ggplot(mpg, aes(x = displ)) + geom_histogram()10 Escalas de posición y ejes.
You are reading the work-in-progress third edition of the ggplot2 book. This chapter should be readable but is currently undergoing final polishing.
Las escalas de posición se utilizan para controlar las ubicaciones de entidades visuales en un gráfico y cómo esas ubicaciones se asignan a los valores de datos. Cada gráfico tiene dos escalas de posición, correspondientes a la estética xey. En la mayoría de los casos, esto queda claro en la especificación del gráfico, porque el usuario especifica explícitamente las variables asignadas a xey. Sin embargo, este no es siempre el caso. Considere esta especificación de la gráfica:
En este ejemplo, el usuario no especifica la estética y. Más bien, la estética se asigna a una variable calculada: geom_histogram() calcula una variable count que se asigna a la estética y. El comportamiento predeterminado de geom_histogram() es equivalente al siguiente:
ggplot(mpg, aes(x = displ, y = after_stat(count))) + geom_histogram()Dado que las escalas de posición se utilizan en todos los gráficos, es útil comprender cómo funcionan y cómo se pueden modificar. En este capítulo discutiremos esto en detalle. El capítulo está organizado en cuatro secciones principales:
- Sección 10.1 analiza las escalas de posición continua. Además de cubrir temas centrales como el control de límites de escala (Sección 10.1.1), pausas (Sección 10.1.4) y etiquetas (Sección 10.1.6), hay secciones que brindan una cobertura detallada de las transformaciones de escala (Sección 10.1.7), así como los problemas sutiles que surgen cuando es necesario acercar o alejar un gráfico (Sección 10.1.2 y Sección 10.1.3).
- Sección 10.2 analiza las escalas de fecha/hora, un tipo especial de escala continua. Debido a que las fechas y horas son un poco más complicadas que una variable continua estándar, ggplot2 proporciona escalas especiales para ayudarlo a controlar las rupturas mayores y menores (Sección 10.2.1 y Sección 10.2.2) y las etiquetas (@ sec-date-labels) para datos de fecha/hora.
- Sección 10.3 analiza escalas de posición discretas. Cubre límites, rupturas y etiquetas en Sección 10.3.1 y la personalización de etiquetas de eje en Sección 10.3.2.
- Sección 10.4 analiza las escalas de posición agrupadas.
10.1 Escalas de posición numéricas
Las escalas de posición continua más comunes son las funciones predeterminadas scale_x_continuous() y scale_y_continuous(). En el caso más simple, se asignan linealmente desde el valor de los datos hasta una ubicación en el gráfico. Hay varias otras escalas de posición para variables continuas—scale_x_log10(), scale_x_reverse(), etc.—la mayoría de las cuales son funciones de conveniencia utilizadas para proporcionar un fácil acceso a transformaciones comunes, analizadas en ?sec-scale -transformación.
10.1.1 Límites
Todas las escalas tienen límites que especifican los valores de la estética sobre los cuales se define la escala. Es muy natural pensar en estos límites para escalas de posición numéricas, ya que se asignan directamente a los rangos de los ejes. De forma predeterminada, los límites se calculan a partir del rango de la variable de datos, pero a veces necesitarás establecer los límites manualmente usando el argumento limits de la función de escala. Siempre que la escala sea continua, como es el caso de las escalas de posición numéricas, debe ser un vector numérico de longitud dos. Si solo desea establecer el límite superior o inferior, puede establecer el otro valor en NA.
Establecer límites de escala manualmente es una tarea común cuando es necesario asegurarse de que las escalas en diferentes gráficos sean consistentes entre sí. Para ilustrar por qué esto es necesario, considere este diagrama facetado:
ggplot(mpg, aes(displ, hwy)) +
geom_point() +
facet_wrap(vars(year))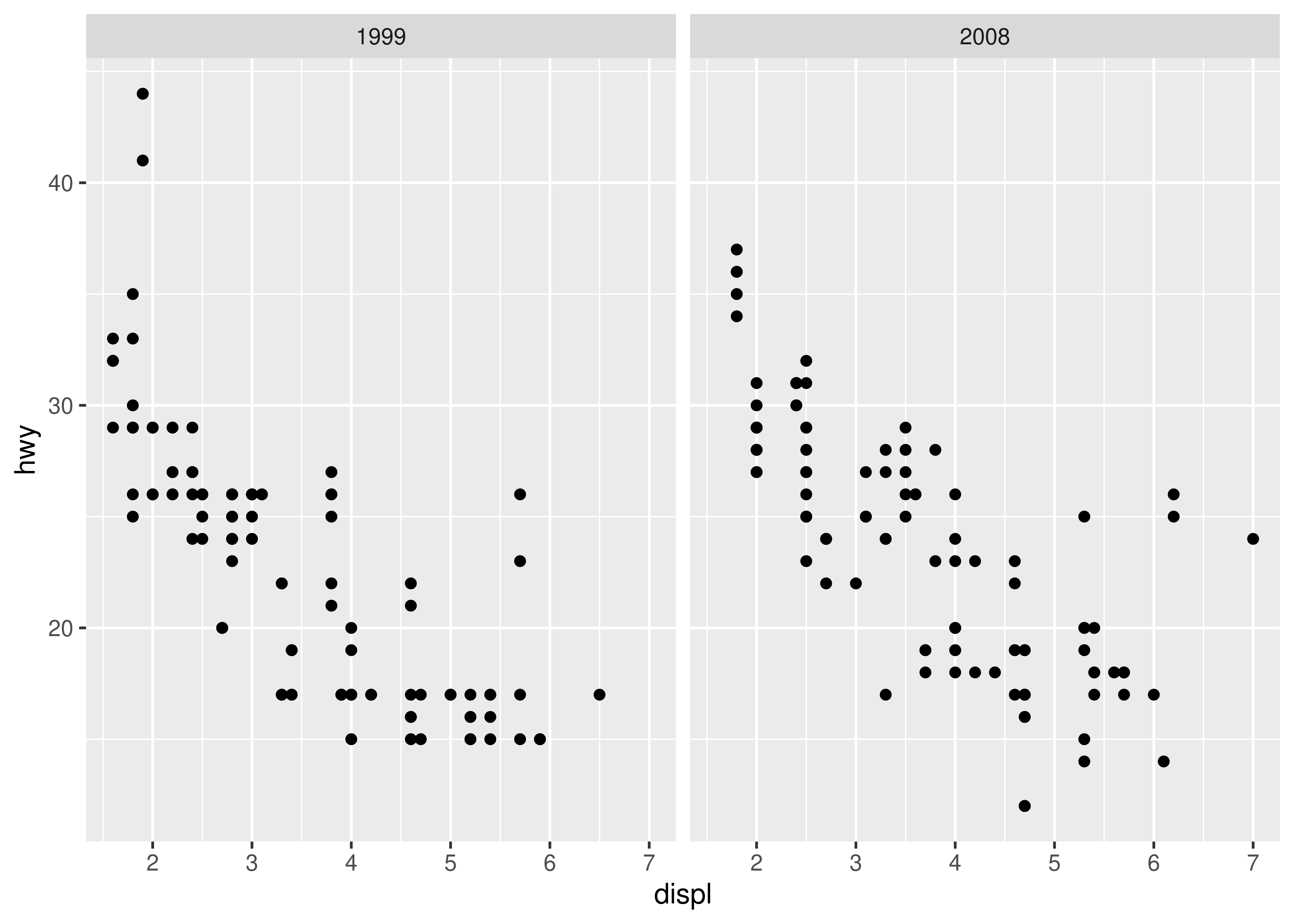
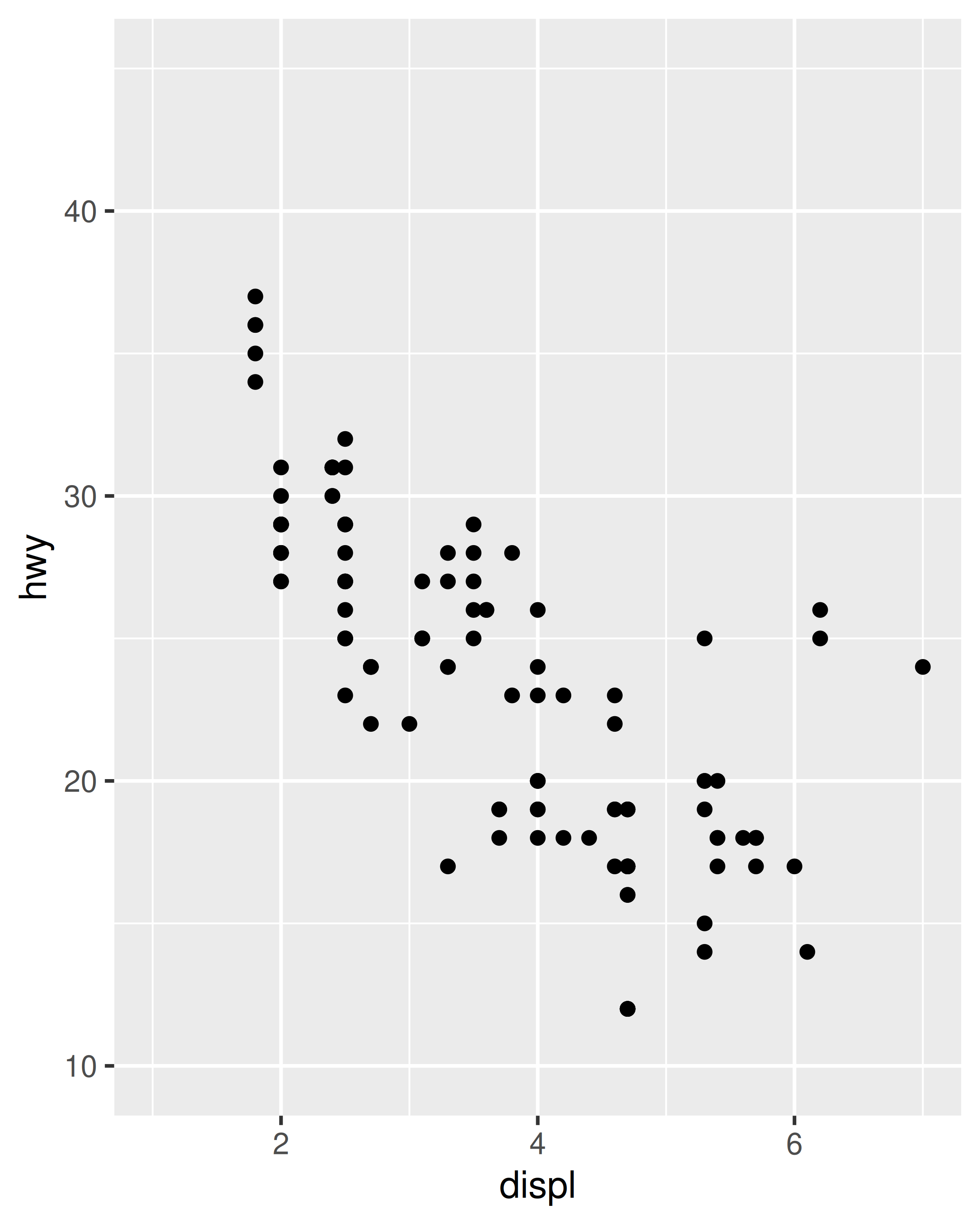
En este gráfico, ggplot2 se ha asegurado automáticamente de que ambas facetas tengan los mismos límites de eje, lo que facilita la comparación visual de los dos diagramas de dispersión. Sin embargo, al crear los gráficos individualmente, los límites de escala en diferentes gráficos a menudo serán inconsistentes:
