funcionen en la mayoría de los casos. Esto puede ser bastante complicado: las posiciones tienen muy poco control sobre la forma y el formato de los datos de la capa, pero el usuario esperará que se comporten de manera predecible en todas las situaciones. Un ejemplo es el caso de esquivar, donde a los usuarios les gustaría esquivar un diagrama de caja y una nube de puntos, y esperarían que la nube de puntos apareciera en la misma área que su diagrama de caja respectivo. Esta es una expectativa perfectamente razonable a nivel de usuario, pero puede resultar complicada para el desarrollador. Un diagrama de caja tiene un ancho explícito que se puede usar para controlar la esquiva, mientras que no ocurre lo mismo con los puntos, pero el usuario esperará que se muevan de la misma manera. Estas consideraciones a menudo significan que las implementaciones de posiciones terminan siendo mucho más complejas que su solución más simple para atender una amplia gama de casos extremos.
20.7 Nuevas facetas
Las facetas son uno de los conceptos más poderosos de ggplot2, y extenderlas es una de las formas más poderosas de modificar el funcionamiento de ggplot2. Este poder tiene un coste: las facetas se encargan de recibir todos los paneles, unirles los ejes y las tiras y luego disponerlos de la manera esperada. Crear un sistema de facetado completamente nuevo requiere un conocimiento profundo de grid y gtable, y puede ser un desafío desalentador. Afortunadamente, no siempre es necesario crear la faceta desde cero. Por ejemplo, si su nueva faceta producirá paneles que se encuentran en una cuadrícula, a menudo puede subclasificar FacetWrap o FacetGrid y modificar uno o dos métodos. En particular, es posible que desees definir nuevos métodos compute_layout() y/O map_data():
El método
compute_layout()recibe el conjunto de datos original y crea una especificación de diseño, un marco de datos con una fila por panel que indica dónde cae cada panel en la cuadrícula, junto con información sobre qué límites de eje deben estar libres y cuáles deben estar libres. fijado.El método
map_data()recibe esta especificación de diseño y los datos originales como entrada, y le adjunta una columnaPANEL, que se utiliza para asignar cada fila en el marco de datos a uno de los paneles en el diseño.
Para ilustrar cómo se pueden crear nuevas facetas subclasificando una faceta existente, crearemos un sistema de facetas relativamente simple que “scatter” los paneles, colocándolos en ubicaciones aleatorias en una cuadrícula. Para hacer esto, crearemos un nuevo objeto ggproto llamado FacetScatter que es una subclase de FacetWrap y escribiremos un nuevo método compute_layout() que coloca cada panel en una celda elegida al azar de la cuadrícula de paneles:
FacetScatter <- ggproto("FacetScatter", FacetWrap,
# Esto no es importante para el ejemplo: todo lo que
# estamos haciendo es forzar a todos los paneles a usar
# una escala fija para que el resto del ejemplo se pueda
# mantener simple.
setup_params = function(data, params) {
params <- FacetWrap$setup_params(data, params)
params$free <- list(x = FALSE, y = FALSE)
return(params)
},
# El método compute_layout() hace el trabajo.
compute_layout = function(data, params) {
# cree un marco de datos con una columna por variable
# de faceta y una fila para cada combinación posible
# de valores (es decir, una fila por panel)
panels <- combine_vars(
data = data,
env = params$plot_env,
vars = params$facets,
drop = FALSE
)
# Cree un marco de datos con columnas para ROW y COL,
# con una fila para cada celda posible en la cuadrícula
# del panel
locations <- expand.grid(ROW = 1:params$nrow, COL = 1:params$ncol)
# Muestrear aleatoriamente un subconjunto de las
# ubicaciones
shuffle <- sample(nrow(locations), nrow(panels))
# Asigne a cada panel una ubicación
layout <- data.frame(
PANEL = 1:nrow(panels), # identificador de panel
ROW = locations$ROW[shuffle], # número de fila para los paneles
COL = locations$COL[shuffle], # número de columna para los paneles
SCALE_X = 1L, # todas las escalas del eje x son fijas
SCALE_Y = 1L # todas las escalas del eje y son fijas
)
# Vincule la información de diseño con la identificación del panel y
# devuelva la especificación resultante.
return(cbind(layout, panels))
}
)Para darle una idea de cómo se ve este resultado, esta es la especificación de diseño que se crea al construir el gráfico que se muestra al final de esta sección:
#> PANEL ROW COL SCALE_X SCALE_Y manufacturer
#> 1 1 4 1 1 1 audi
#> 2 2 5 5 1 1 chevrolet
#> 3 3 5 1 1 1 dodge
#> 4 4 5 3 1 1 ford
#> 5 5 1 5 1 1 honda
#> 6 6 4 4 1 1 hyundai
#> 7 7 3 5 1 1 jeep
#> 8 8 2 2 1 1 land rover
#> 9 9 5 2 1 1 lincoln
#> 10 10 4 5 1 1 mercury
#> 11 11 2 4 1 1 nissan
#> 12 12 5 4 1 1 pontiac
#> 13 13 3 2 1 1 subaru
#> 14 14 5 6 1 1 toyota
#> 15 15 4 6 1 1 volkswagenA continuación, escribiremos la función constructora facet_scatter() para exponer esta funcionalidad al usuario. Para las facetas, esto es tan simple como crear una nueva instancia del objeto ggproto relevante (FacetScatter en este caso) que pasa parámetros especificados por el usuario a la faceta:
facet_scatter <- function(facets, nrow, ncol,
strip.position = "top",
labeller = "label_value") {
ggproto(NULL, FacetScatter,
params = list(
facets = rlang::quos_auto_name(facets),
strip.position = strip.position,
labeller = labeller,
ncol = ncol,
nrow = nrow
)
)
}Hay un par de cosas a tener en cuenta sobre esta función constructora. Primero, para mantener el ejemplo simple, facet_scatter() contiene menos argumentos que facet_wrap(), y hemos creado argumentos obligatorios para nrow y ncol: el usuario necesita especificar el tamaño de la cuadrícula sobre la cual los paneles deben estar dispersos. En segundo lugar, la función facet_scatter() requiere que especifiques las facetas usando vars(). No funcionará si el usuario intenta proporcionar una fórmula. De manera relacionada, tenga en cuenta el uso de rlang::quos_auto_name(): la función vars() devuelve una lista de expresiones sin nombre (técnicamente, quosures), pero el código posterior requiere una lista con nombre. Mientras espere que el usuario use vars(), este es todo el preprocesamiento que necesita, pero si desea admitir otros formatos de entrada, deberá ser un poco más sofisticado (puede ver cómo hacerlo). mirando el código fuente de ggplot2).
En cualquier caso, ya tenemos un lado de trabajo:
ggplot(mpg, aes(displ, hwy)) +
geom_point() +
facet_scatter(vars(manufacturer), nrow = 5, ncol = 6)