mpg_99 <- mpg %>% filter(year == 1999)
mpg_08 <- mpg %>% filter(year == 2008)
base_99 <- ggplot(mpg_99, aes(displ, hwy)) + geom_point()
base_08 <- ggplot(mpg_08, aes(displ, hwy)) + geom_point()
base_99
base_08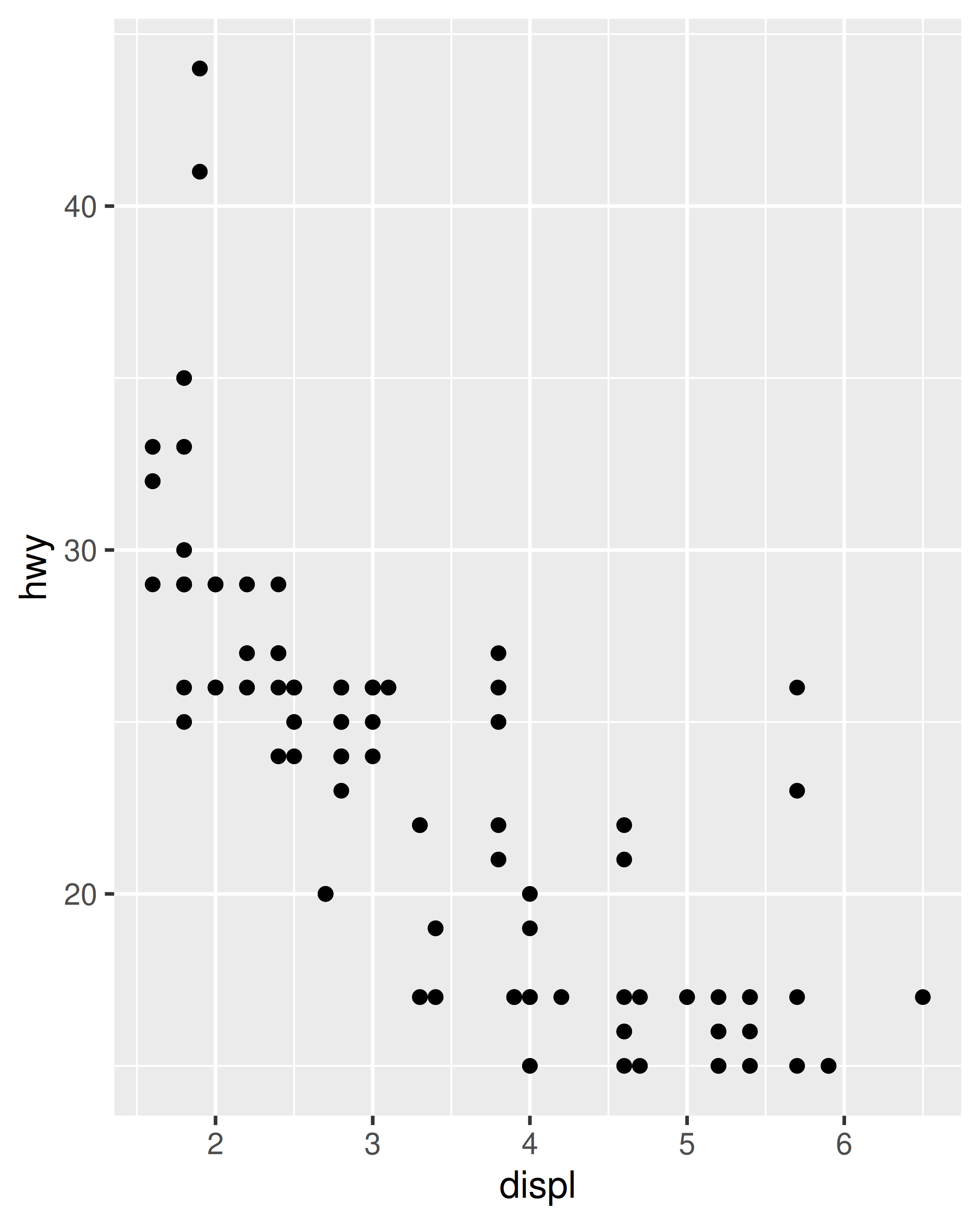
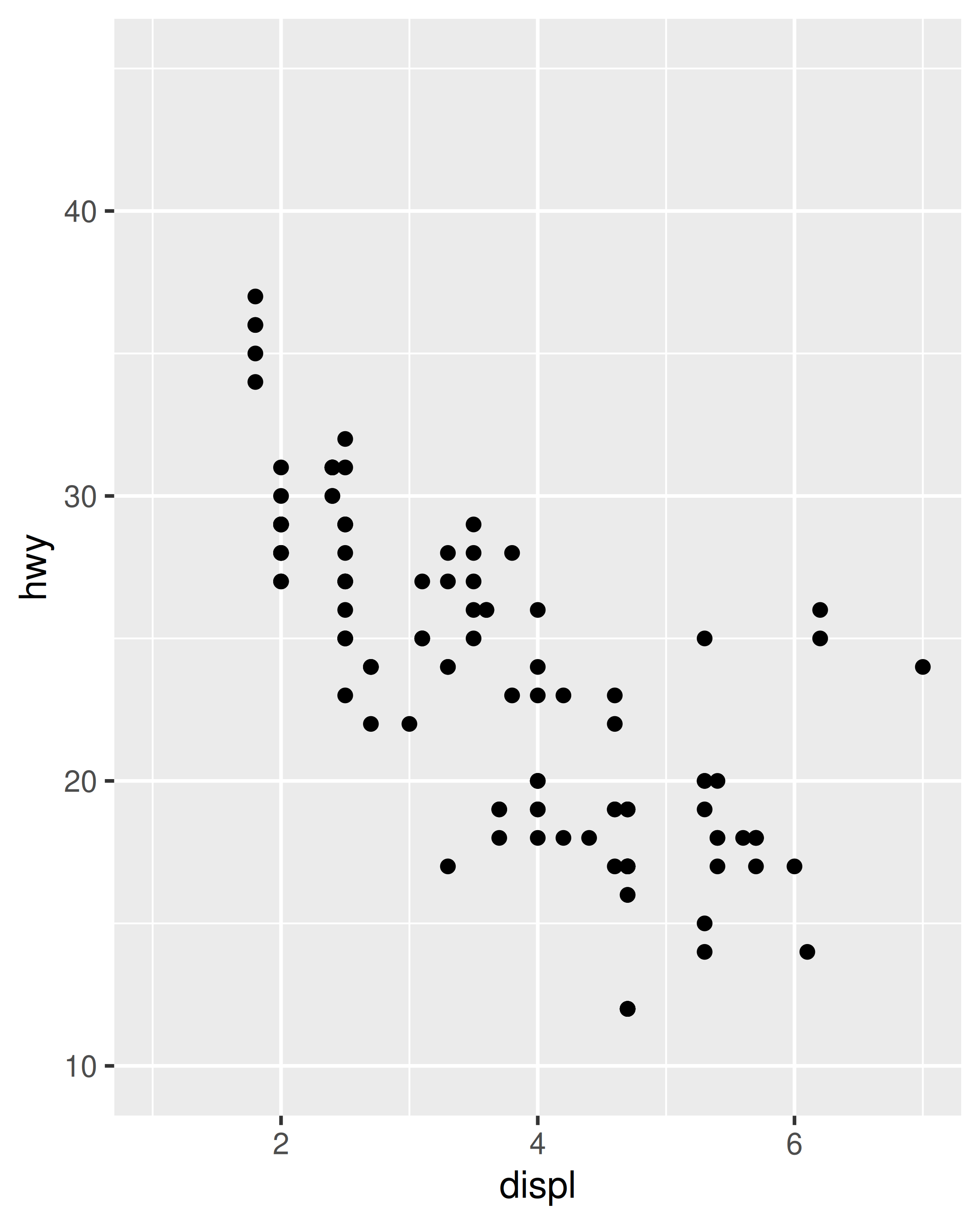
Cada gráfico tiene sentido por sí solo, pero la comparación visual entre los dos es difícil debido a la escala inconsistente de los ejes. Para garantizar una escala de eje consistente, podemos establecer el argumento limits para cada escala por separado:
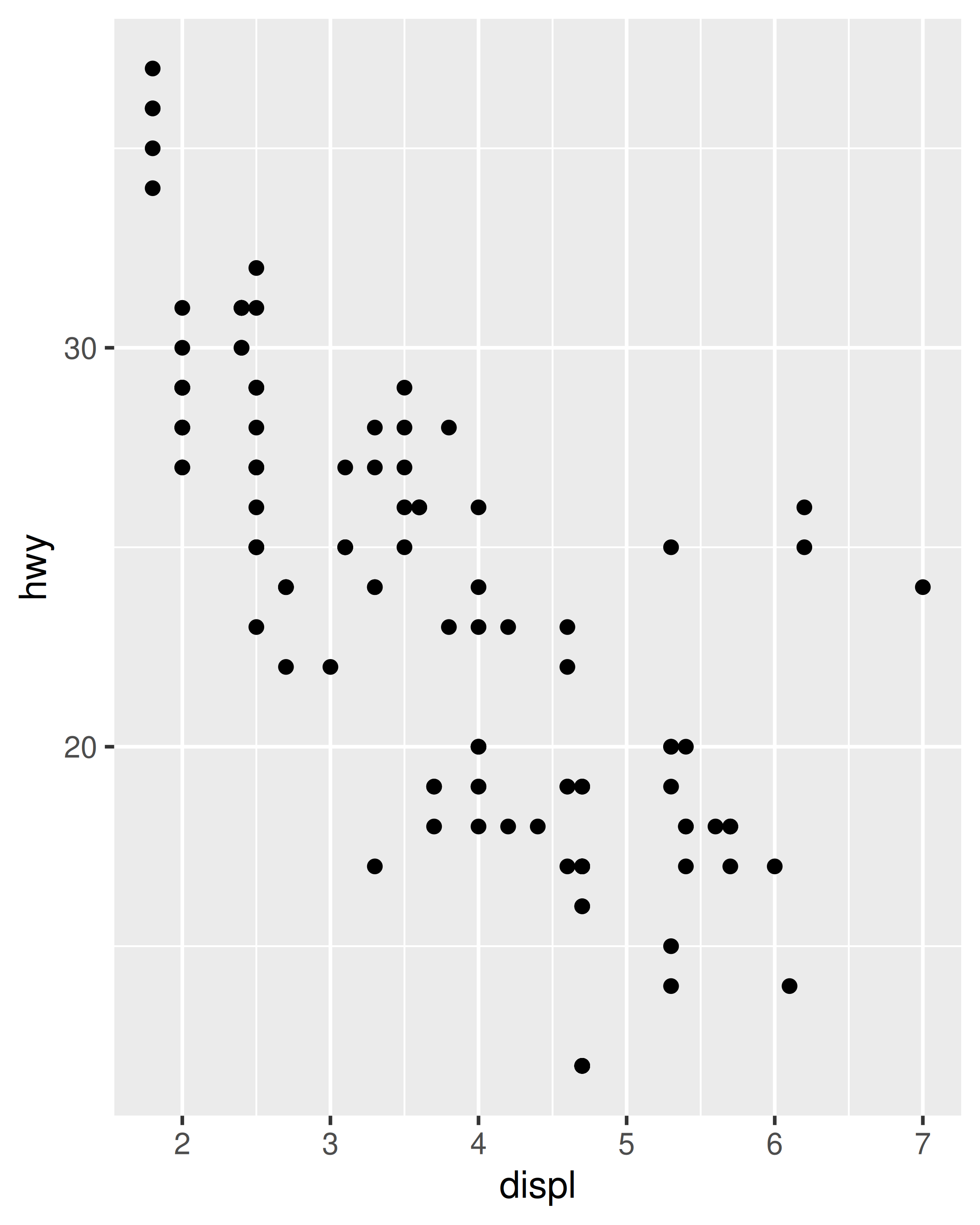
base_99 +
scale_x_continuous(limits = c(1, 7)) +
scale_y_continuous(limits = c(10, 45))
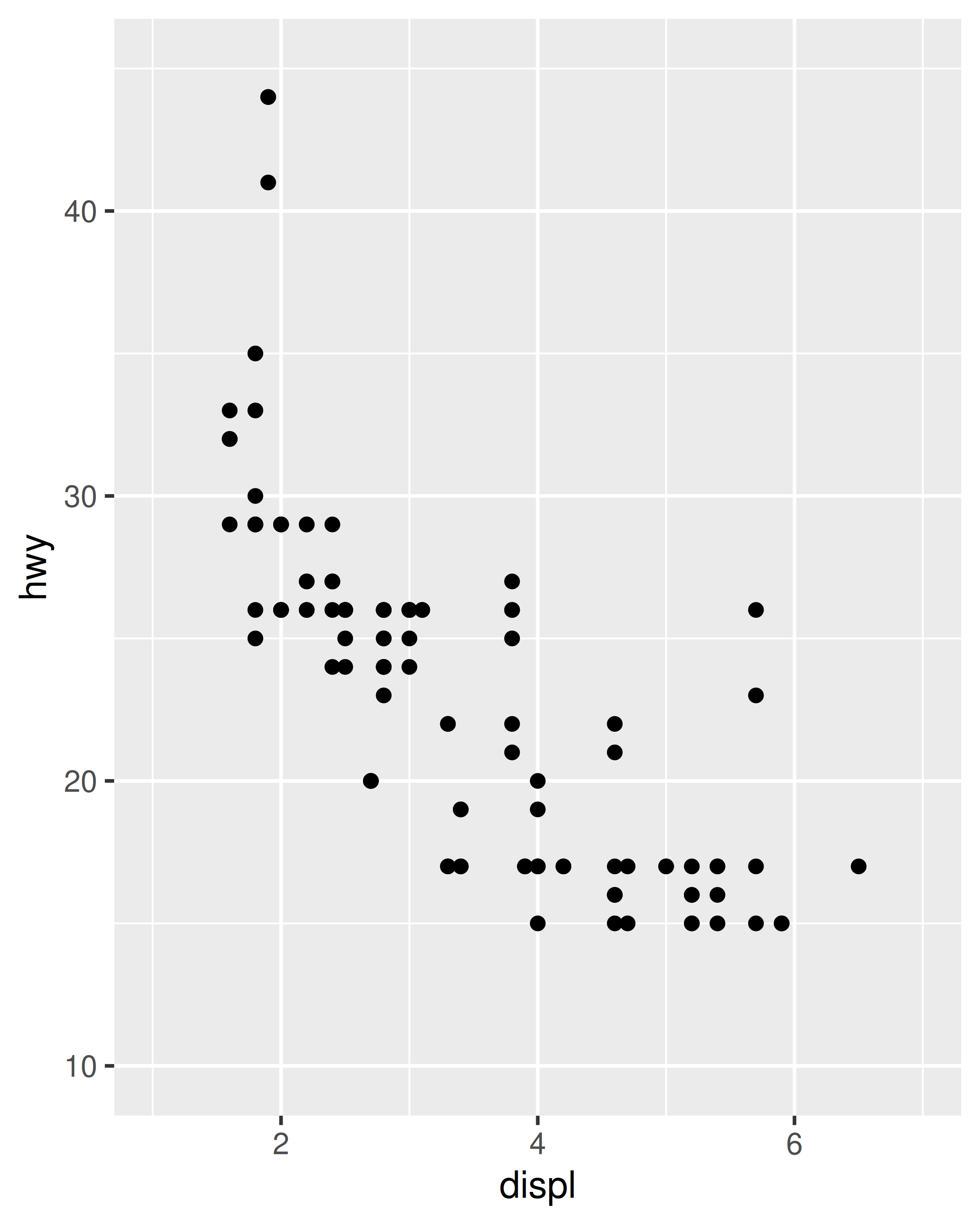
base_08 +
scale_x_continuous(limits = c(1, 7)) +
scale_y_continuous(limits = c(10, 45))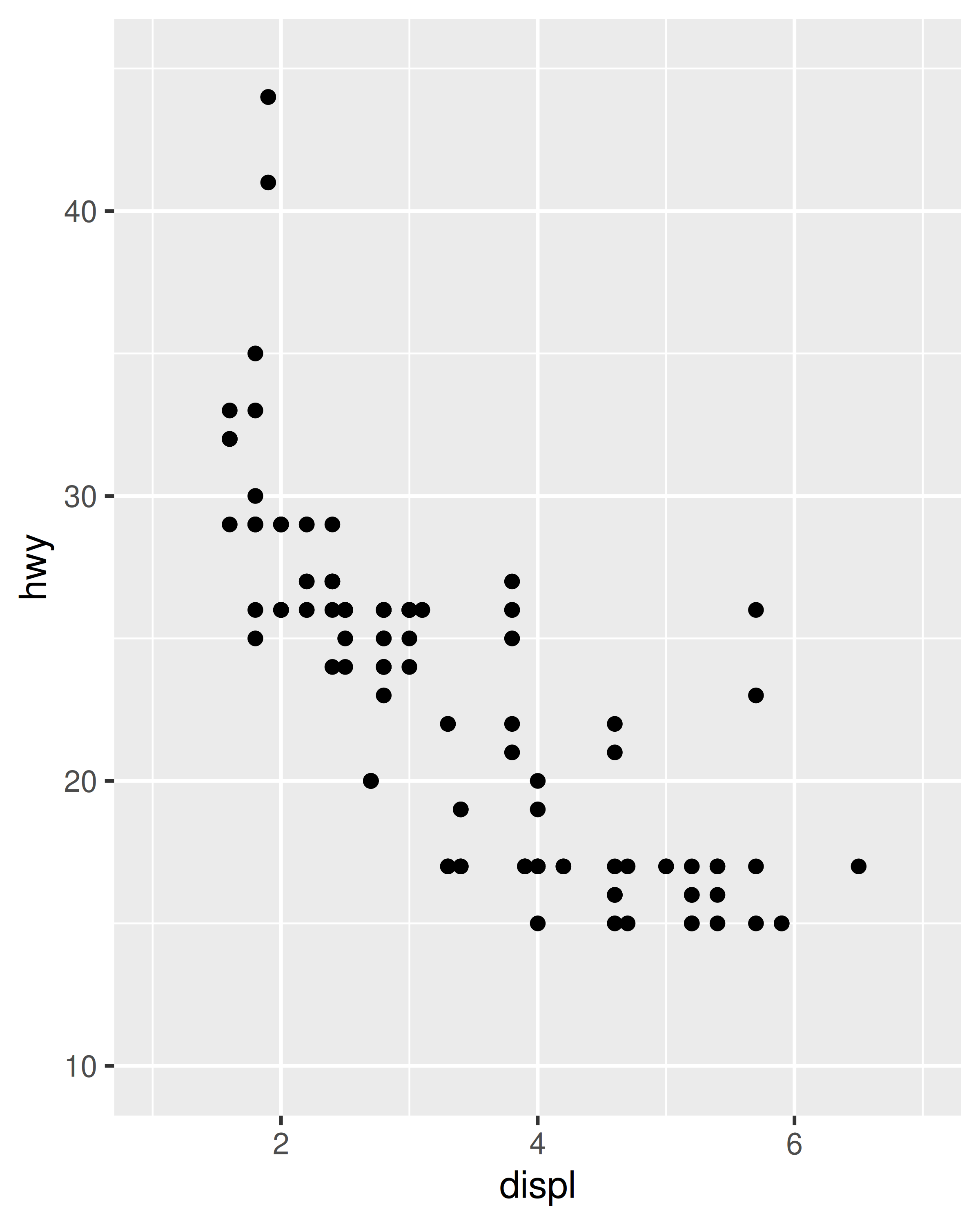
Sin embargo, este código es un poco difícil de manejar. Debido a que modificar los límites de escala es una tarea tan común, ggplot2 proporciona la función de conveniencia lims() para simplificar el código. De manera análoga a la función labs() utilizada para especificar etiquetas de eje (Sección 8.1), lims() toma pares nombre-valor como entradas: el nombre del argumento se usa para especificar la estética y el valor se usa para especificar los límites de escala.
En el caso especial en el que solo es necesario especificar un límite de eje, ggplot2 también proporciona funciones auxiliares xlim() y ylim(), que pueden ahorrarle algunas pulsaciones de teclas. En la práctica, lims() tiende a ser más útil, porque puede usarse para establecer límites para varias estéticas a la vez. Verás un ejemplo de lims() aplicado a la estética sin posición en Sección 11.3.5.
10.1.2 Acercándose
Los ejemplos de la sección anterior amplían los límites de la escala más allá del rango abarcado por los datos. También es posible reducir los límites de escala predeterminados, pero se requiere cuidado: cuando trunca los límites de escala, algunos puntos de datos quedarán fuera de los límites que estableció y ggplot2 tiene que tomar una decisión sobre qué hacer con estos puntos de datos. El comportamiento predeterminado en ggplot2 es convertir cualquier valor de datos fuera de los límites de la escala a NA. Esto significa que cambiar los límites de una escala no siempre es lo mismo que hacer un acercamiento visual a una región del gráfico. Si su objetivo es ampliar una parte de la gráfica, normalmente es mejor utilizar los argumentos xlim y ylim de coord_cartesian():
base <- ggplot(mpg, aes(drv, hwy)) +
geom_hline(yintercept = 28, colour = "red") +
geom_boxplot()
base
base + coord_cartesian(ylim = c(10, 35)) # funciona como se esperaba
base + ylim(10, 35) # distorsiona el diagrama de caja
#> Warning: Removed 6 rows containing non-finite outside the scale range
#> (`stat_boxplot()`).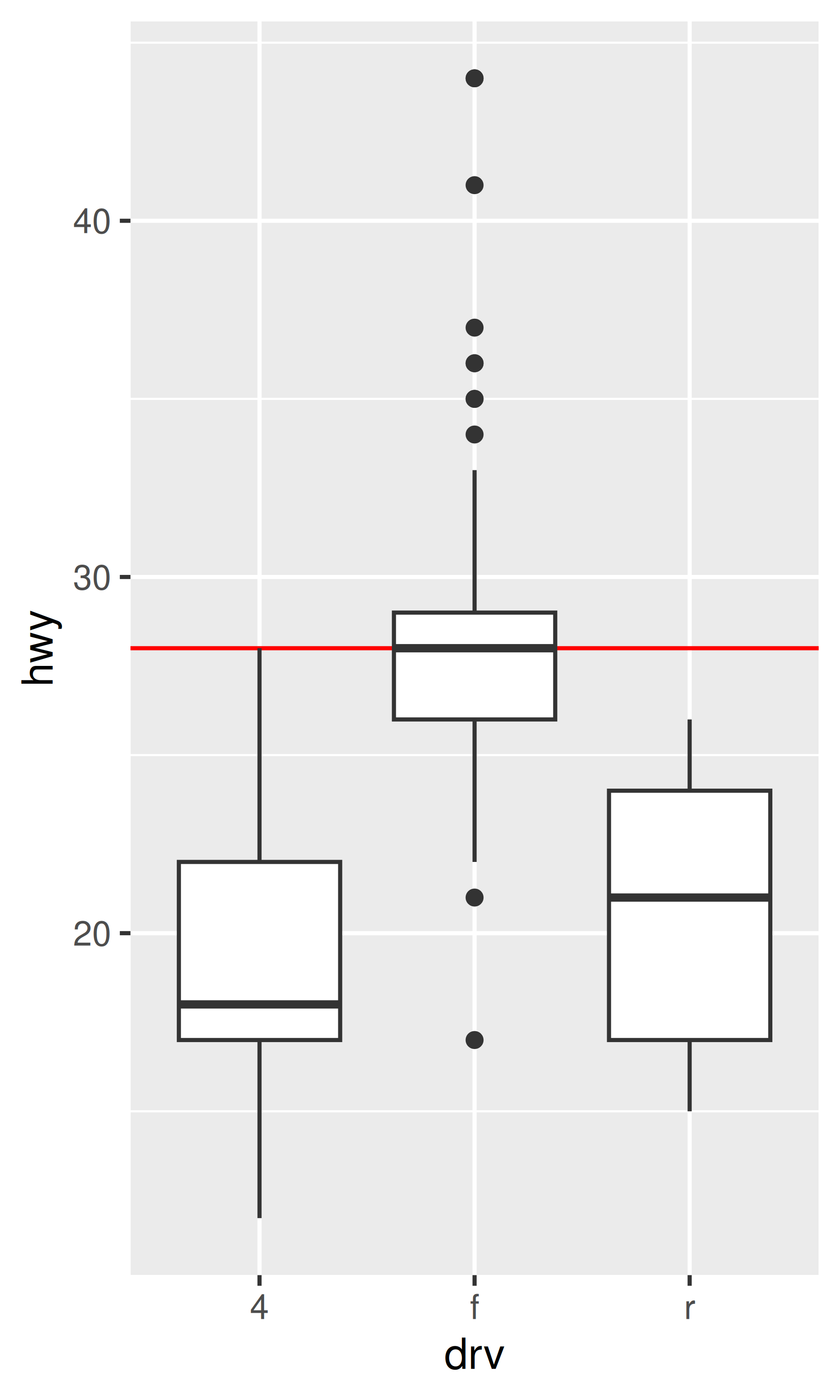
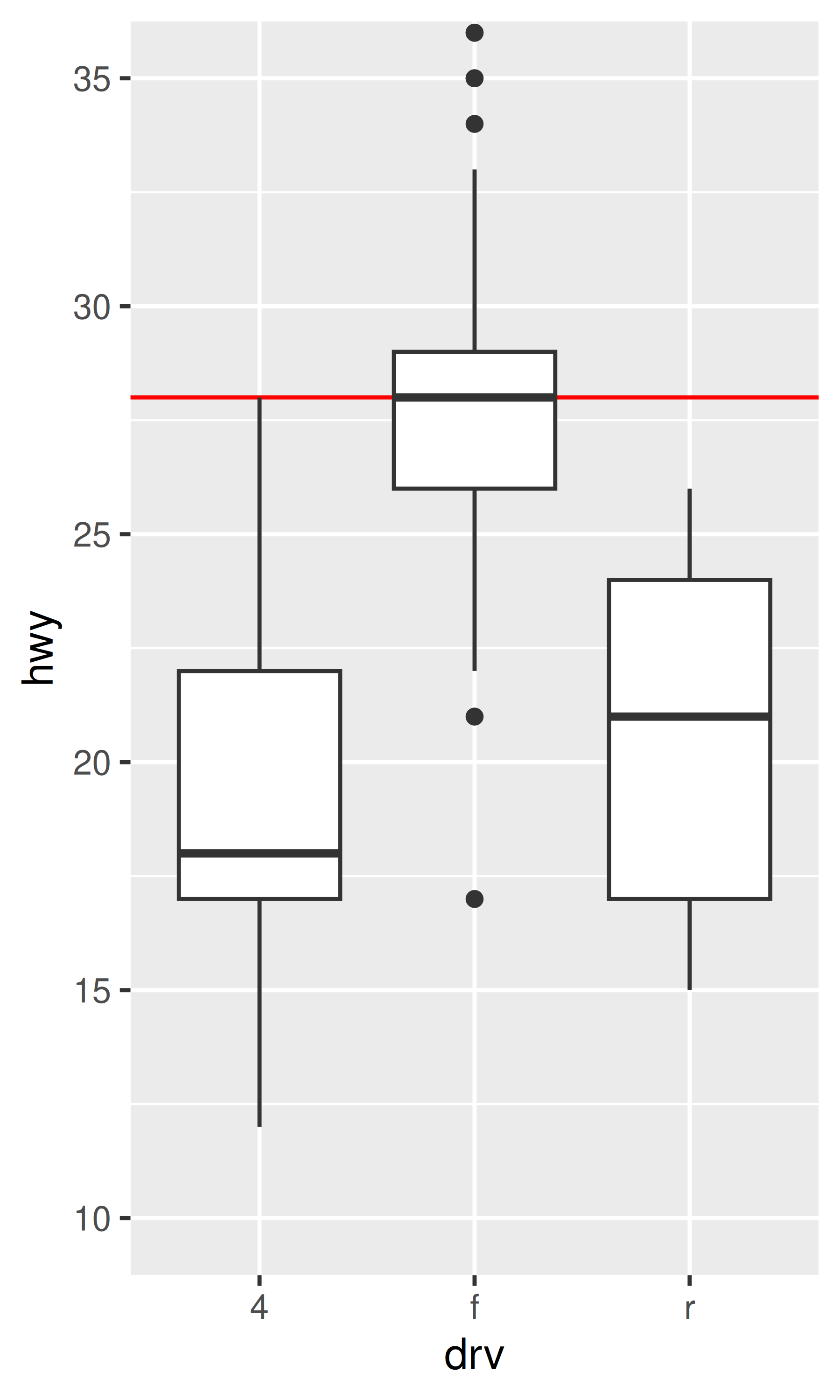
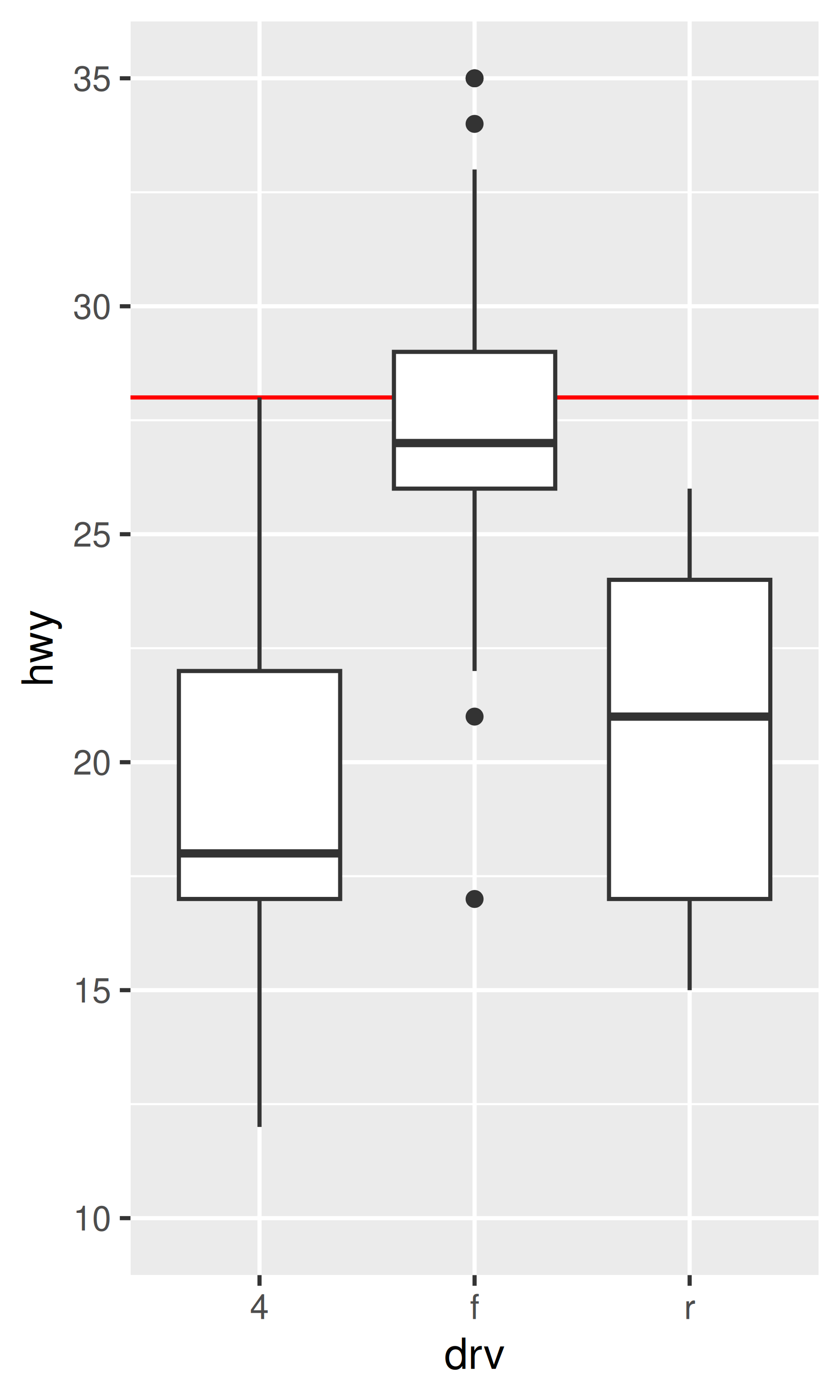
La única diferencia entre los gráficos de la izquierda y del medio es que este último está ampliado. Algunos de los puntos atípicos no se muestran debido a la restricción del rango, pero los diagramas de caja en sí siguen siendo idénticos. Por el contrario, en el gráfico de la derecha uno de los diagramas de caja ha cambiado. Al modificar los límites de la escala, todas las observaciones con un kilometraje en carretera superior a 35 se convierten a NA antes de que se calcule la estadística (en este caso, el diagrama de caja). Debido a que estos valores “fuera de límites” ya no están disponibles, el resultado final es que la mediana de la muestra se desplaza hacia abajo, lo que casi nunca es un comportamiento deseable. En retrospectiva, queda claro que esta no fue una buena elección de diseño, porque es una fuente común de confusión para los usuarios. Desafortunadamente, sería muy difícil cambiar este valor predeterminado sin romper una gran cantidad de código existente.
Puede obtener más información sobre los sistemas de coordenadas en Sección 15.1. Para obtener más información sobre cómo se manejan los valores “fuera de límites” para escalas continuas y agrupadas, consulte Sección 14.4.
10.1.3 Ampliación del rango visual
Si tienes ojos de águila, habrás notado que el rango visual de los ejes en realidad se extiende un poco más allá de los límites numéricos que hemos especificado en los distintos ejemplos. Esto garantiza que los datos no se superpongan a los ejes, lo que suele ser deseable (pero no siempre). Puede anular los valores predeterminados configurando el argumento expand, que espera un vector numérico creado por expansion().
Por ejemplo, un caso en el que normalmente es preferible eliminar este espacio es cuando usamos geom_raster(), lo que podemos lograr estableciendo expand = expansion(0):
base <- ggplot(faithfuld, aes(waiting, eruptions)) +
geom_raster(aes(fill = density)) +
theme(legend.position = "none") +
labs(x = NULL, y = NULL)
base
base +
scale_x_continuous(expand = expansion(0)) +
scale_y_continuous(expand = expansion(0)) 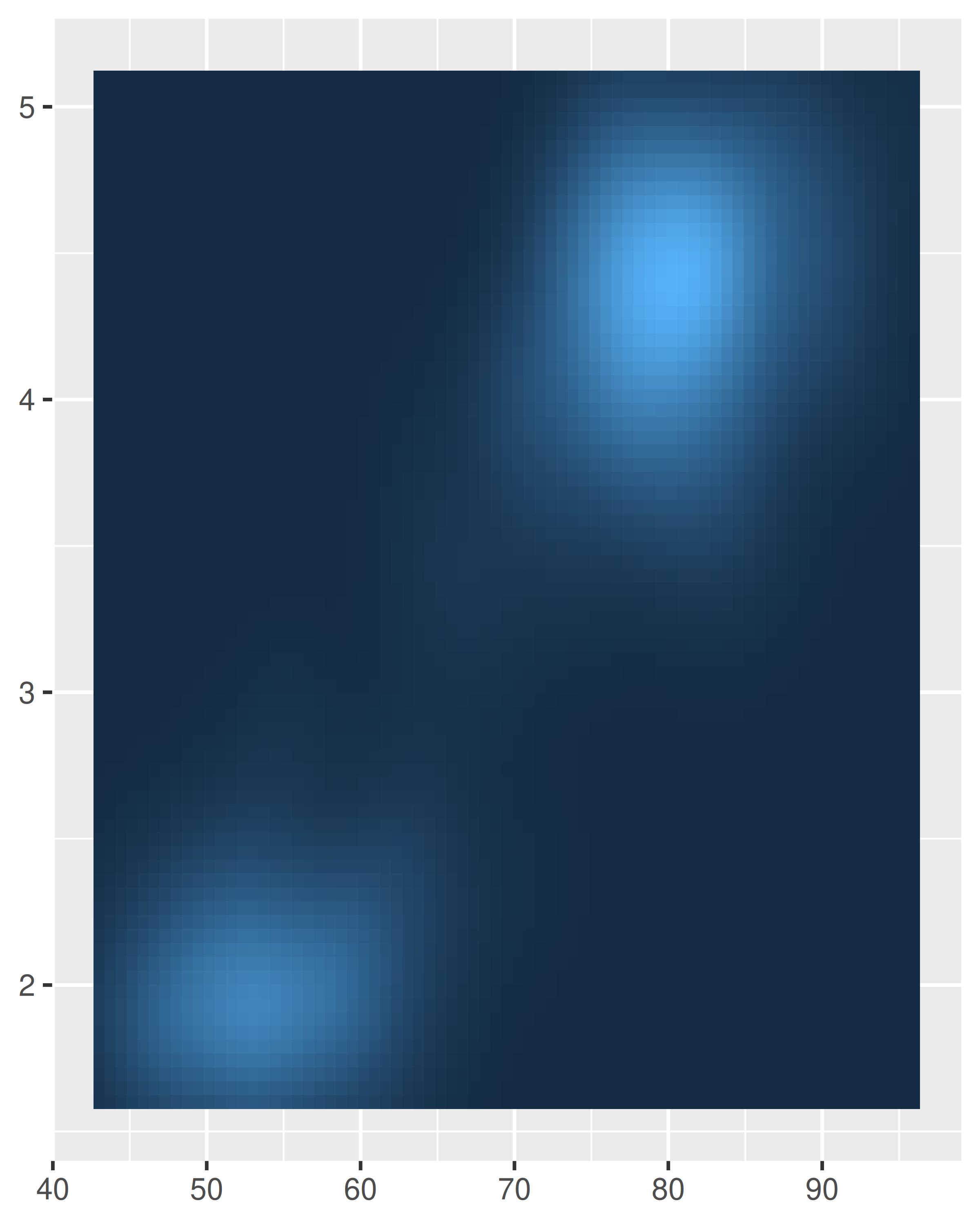
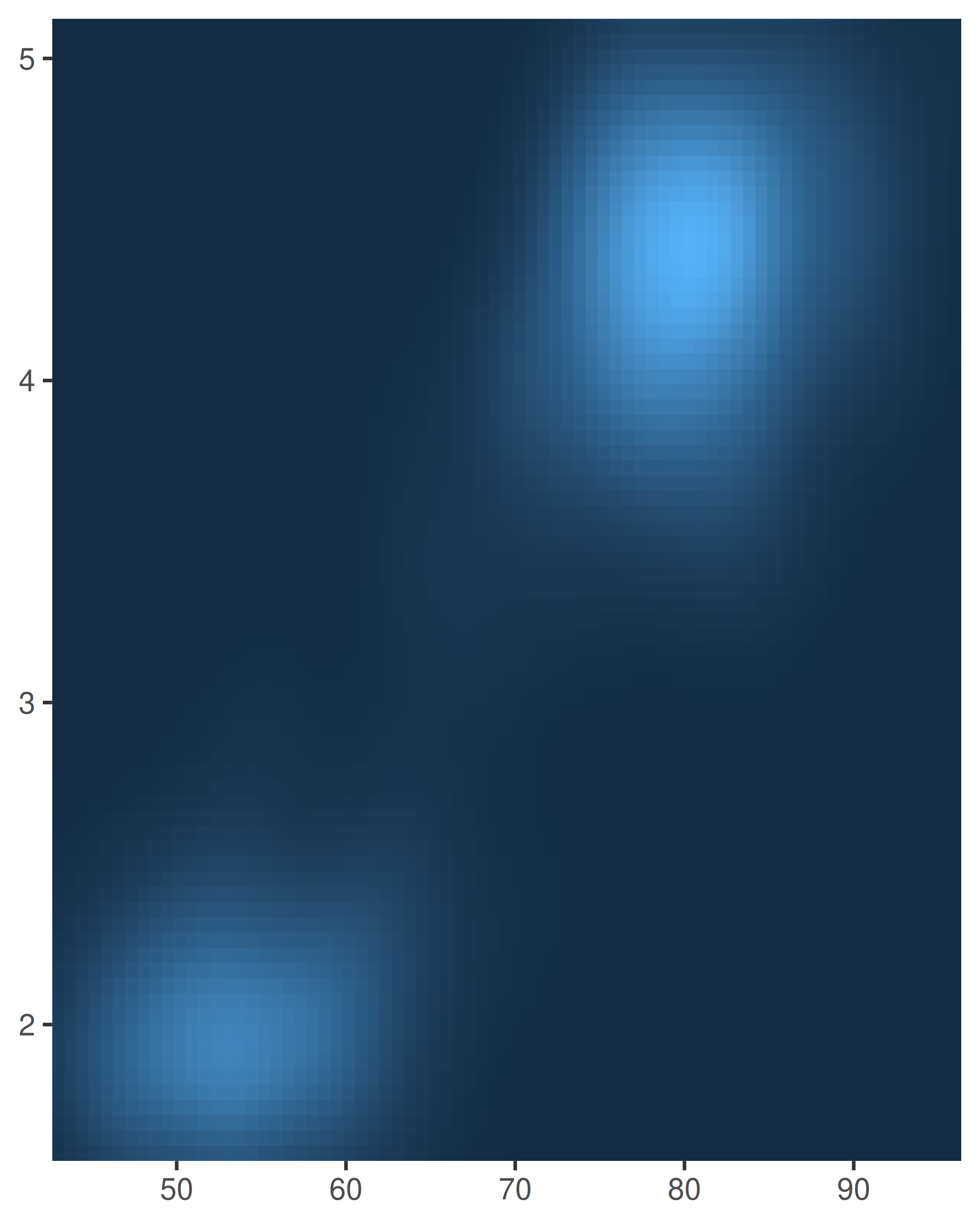
Las expansiones del eje se describen en términos de un factor “aditivo”, que especifica un espacio constante agregado fuera de los límites nominales del eje, y uno “multiplicativo” que agrega espacio definido como una proporción del tamaño del límite del eje. Estos corresponden a los argumentos add y mult de expansion(), que pueden tener longitud uno (si la expansión es la misma en ambos lados) o longitud dos (para establecer diferentes expansiones en cada lado):
# Expansión aditiva de tres unidades en ambos ejes.
base +
scale_x_continuous(expand = expansion(add = 3)) +
scale_y_continuous(expand = expansion(add = 3))
# Expansión multiplicativa del 20% en ambos ejes.
base +
scale_x_continuous(expand = expansion(mult = .2)) +
scale_y_continuous(expand = expansion(mult = .2))
# Expansión multiplicativa del 5% en el extremo inferior
# de cada eje y del 20% en el extremo superior; para
# el eje y la expansión se establece directamente en
# lugar de usar expansion()
base +
scale_x_continuous(expand = expansion(mult = c(.05, .2))) +
scale_y_continuous(expand = c(.05, 0, .2, 0))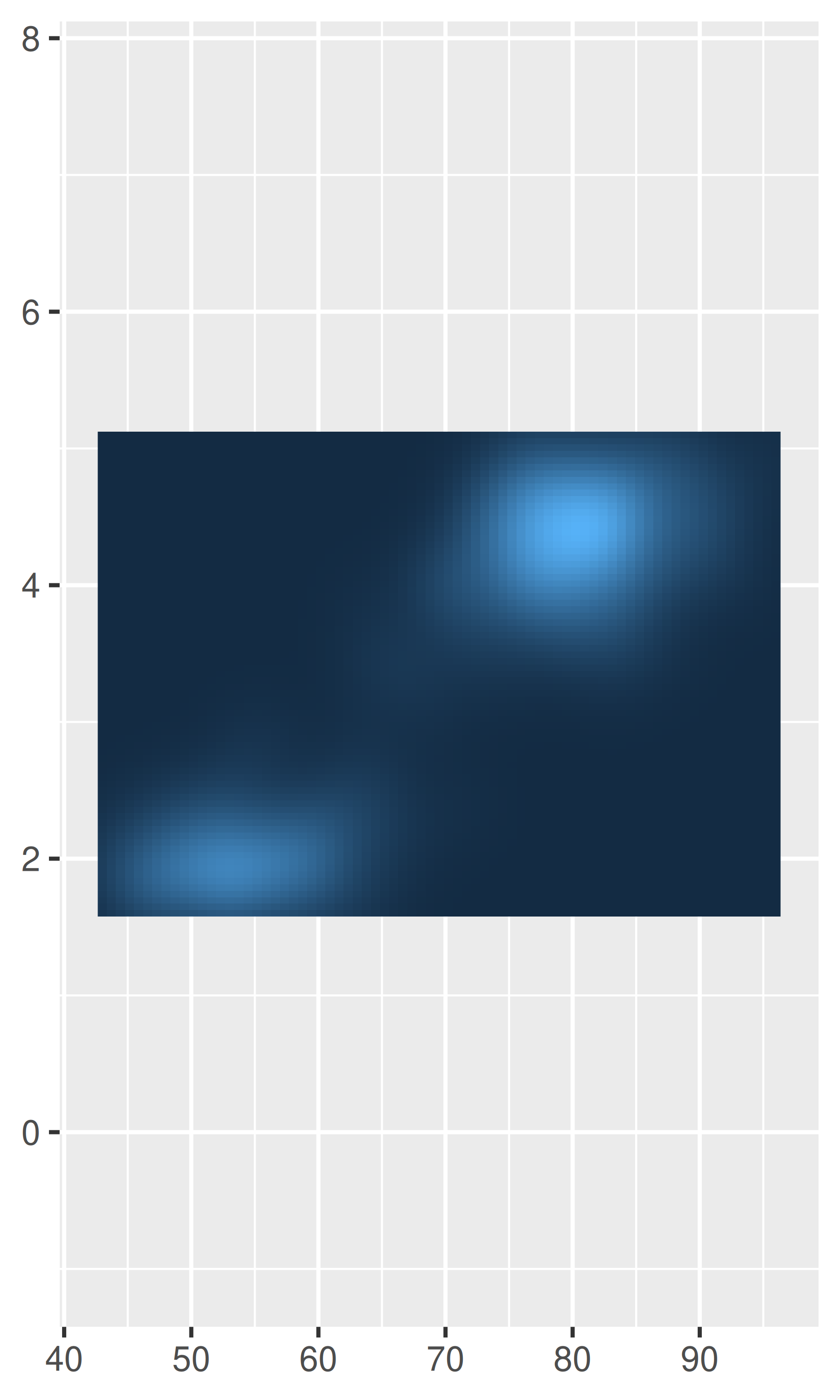
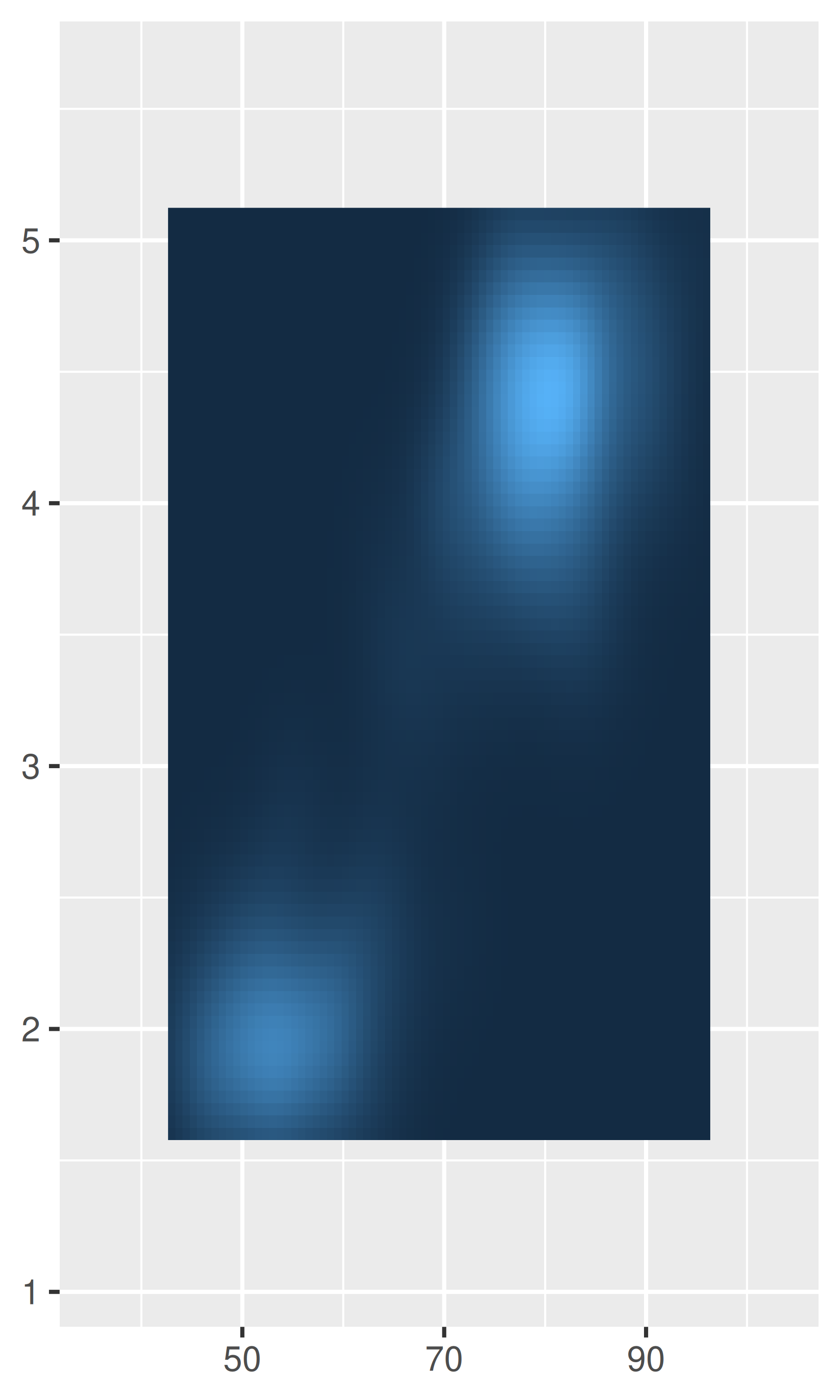
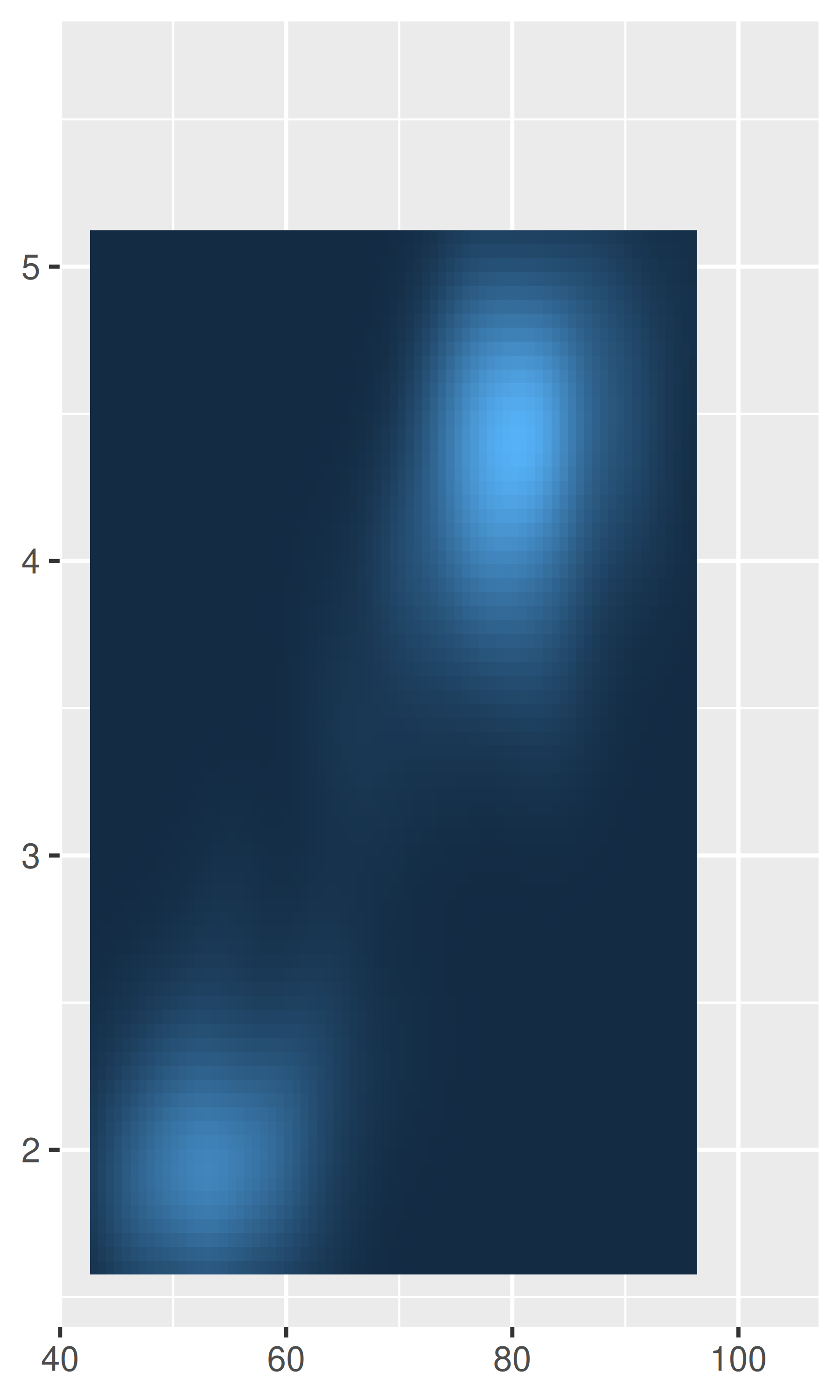
Tenga en cuenta el comportamiento diferente en los gráficos de la izquierda y del medio: el argumento add se especifica en la misma escala que la variable de datos, mientras que el argumento mult se especifica en relación con el rango del eje.
10.1.4 Rupturas
Establecer las ubicaciones de las marcas de los ejes es una tarea común de visualización de datos. En ggplot2, las marcas de eje y las marcas de leyenda son casos especiales de “saltos de escala” y se pueden modificar utilizando el argumento breaks de la función de escala. Ilustraremos esto usando un conjunto de datos de juguetes que reaparecerá en varios lugares a lo largo de esta parte del libro:
toy <- data.frame(
const = 1,
up = 1:4,
txt = letters[1:4],
big = (1:4)*1000,
log = c(2, 5, 10, 2000)
)
toy
#> const up txt big log
#> 1 1 1 a 1000 2
#> 2 1 2 b 2000 5
#> 3 1 3 c 3000 10
#> 4 1 4 d 4000 2000Para establecer pausas manualmente, pase un vector de valores de datos a breaks, o establezca breaks = NULL para eliminar por completo las pausas y las marcas de verificación correspondientes. En el siguiente gráfico, al eliminar las rupturas del eje y también se eliminan las líneas de cuadrícula correspondientes:
base <- ggplot(toy, aes(big, const)) +
geom_point() +
labs(x = NULL, y = NULL) +
scale_y_continuous(breaks = NULL)
base
Alternativamente, observe que cuando los saltos se establecen manualmente, se mueven las líneas de cuadrícula principales y las líneas de cuadrícula menores entre ellas:
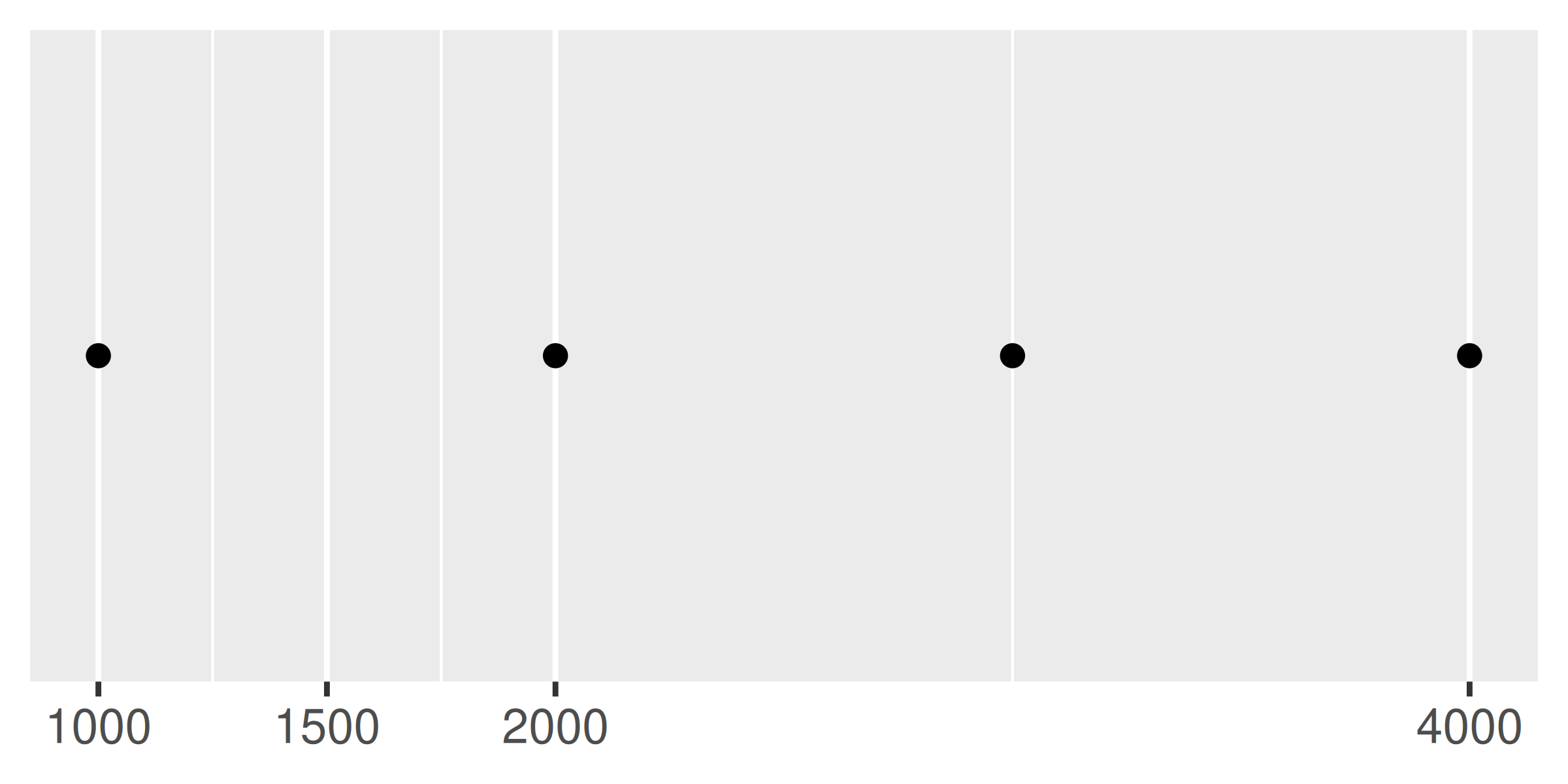
base + scale_x_continuous(breaks = c(1000, 2000, 4000))
base + scale_x_continuous(breaks = c(1000, 1500, 2000, 4000))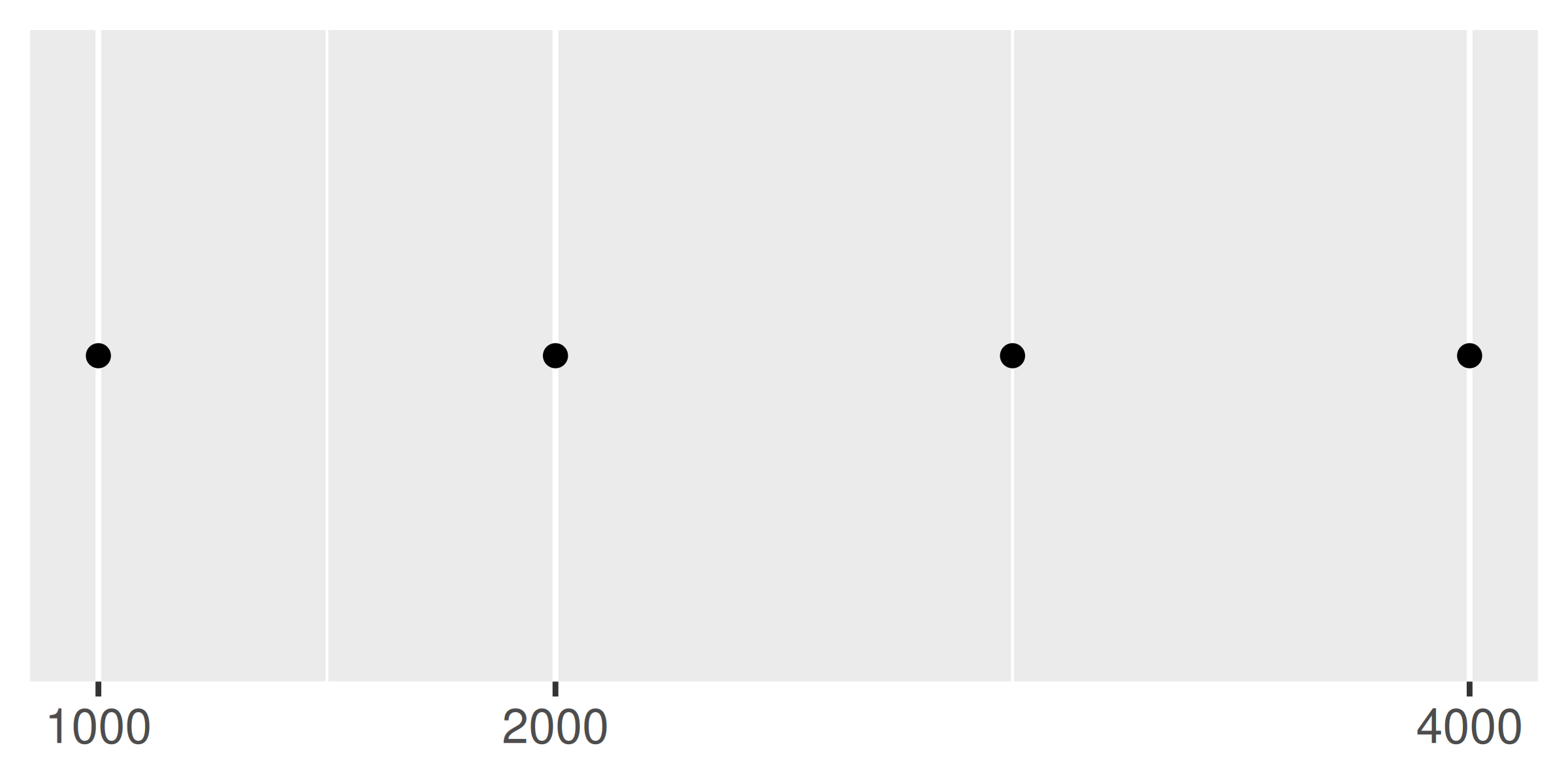
También es posible pasar una función a breaks. Esta función debe tener un argumento que especifique los límites de la escala (un vector numérico de longitud dos) y debe devolver un vector numérico de rupturas. Puedes escribir tu propia función de interrupción, pero en muchos casos no es necesaria gracias al paquete de escalas (Wickham y Seidel 2020). Proporciona varias herramientas que son útiles para este propósito:
-
scales::breaks_extended()crea rupturas automáticas para los ejes numéricos. -
scales::breaks_log()crea rupturas apropiadas para los ejes del registro. -
scales::breaks_pretty()crea rupturas “bonitas” para fechas y horas. -
scales::breaks_width()crea rupturas igualmente espaciadas.
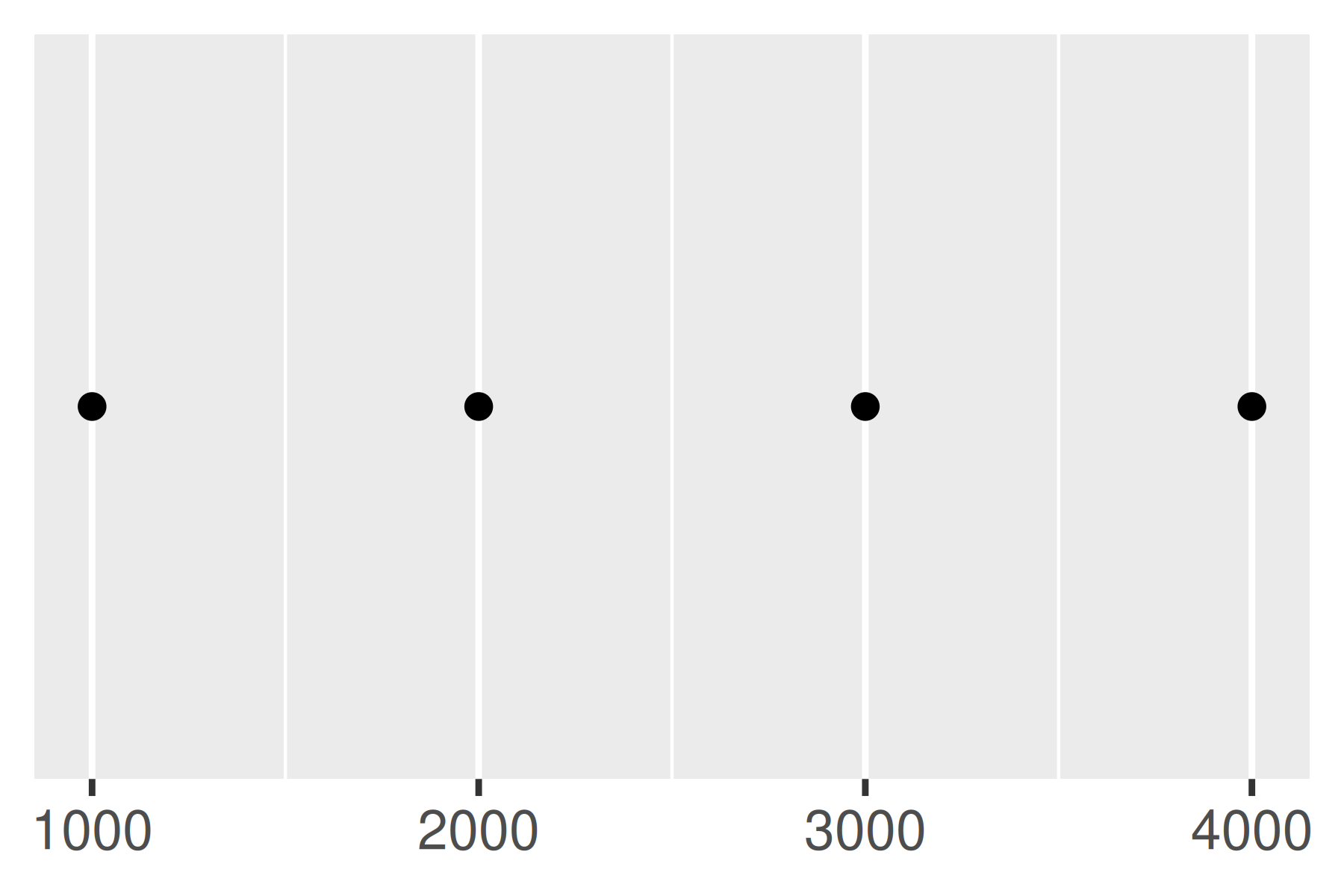
La función breaks_extended() es el método estándar utilizado en ggplot2 y, en consecuencia, los dos primeros gráficos a continuación son iguales. Podemos alterar el número deseado de rupturas configurando n = 2, como se ilustra en el tercer gráfico. Tenga en cuenta que breaks_extended() trata a n como una sugerencia en lugar de una restricción estricta. Si necesita especificar pausas exactas, es mejor hacerlo manualmente.
base
base + scale_x_continuous(breaks = scales::breaks_extended())
base + scale_x_continuous(breaks = scales::breaks_extended(n = 2))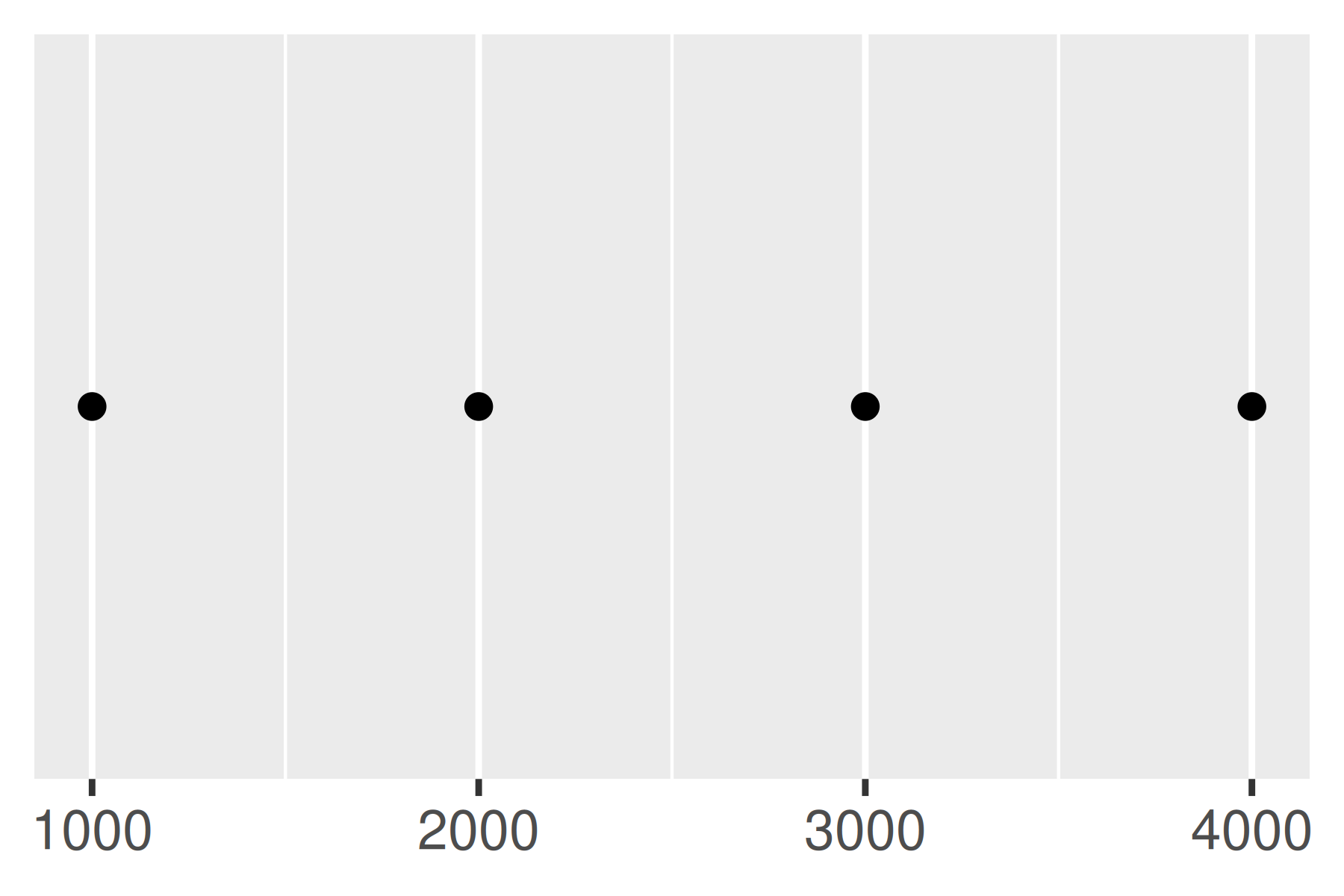

Otro enfoque que a veces resulta útil es especificar un width fijo que defina el espacio entre cortes. Para esto se utiliza la función breaks_width(). El primer ejemplo siguiente muestra cómo fijar el ancho en un valor específico; el segundo ejemplo ilustra el uso del argumento offset que desplaza todas las rupturas en una cantidad específica:
base +
scale_x_continuous(breaks = scales::breaks_width(800))
base +
scale_x_continuous(breaks = scales::breaks_width(800, offset = 200))
base +
scale_x_continuous(breaks = scales::breaks_width(800, offset = -200))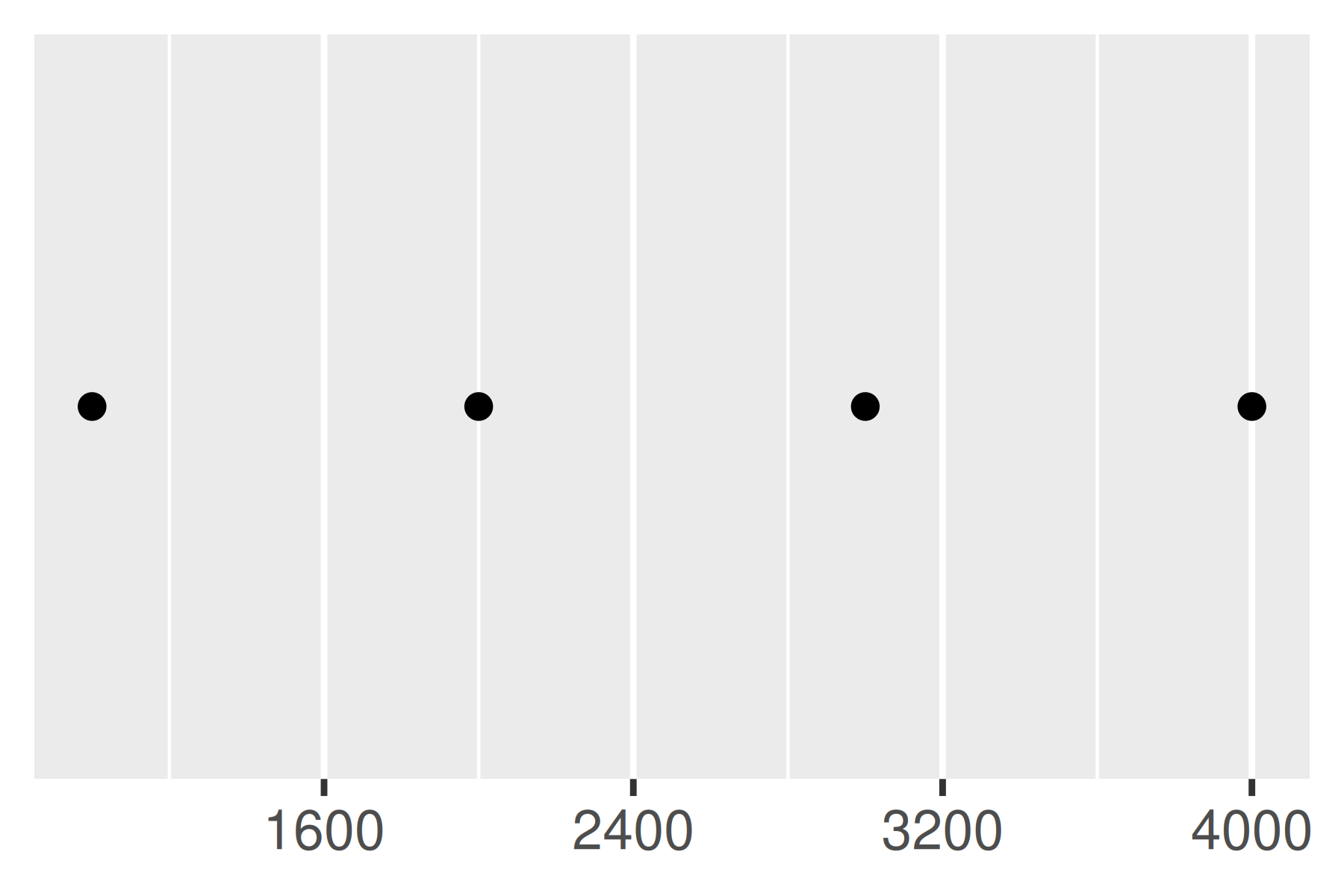
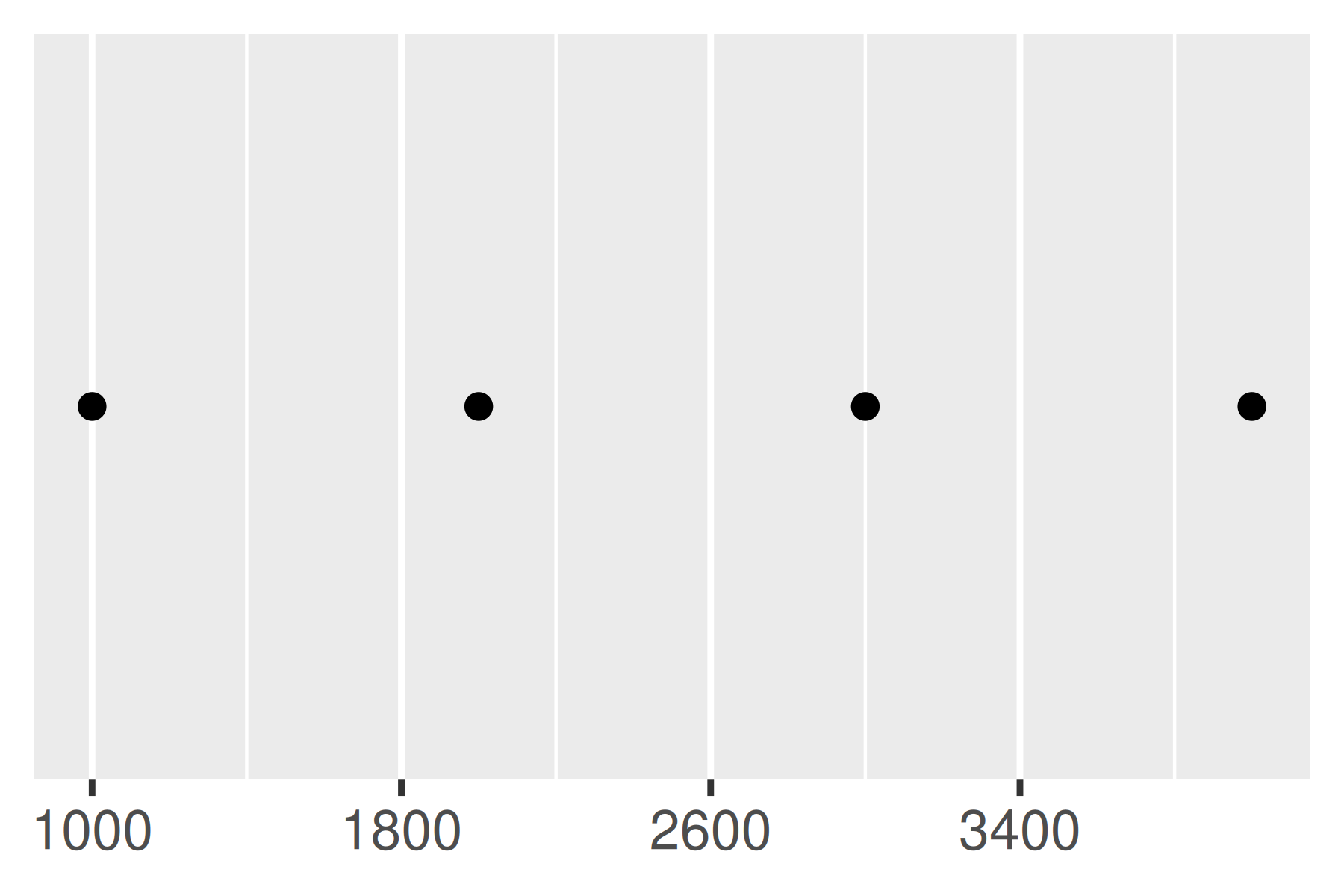
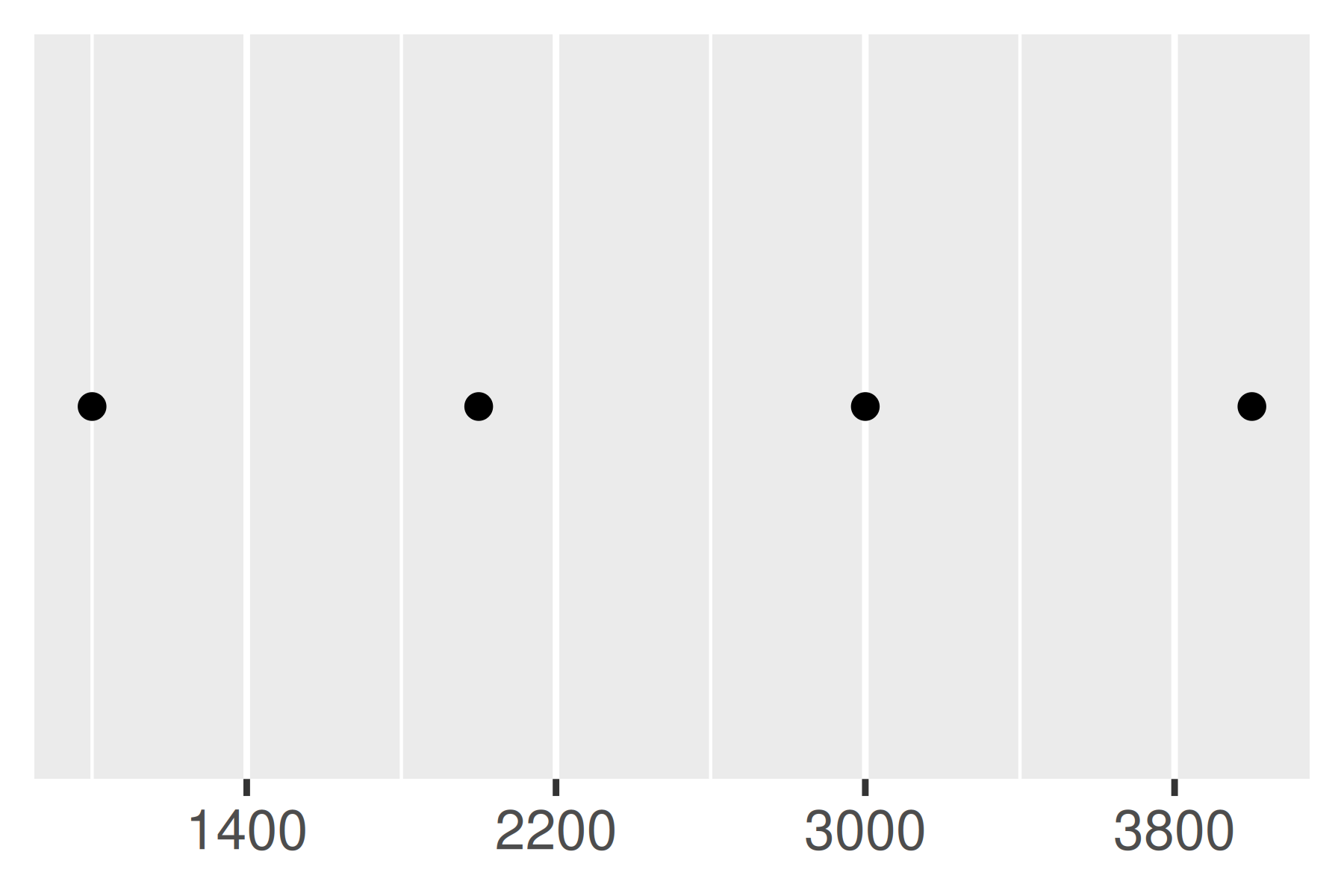
Observe la diferencia entre establecer un desplazamiento de 200 y -200.
10.1.5 Rupturas menores
Puede ajustar las rupturas menores (las líneas tenues de la cuadrícula sin etiquetar que aparecen entre las líneas principales de la cuadrícula) proporcionando un vector numérico de posiciones al argumento minor_breaks.
Las rupturas menores son particularmente útiles para las escalas logarítmicas porque dan un indicador visual claro de que la escala no es lineal. Para mostrarlos, primero crearemos un vector de valores de ruptura menores (en la escala transformada), usando %o% para generar rápidamente una tabla de multiplicar y as.numeric() para aplanar la tabla a un vector. .
mb <- unique(as.numeric(1:10 %o% 10 ^ (0:3)))
mb
#> [1] 1 2 3 4 5 6 7 8 9 10 20 30
#> [13] 40 50 60 70 80 90 100 200 300 400 500 600
#> [25] 700 800 900 1000 2000 3000 4000 5000 6000 7000 8000 9000
#> [37] 10000Los siguientes gráficos ilustran el efecto de establecer las pausas menores:
base <- ggplot(toy, aes(log, const)) +
geom_point() +
labs(x = NULL, y = NULL) +
scale_y_continuous(breaks = NULL)
base + scale_x_log10()
base + scale_x_log10(minor_breaks = mb)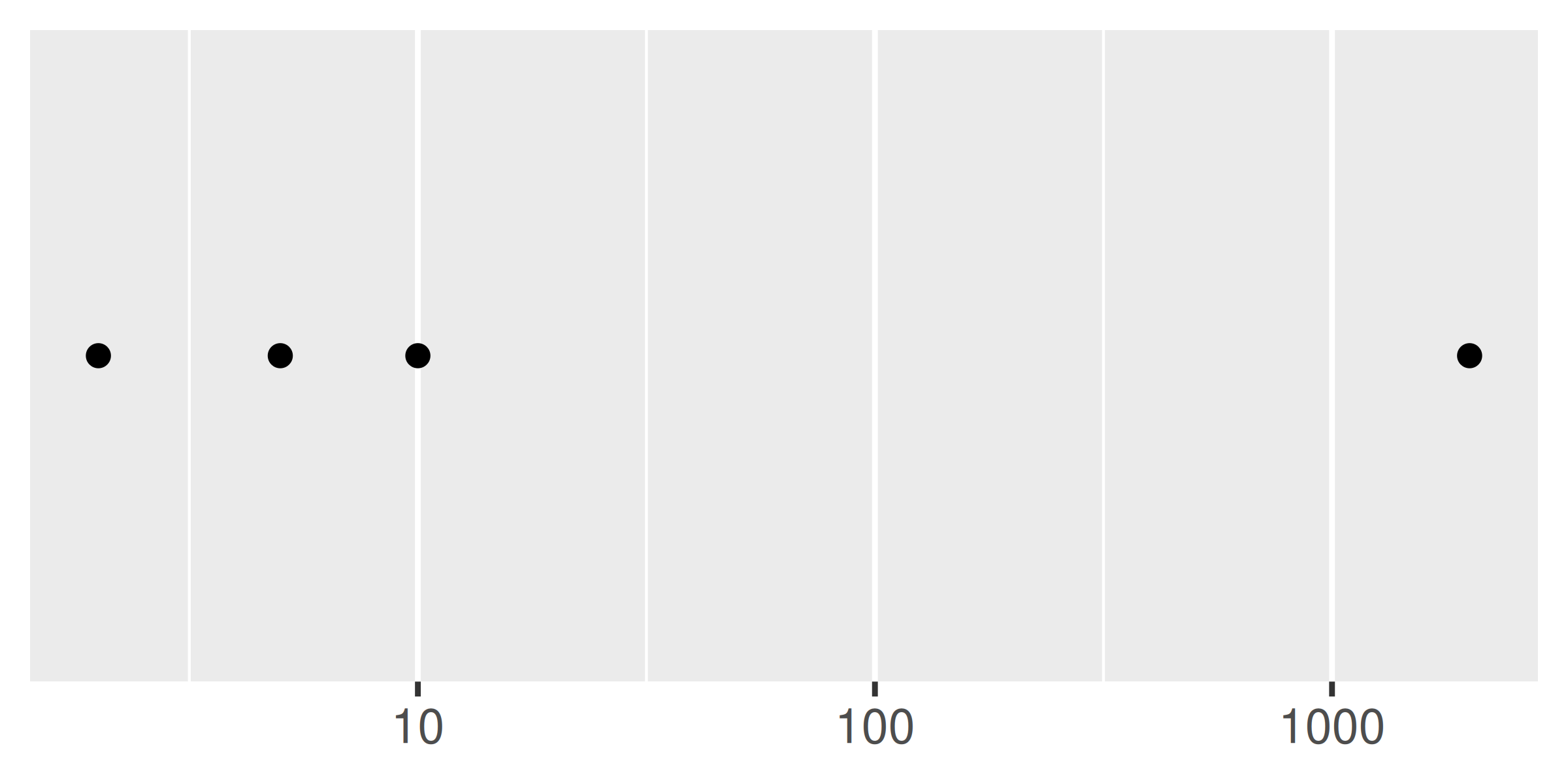
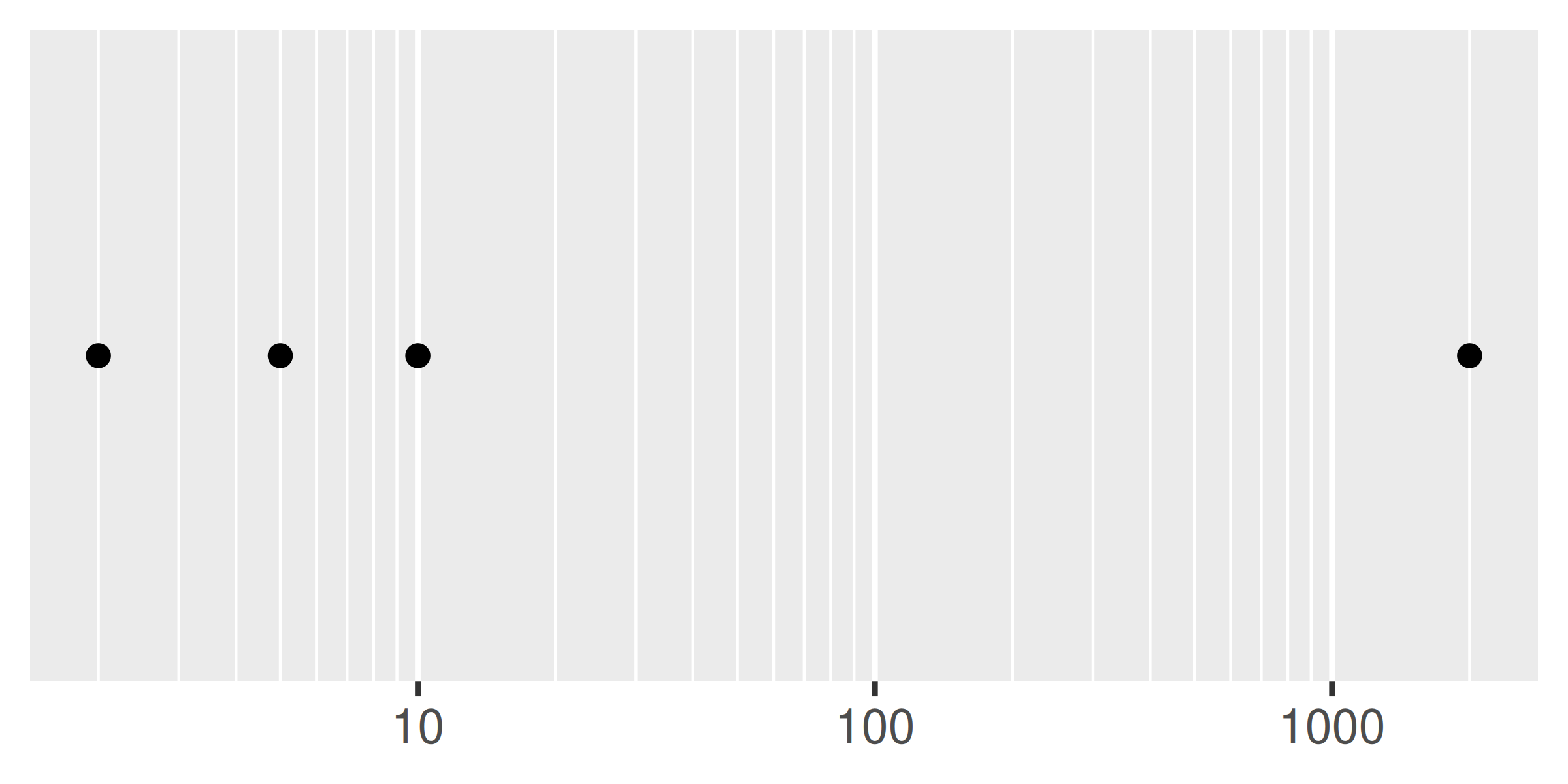
Al igual que con breaks, también puedes proporcionar una función a minor_breaks, como las funciones scales::minor_breaks_n() o scales::minor_breaks_width() que pueden ser útiles para controlar los breaks menores.
10.1.6 Etiquetas
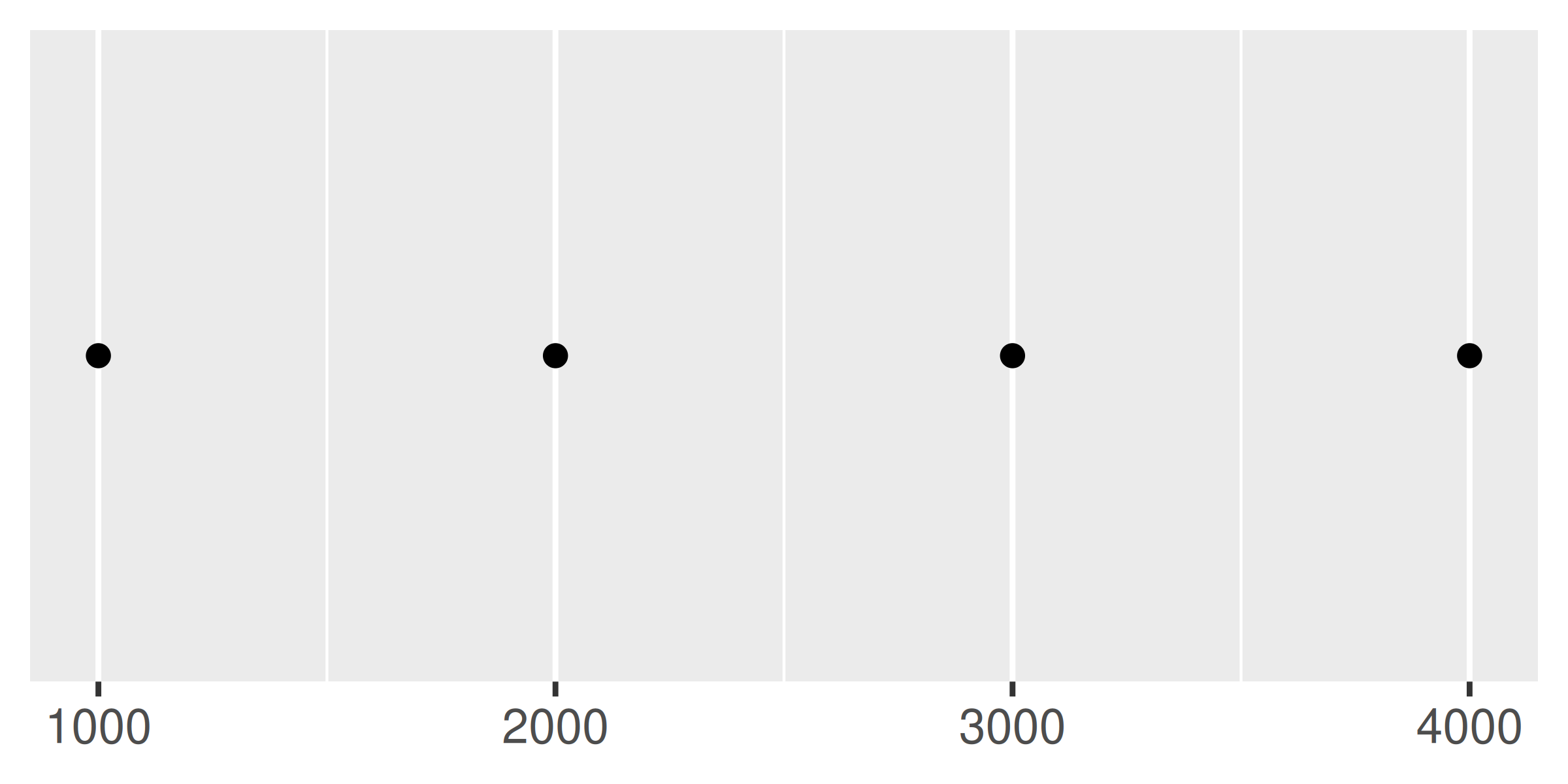
Cada ruptura está asociada con una etiqueta y estas se pueden cambiar configurando el argumento labels en la función de escala:
base <- ggplot(toy, aes(big, const)) +
geom_point() +
labs(x = NULL, y = NULL) +
scale_y_continuous(breaks = NULL)
base
base +
scale_x_continuous(
breaks = c(2000, 4000),
labels = c("2k", "4k")
) 
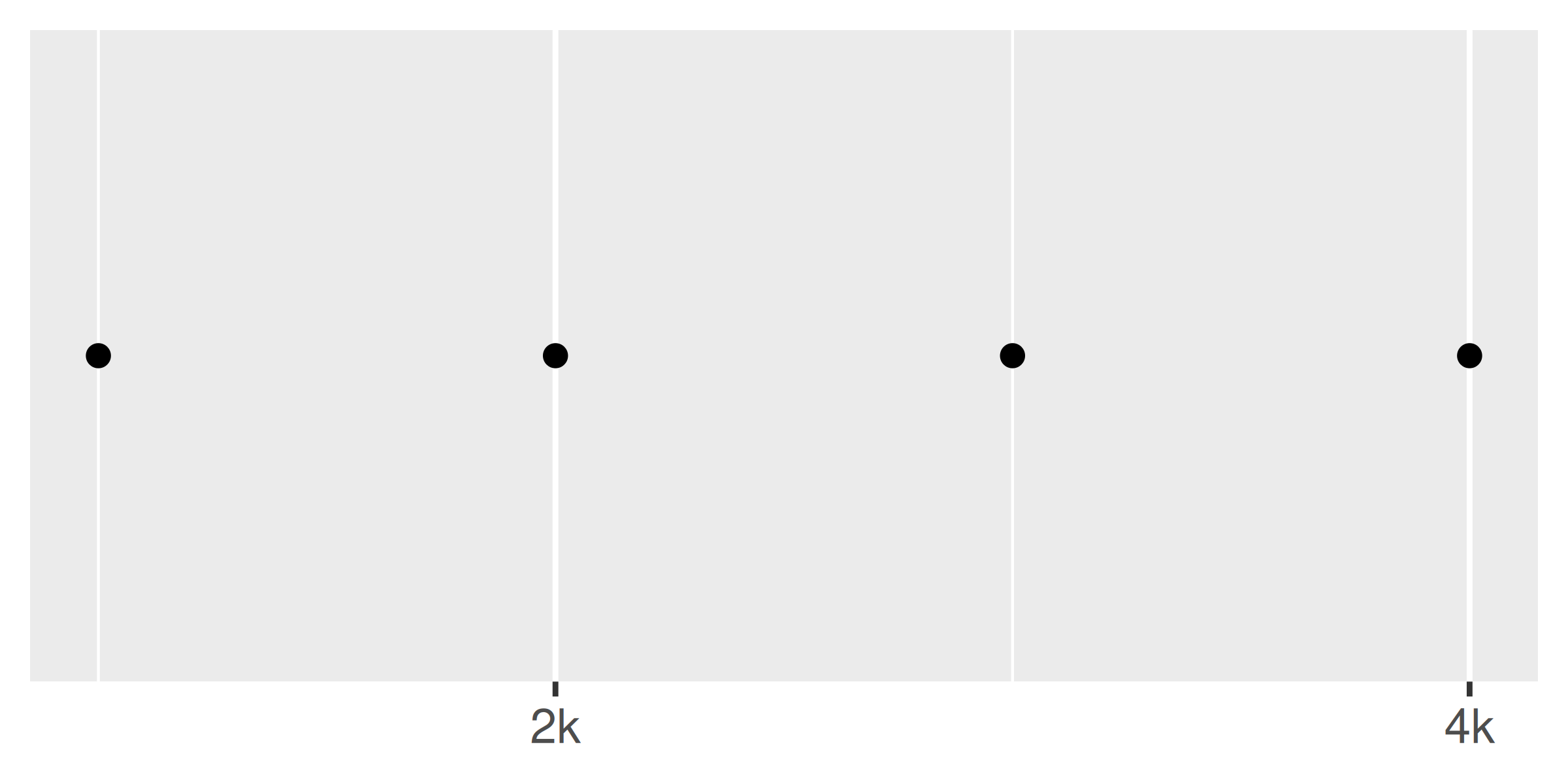
A menudo, no es necesario configurar las etiquetas manualmente y, en su lugar, puede especificar una función de etiquetado de la misma manera que lo hace con las rupturas. Una función pasada a label debe aceptar un vector numérico de saltos como entrada y devolver un vector de caracteres de etiquetas (la misma longitud que la entrada). Nuevamente, el paquete de escalas proporciona una serie de herramientas que construirán automáticamente funciones de etiquetas. Algunos de los ejemplos más útiles de datos numéricos incluyen:
-
scales::label_bytes()formatea números como kilobytes, megabytes, etc. -
scales::label_comma()formatea los números como decimales con comas agregadas. -
scales::label_dollar()formatea los números como moneda. -
scales::label_ordinal()formatea los números en orden de clasificación: 1.st, 2.nd, 3.rd, etc. -
scales::label_percent()formatea los números como porcentajes. -
scales::label_pvalue()formatea los números como valores p: <.05, <.01, .34, etc.
A continuación se muestran algunos ejemplos para ilustrar cómo se utilizan estas funciones:
base <- ggplot(toy, aes(big, const)) +
geom_point() +
labs(x = NULL, y = NULL) +
scale_x_continuous(breaks = NULL)
base
base + scale_y_continuous(labels = scales::label_percent())
base + scale_y_continuous(
labels = scales::label_dollar(prefix = "", suffix = "€")
)
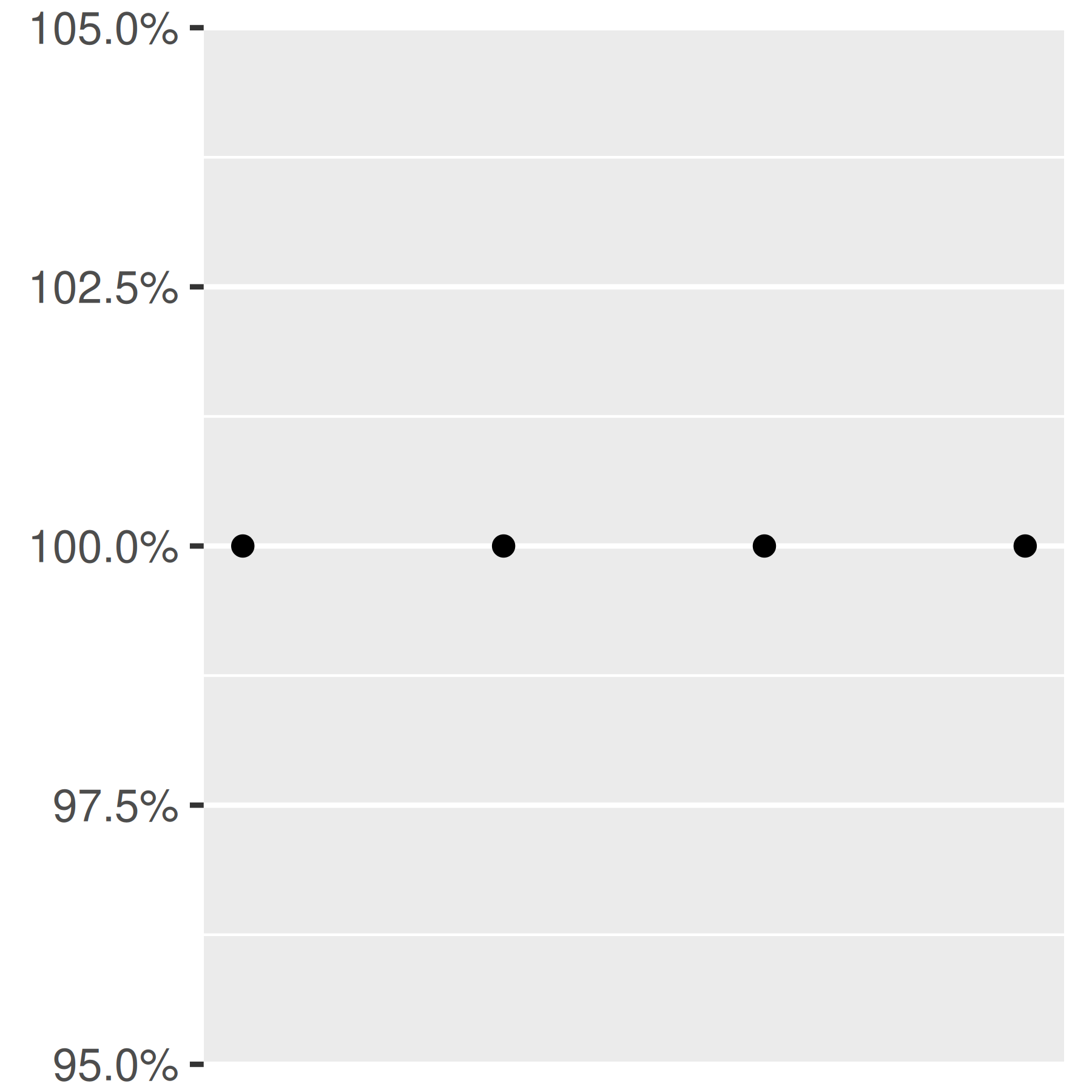
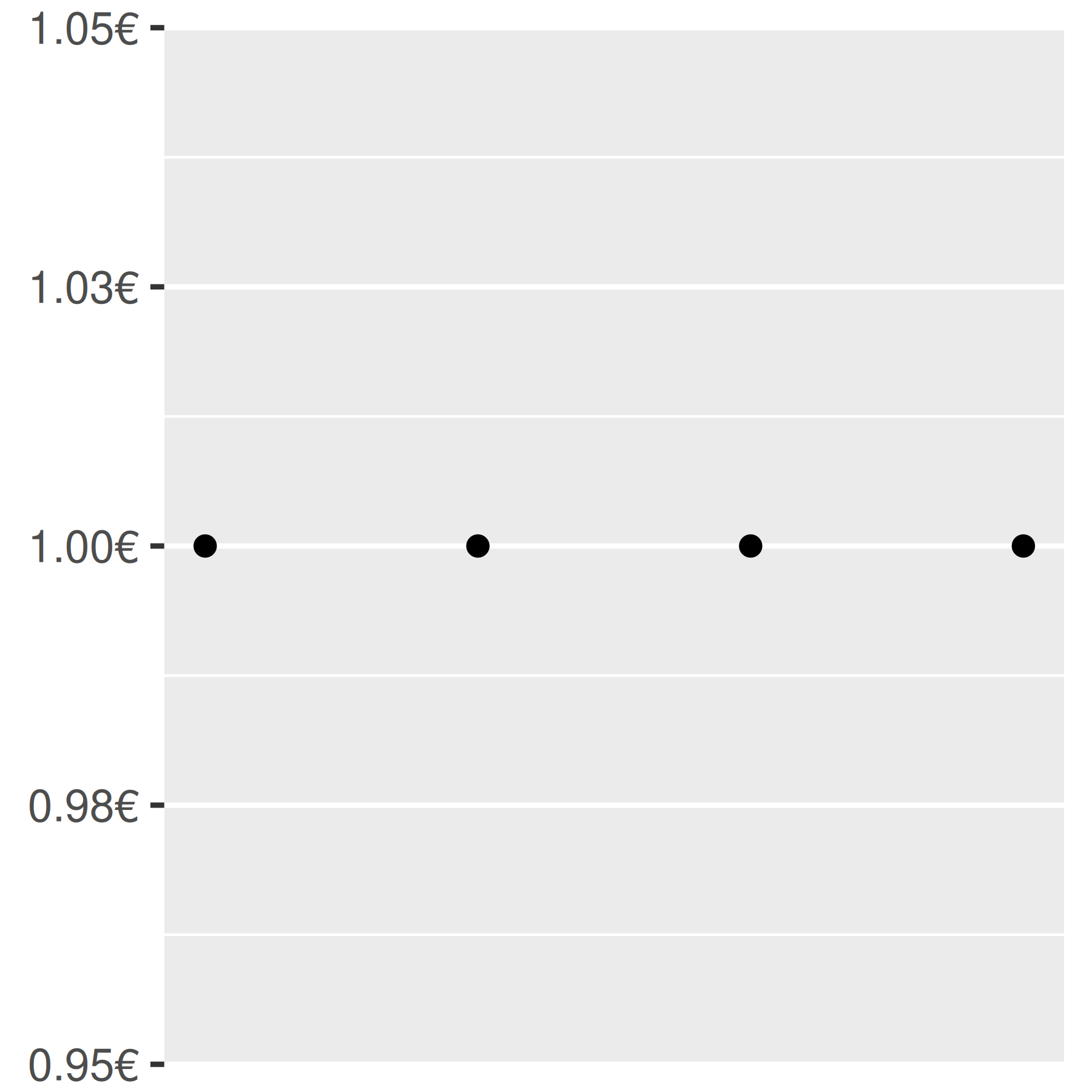
Puede suprimir etiquetas con labels = NULL. Esto eliminará las etiquetas del eje o leyenda y dejará sus otras propiedades sin cambios. Observe la diferencia entre configurar breaks = NULL y labels = NULL:
base + scale_y_continuous(breaks = NULL)
base + scale_y_continuous(labels = NULL)

10.1.7 Transformaciones
Cuando se trabaja con datos continuos, el valor predeterminado es mapear linealmente desde el espacio de datos al espacio estético. Es posible anular este valor predeterminado mediante transformaciones de escala, que alteran la forma en que se realiza este mapeo. En algunos casos no es necesario profundizar en los detalles, porque existen funciones convenientes como scale_x_log10(), scale_x_reverse() que puede hacer el trabajo por usted:
base <- ggplot(mpg, aes(displ, hwy)) + geom_point()
base
base + scale_x_reverse()
base + scale_y_reverse()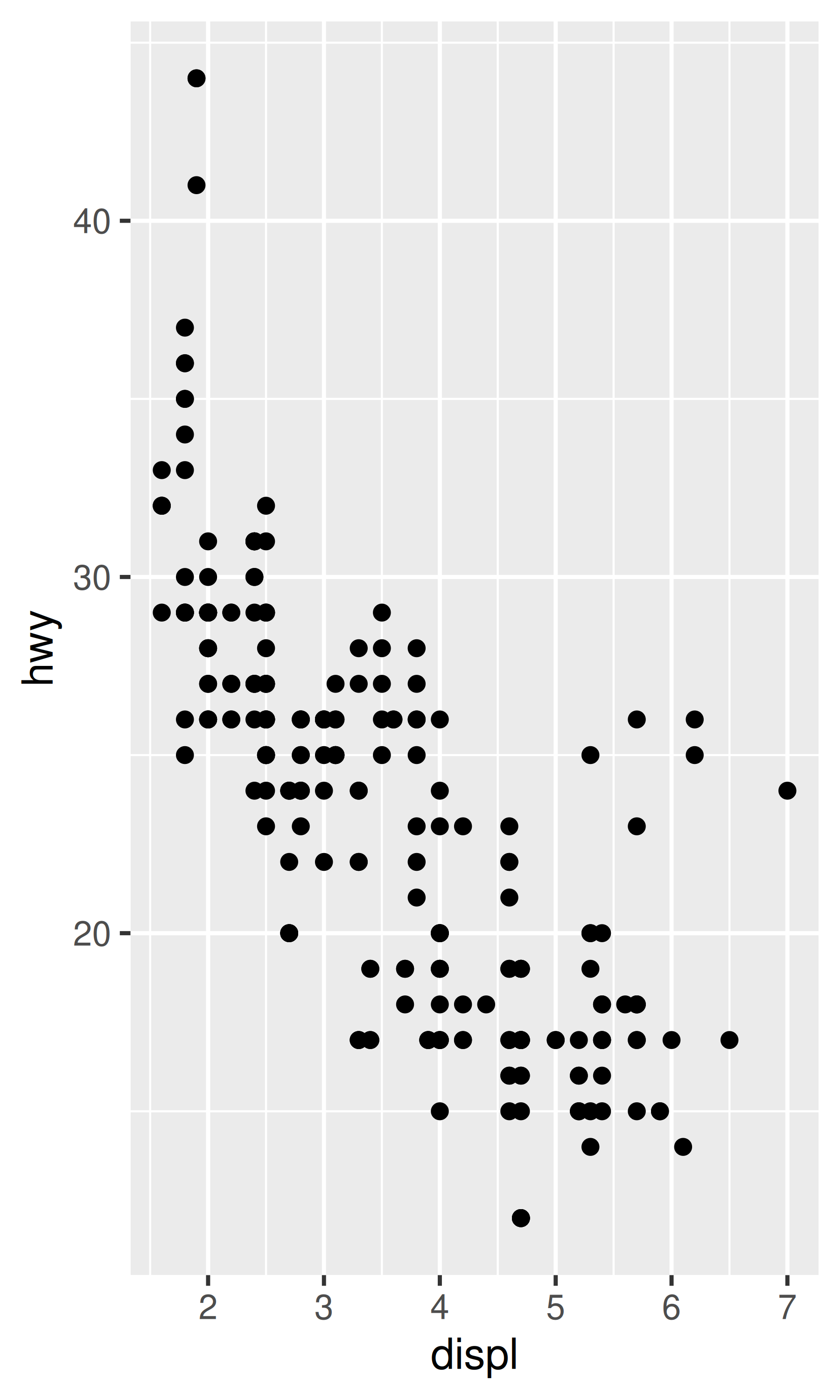
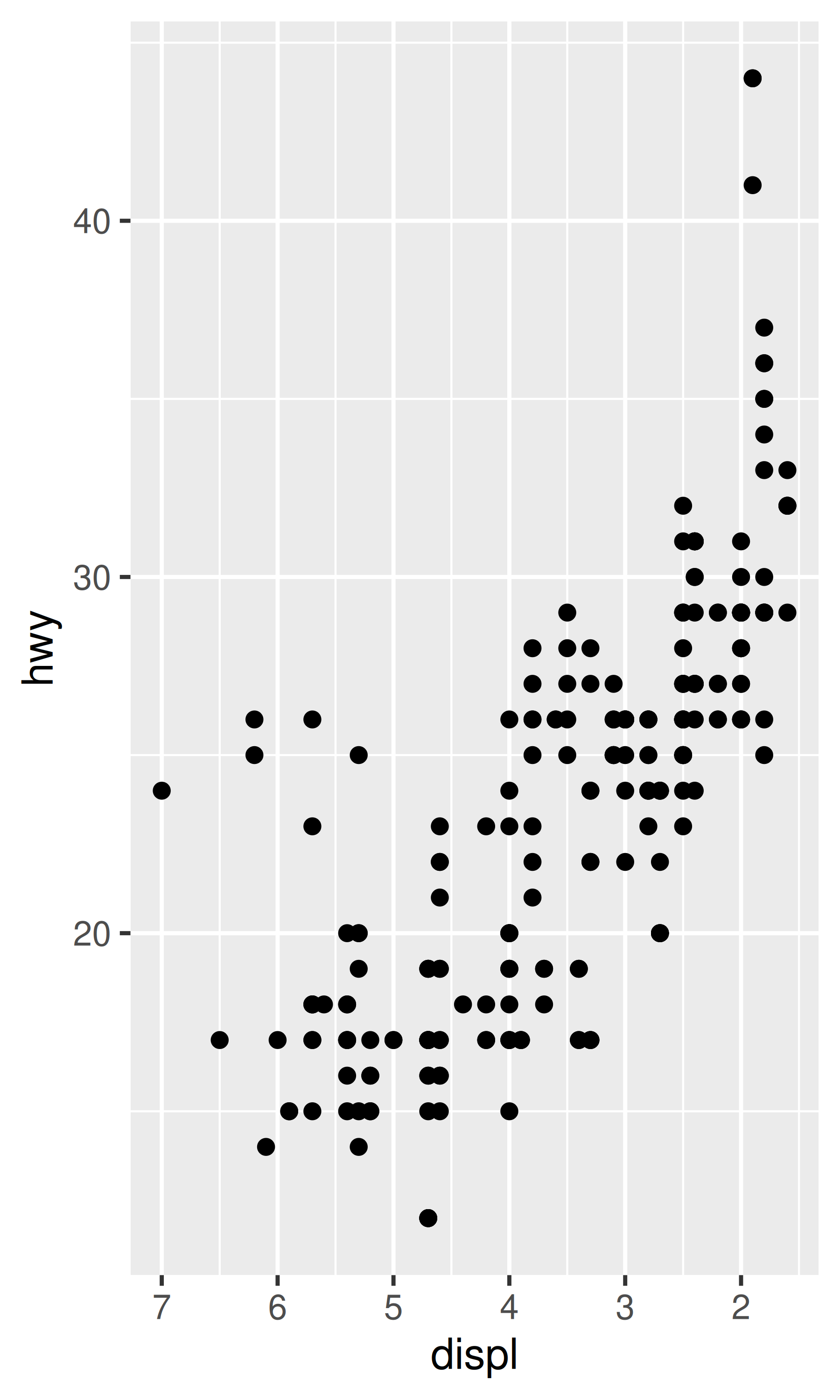
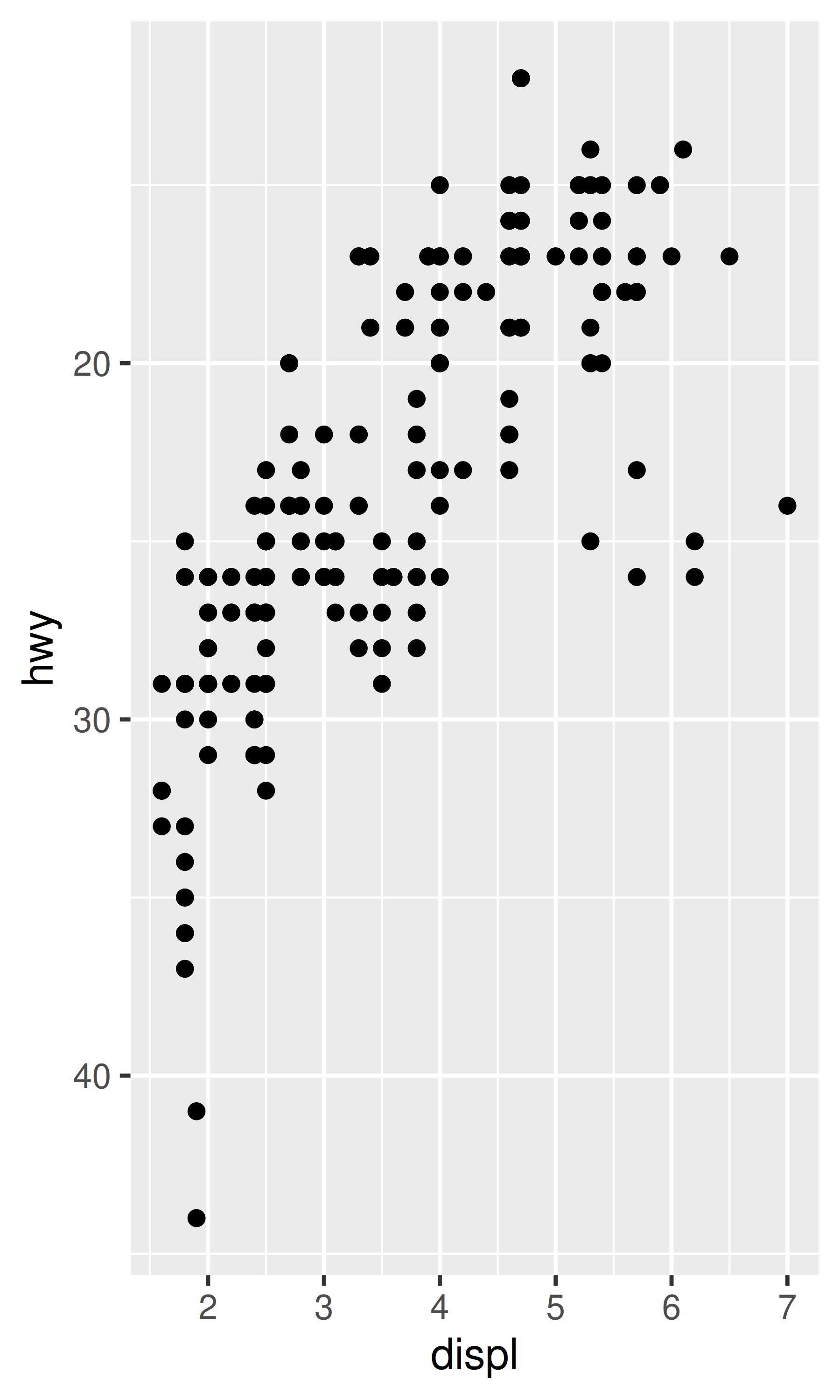
Sin embargo, incluso en estos casos una comprensión más profunda puede resultar valiosa. Cada escala continua toma un argumento trans, lo que permite el uso de una variedad de transformaciones:
# convertir de economía de combustible a consumo de combustible
ggplot(mpg, aes(displ, hwy)) +
geom_point() +
scale_y_continuous(trans = "reciprocal")
# transformación logarítmica de los ejes x e y
ggplot(diamonds, aes(price, carat)) +
geom_bin2d() +
scale_x_continuous(trans = "log10") +
scale_y_continuous(trans = "log10")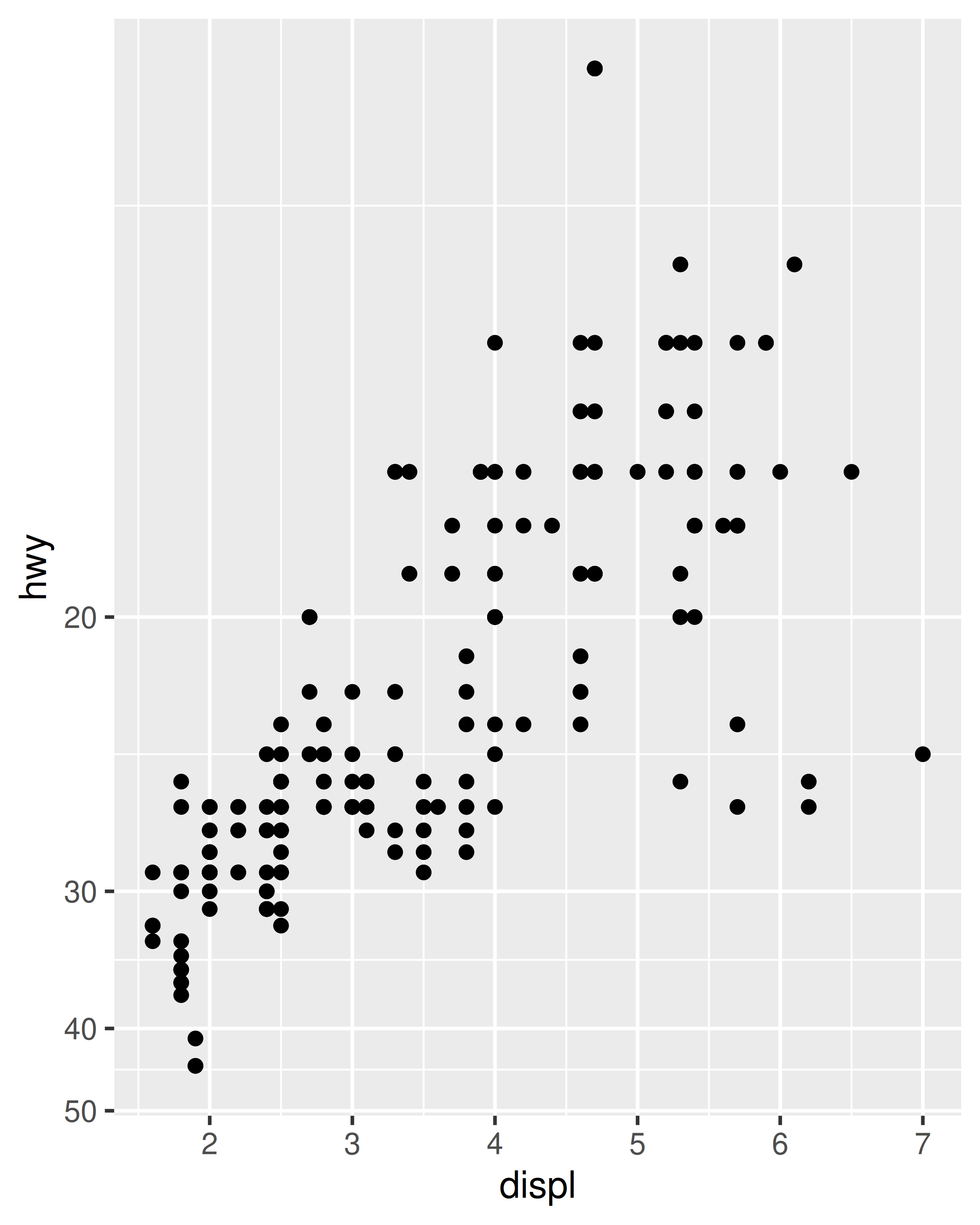
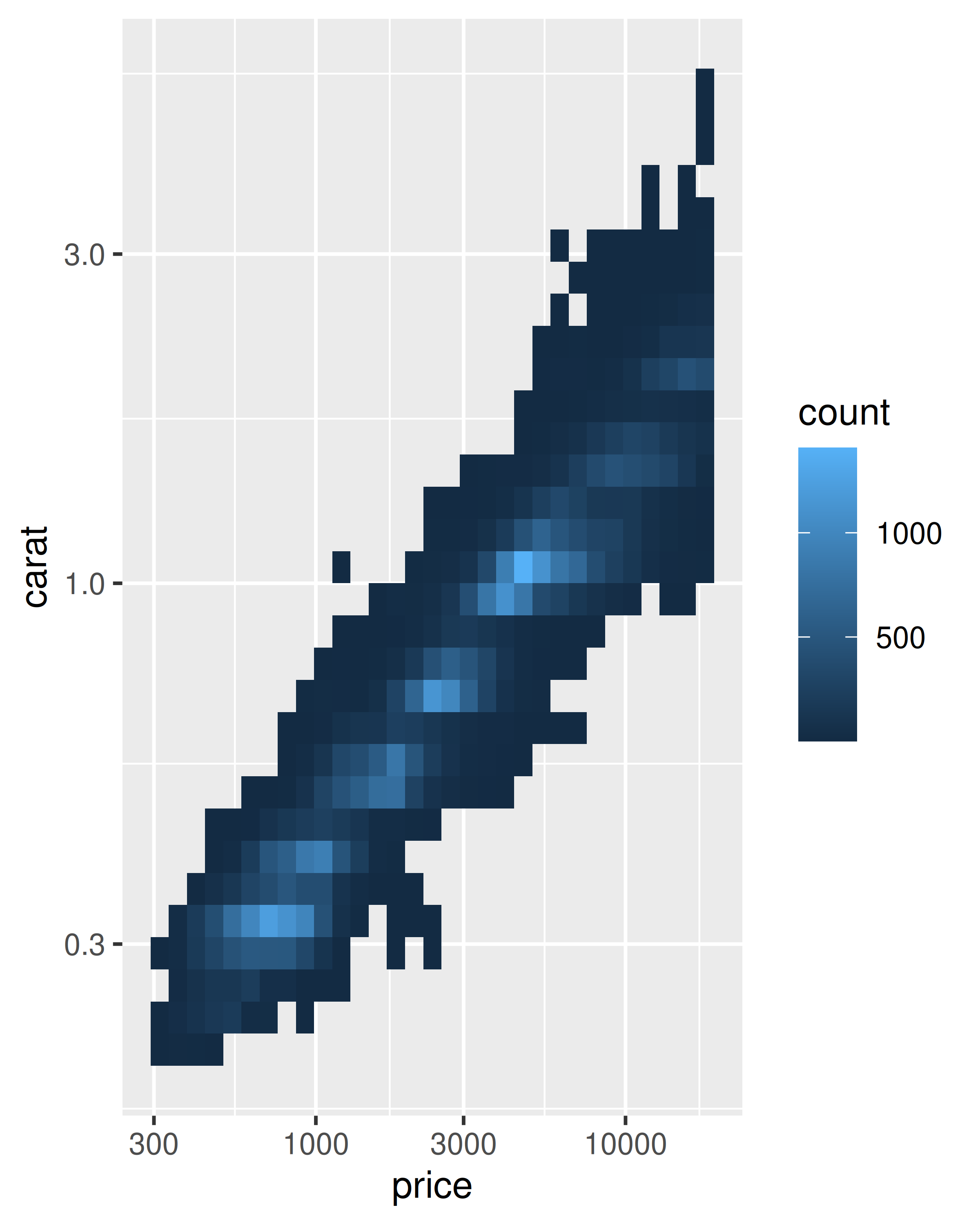
La transformación la lleva a cabo un “transformador”, que describe la transformación, su inversa y cómo dibujar las etiquetas. Puedes construir tu propio transformador usando scales::trans_new(), pero como lo ilustran los gráficos anteriores, ggplot2 comprende muchas transformaciones comunes proporcionadas por el paquete scales. La siguiente tabla enumera algunas de las variantes más comunes:
| Nombre | Transformador | Función \(f(x)\) | Inversa \(f^{-1}(x)\) |
|---|---|---|---|
"asn" |
scales::asn_trans() |
\(\tanh^{-1}(x)\) | \(\tanh(y)\) |
"exp" |
scales::exp_trans() |
\(e ^ x\) | \(\log(y)\) |
"identity" |
scales::identity_trans() |
\(x\) | \(y\) |
"log" |
scales::log_trans() |
\(\log(x)\) | \(e ^ y\) |
"log10" |
scales::log10_trans() |
\(\log_{10}(x)\) | \(10 ^ y\) |
"log2" |
scales::log2_trans() |
\(\log_2(x)\) | \(2 ^ y\) |
"logit" |
scales::logit_trans() |
\(\log(\frac{x}{1 - x})\) | \(\frac{1}{1 + e(y)}\) |
"probit" |
scales::probit_trans() |
\(\Phi(x)\) | \(\Phi^{-1}(y)\) |
"reciprocal" |
scales::reciprocal_trans() |
\(x^{-1}\) | \(y^{-1}\) |
"reverse" |
scales::reverse_trans() |
\(-x\) | \(-y\) |
"sqrt" |
scales::scale_x_sqrt() |
\(x^{1/2}\) | \(y ^ 2\) |
Puede especificar el argumento trans como una cadena que contiene el nombre de la transformación o llamando al transformador directamente. Los siguientes son equivalentes:
ggplot(mpg, aes(displ, hwy)) +
geom_point() +
scale_y_continuous(trans = "reciprocal")
ggplot(mpg, aes(displ, hwy)) +
geom_point() +
scale_y_continuous(trans = scales::reciprocal_trans())En algunos casos, ggplot2 simplifica esto aún más y proporciona funciones convenientes para las transformaciones más comunes: scale_x_log10(), scale_x_sqrt() y scale_x_reverse() proporcionan la transformación relevante en el eje x, con funciones similares proporcionadas. para el eje y. Por tanto, estas dos especificaciones de gráfica también son equivalentes:
ggplot(diamonds, aes(price, carat)) +
geom_bin2d() +
scale_x_continuous(trans = "log10") +
scale_y_continuous(trans = "log10")
ggplot(diamonds, aes(price, carat)) +
geom_bin2d() +
scale_x_log10() +
scale_y_log10()Tenga en cuenta que no hay nada que le impida realizar estas transformaciones manualmente. Por ejemplo, en lugar de usar scale_x_log10() para transformar la escala, podría transformar los datos y trazar log10(x). La apariencia de la geom será la misma, pero las etiquetas de marca serán diferentes. Específicamente, si utiliza una escala transformada, los ejes se etiquetarán en el espacio de datos original; Si transforma los datos, los ejes se etiquetarán en el espacio transformado. Como consecuencia, estas especificaciones de la gráfica son ligeramente diferentes:
# transformación manual
ggplot(mpg, aes(log10(displ), hwy)) +
geom_point()
# transformar usando escalas
ggplot(mpg, aes(displ, hwy)) +
geom_point() +
scale_x_log10()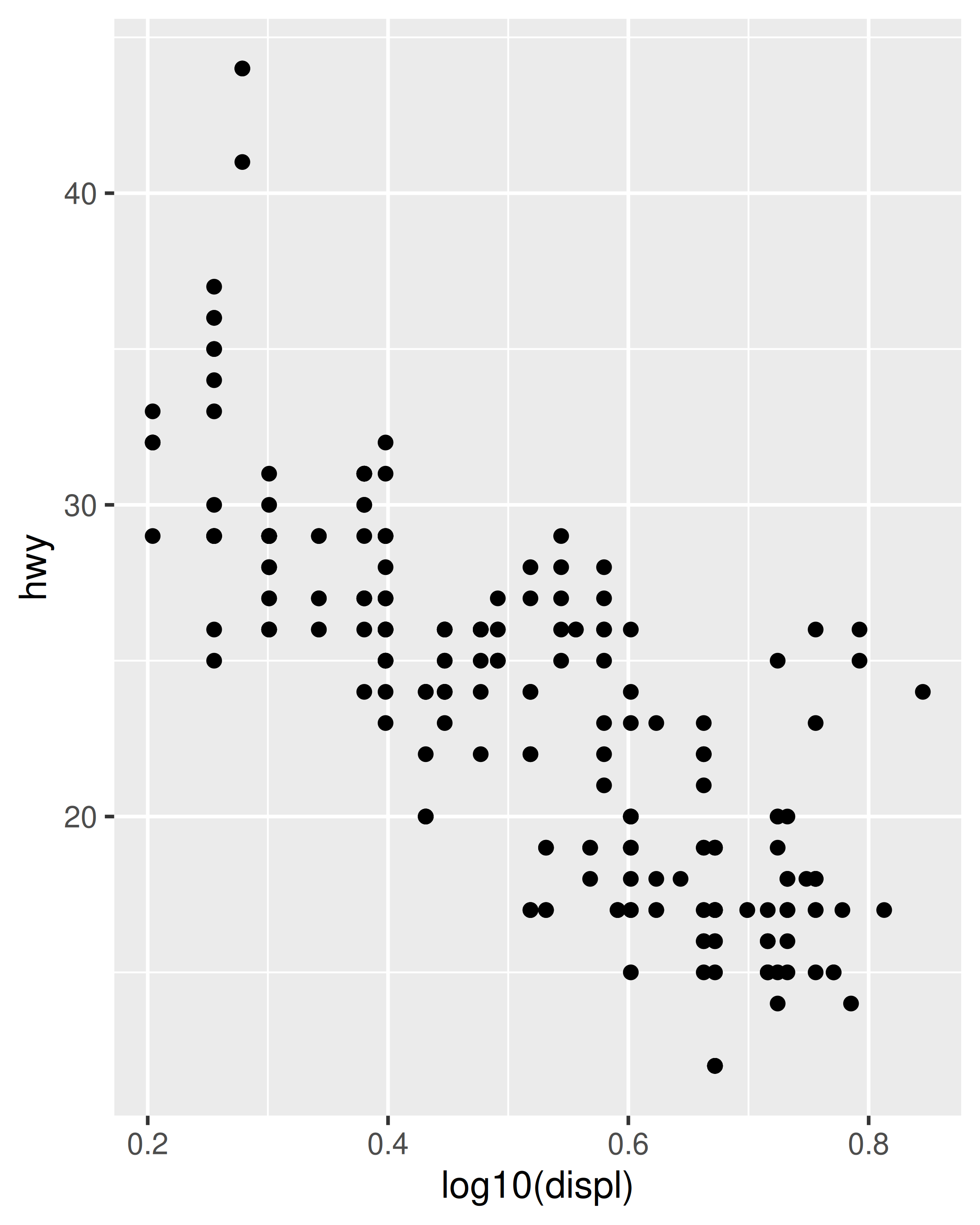
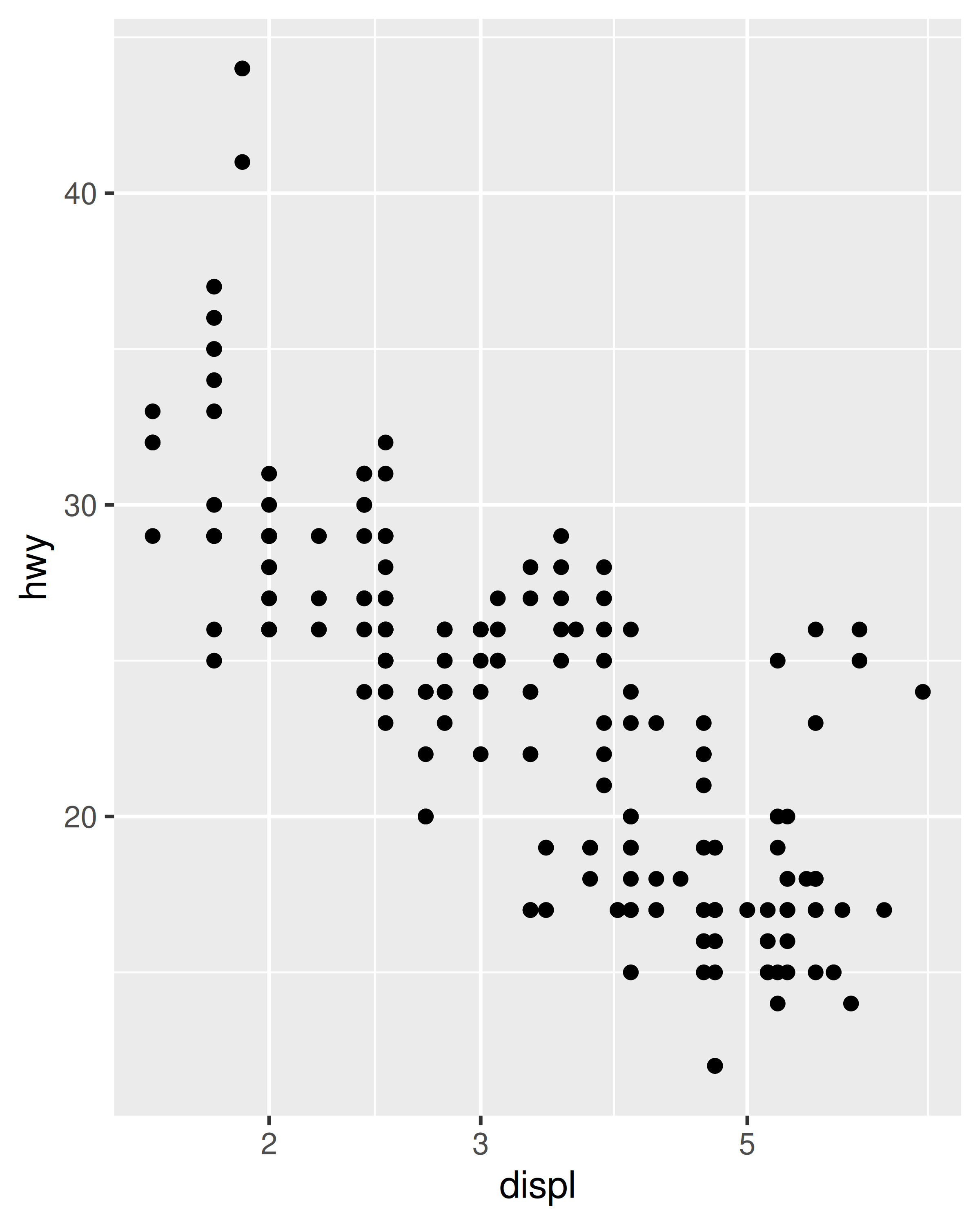
Independientemente del método que utilice, la transformación se produce antes de cualquier resúmenes estadísticos. Para transformar después del cálculo estadístico utilice coord_trans(). Consulte Sección 15.1 para obtener más detalles sobre los sistemas de coordenadas y Sección 14.6 si necesita transformar algo que no sea una escala de posición numérica.
10.2 Escalas de posición de fecha y hora
Un caso especial de posición numérica surge cuando una estética se asigna a un tipo de fecha/hora. Ejemplos de tipos de fecha/hora incluyen las clases base Date (para fechas) y POSIXct (para fechas y horas), así como la clase hms para valores de “hora del día” proporcionada por el paquete hms [@ hms]. Si sus fechas están en un formato diferente, necesitará convertirlas usando as.Date(), as.POSIXct() o hms::as_hms(). También puede encontrar útil el paquete lubridate para manipular datos de fecha/hora. (Grolemund y Wickham 2011).
Suponiendo que tiene datos formateados apropiadamente asignados a la estética x, ggplot2 usará scale_x_date() como escala predeterminada para fechas y scale_x_datetime() como escala predeterminada para datos de fecha y hora. Las escalas correspondientes para otras estéticas siguen las reglas de nomenclatura habituales. Las escalas de fechas se comportan de manera similar a otras escalas continuas, pero contienen argumentos adicionales que le permiten trabajar en unidades compatibles con las fechas. Esta sección analiza las escalas de fecha y hora para la estética de la posición: consulte ?sec-date-color-scales para conocer la estética del color y el relleno.
10.2.1 Rupturas
El argumento date_breaks le permite colocar saltos por unidades de fecha (años, meses, semanas, días, horas, minutos y segundos). Por ejemplo, date_breaks = "2 weeks" colocará una marca importante cada dos semanas y date_breaks = "15 years" las colocará cada 15 años:
date_base <- ggplot(economics, aes(date, psavert)) +
geom_line(na.rm = TRUE) +
labs(x = NULL, y = NULL)
date_base
date_base + scale_x_date(date_breaks = "15 years")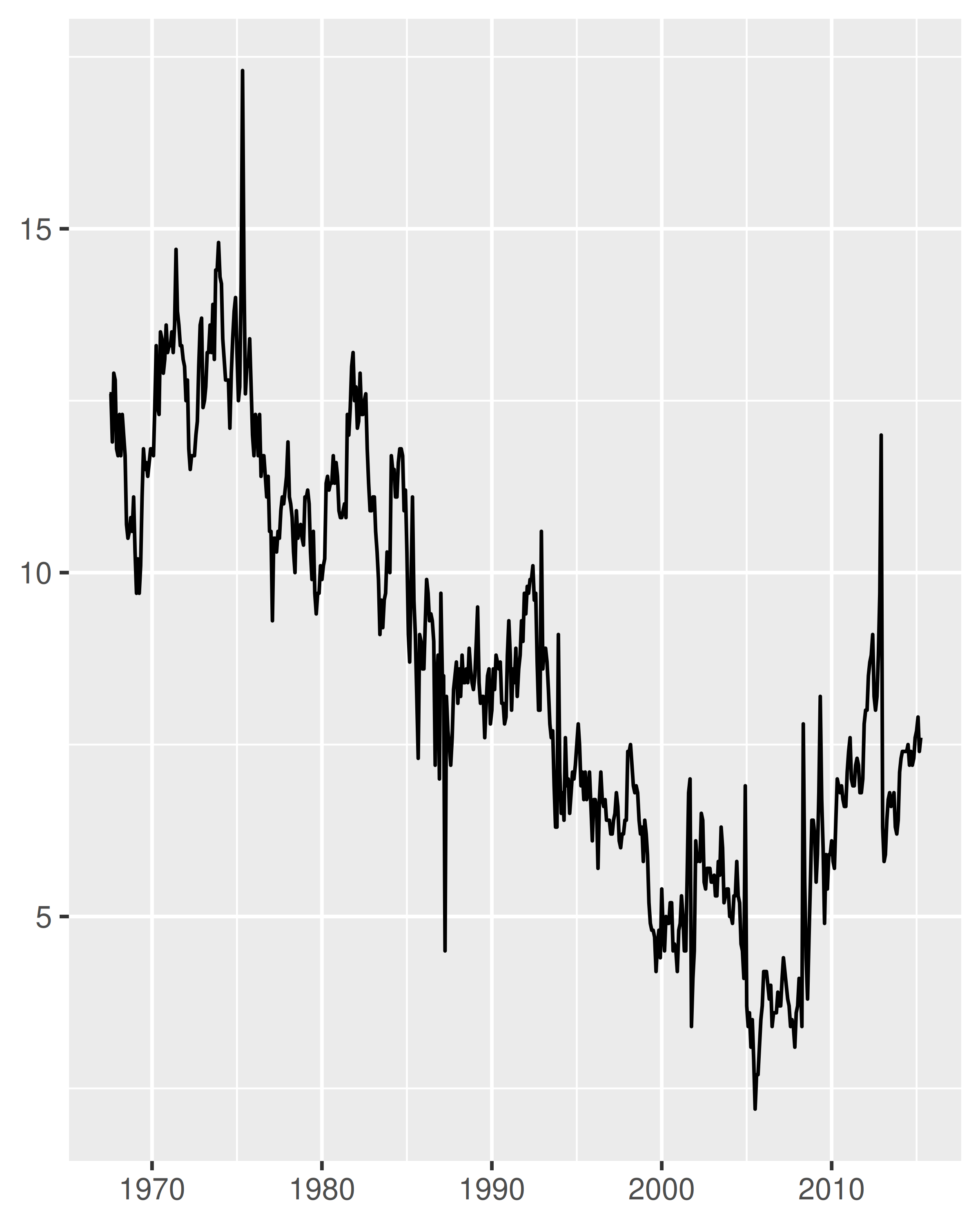
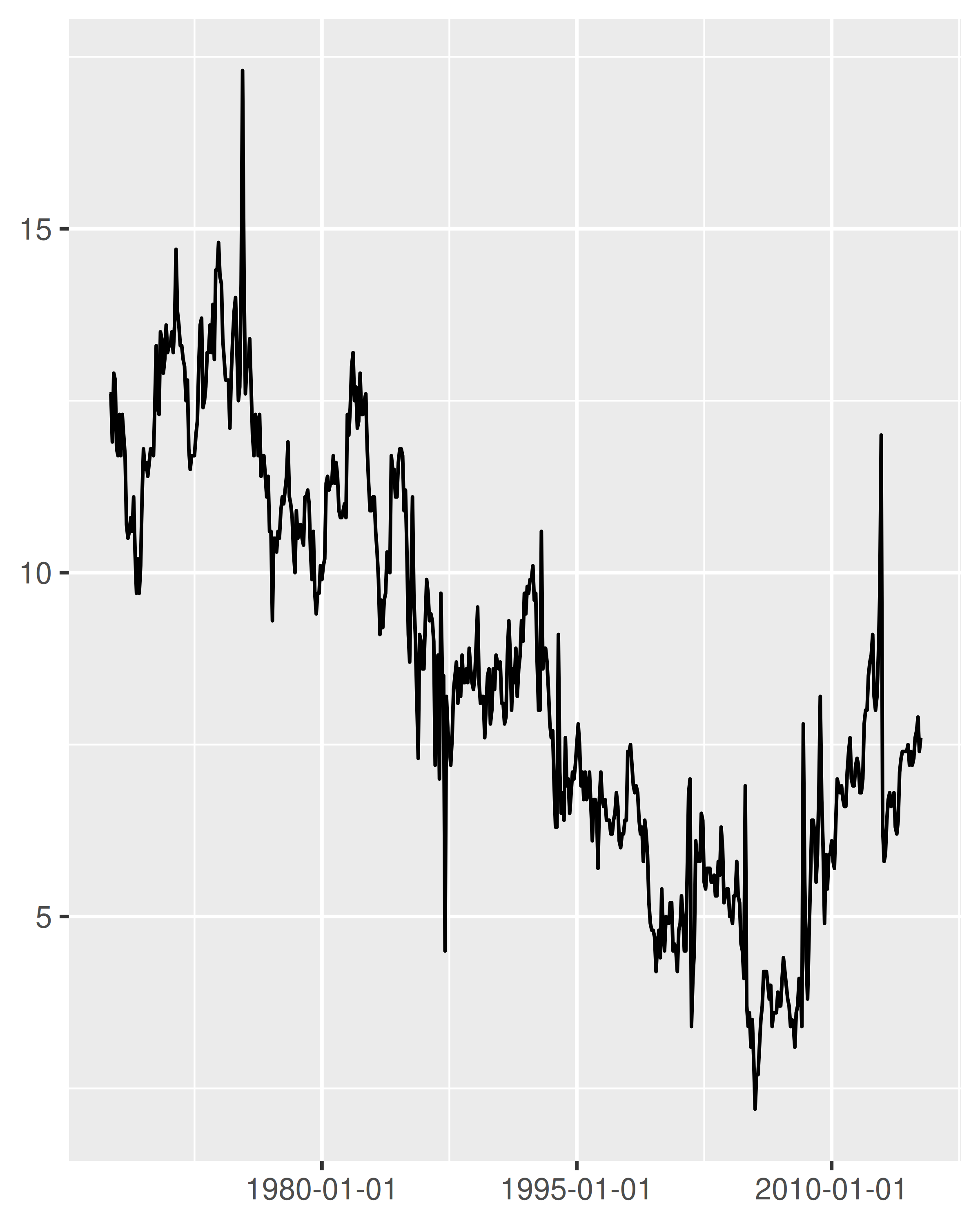
En comparación con el gráfico de la izquierda, dos cosas han cambiado en el gráfico de la derecha: las marcas se colocan en intervalos de 15 años y el formato de la etiqueta ha cambiado. Analizaremos el etiquetado de fechas en Sección 10.2.3, pero por ahora nos centraremos en las pausas.
Para entender cómo ggplot2 interpreta date_breaks = "15 years", es útil tener en cuenta que es simplemente una abreviatura conveniente para configurar breaks = scales::breaks_width("15 years"). La forma más larga suele ser innecesaria, pero puede ser útil si, como se explica en Sección 10.1.4, desea especificar un offset. Por ejemplo, supongamos que el objetivo es trazar datos que abarquen un año calendario, con rupturas mensuales. Especificar date_breaks = "1 month" es equivalente a configurar scales::breaks_width("1 month"), lo que produce estas rupturas:
the_year <- as.Date(c("2021-01-01", "2021-12-31"))
set_breaks <- scales::breaks_width("1 month")
set_breaks(the_year)
#> [1] "2021-01-01" "2021-02-01" "2021-03-01" "2021-04-01" "2021-05-01"
#> [6] "2021-06-01" "2021-07-01" "2021-08-01" "2021-09-01" "2021-10-01"
#> [11] "2021-11-01" "2021-12-01" "2022-01-01"En este ejemplo, la función set_breaks() devuelta por scales::break_width() produce rupturas espaciadas con un mes de diferencia, donde la fecha de cada descanso cae en el primer día del mes. Por lo general, es sensato colocar cada pausa al comienzo del año calendario, pero hay excepciones. Quizás los datos rastrean los ingresos y gastos de un hogar en el que se paga un salario mensual el noveno día de cada mes. En esta situación puede ser sensato alinear las rupturas con los depósitos salariales. Para hacer esto, podemos establecer offset = 8 cuando definimos la función set_breaks():
set_breaks <- scales::breaks_width("1 month", offset = 8)
set_breaks(the_year)
#> [1] "2021-01-09" "2021-02-09" "2021-03-09" "2021-04-09" "2021-05-09"
#> [6] "2021-06-09" "2021-07-09" "2021-08-09" "2021-09-09" "2021-10-09"
#> [11] "2021-11-09" "2021-12-09" "2022-01-09"10.2.2 Rupturas menores
Las escalas de fecha/hora también tienen un argumento date_minor_breaks que le permite especificar las pausas menores al usar unidades de fecha, exactamente de la misma manera que lo hace date_breaks para las pausas mayores. Para ilustrar esto, definiremos un gráfico vacío con una escala de fecha en el eje y y modificaremos el tema (?sec-polising) para que las líneas de la cuadrícula sean más prominentes visualmente:
df <- data.frame(y = as.Date(c("2022-01-01", "2022-04-01")))
base <- ggplot(df, aes(y = y)) +
labs(y = NULL) +
theme_minimal() +
theme(
panel.grid.major = element_line(colour = "black"),
panel.grid.minor = element_line(colour = "grey50")
)
base + scale_y_date(date_breaks = "1 month")
base +
scale_y_date(date_breaks = "1 month", date_minor_breaks = "1 week")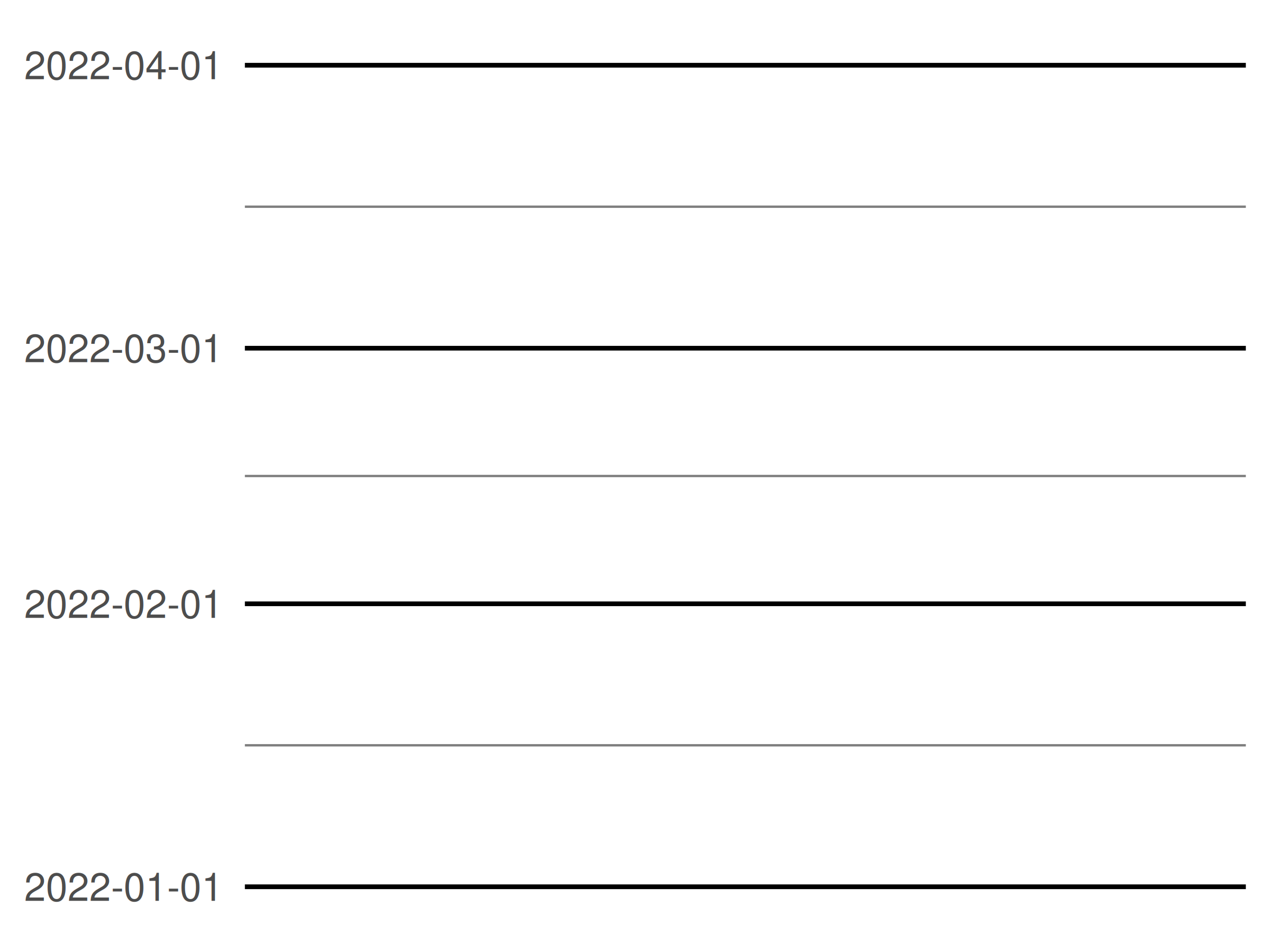

Tenga en cuenta que en el primer gráfico, las pausas menores están espaciadas uniformemente entre las pausas principales mensuales. En el segundo gráfico, las rupturas mayores y menores siguen patrones ligeramente diferentes: las rupturas menores siempre están separadas por 7 días, pero las rupturas mayores están separadas por 1 mes. Debido a que los meses varían en duración, esto genera un espaciamiento ligeramente desigual.
10.2.3 Etiquetas
Las escalas de fecha contienen un argumento labels que se comporta de manera similar al argumento correspondiente para escalas numéricas, pero a menudo es más conveniente usar el argumento date_labels. Controla la visualización de las etiquetas utilizando las mismas cadenas de formato que en strptime() y format(). Para mostrar fechas como 14/10/1979, por ejemplo, usaría la cadena "%d/%m/%Y": en esta expresión %d produce un día numérico del mes, %m produce un mes numérico y %Y produce un año de cuatro dígitos. La siguiente tabla proporciona una lista de texto de formato:
| Texto | Significado |
|---|---|
%S |
segundo (00-59) |
%M |
minuto (00-59) |
%l |
hora, en reloj de 12-horas (1-12) |
%I |
hora, en reloj de 12-horas (01-12) |
%p |
am/pm |
%H |
hora, en reloj de 24-horas (00-23) |
%a |
día de la semana, abreviado (Mon-Sun) |
%A |
día de la semana, completo (Monday-Sunday) |
%e |
día del mes (1-31) |
%d |
día del mes (01-31) |
%m |
mes, númerico (01-12) |
%b |
mes, abreviado (Jan-Dec) |
%B |
mes, completo (January-December) |
%y |
año, sin siglo (00-99) |
%Y |
año, con siglo (0000-9999) |
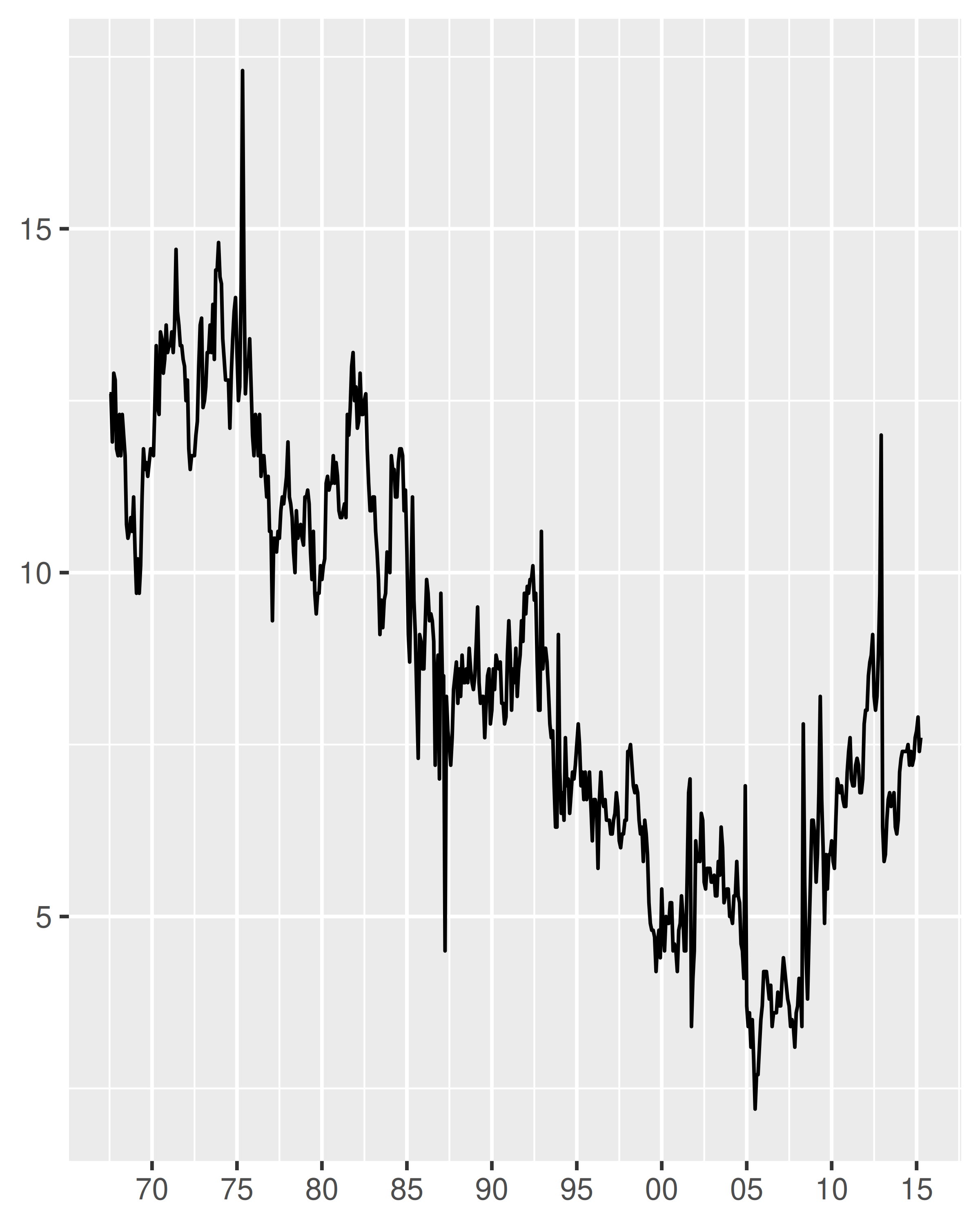
Un escenario útil para el formato de etiquetas de fecha es cuando no hay suficiente espacio para especificar un año de cuatro dígitos. El uso de %y garantiza que solo se muestren los dos últimos dígitos:
base <- ggplot(economics, aes(date, psavert)) +
geom_line(na.rm = TRUE) +
labs(x = NULL, y = NULL)
base + scale_x_date(date_breaks = "5 years")
base + scale_x_date(date_breaks = "5 years", date_labels = "%y")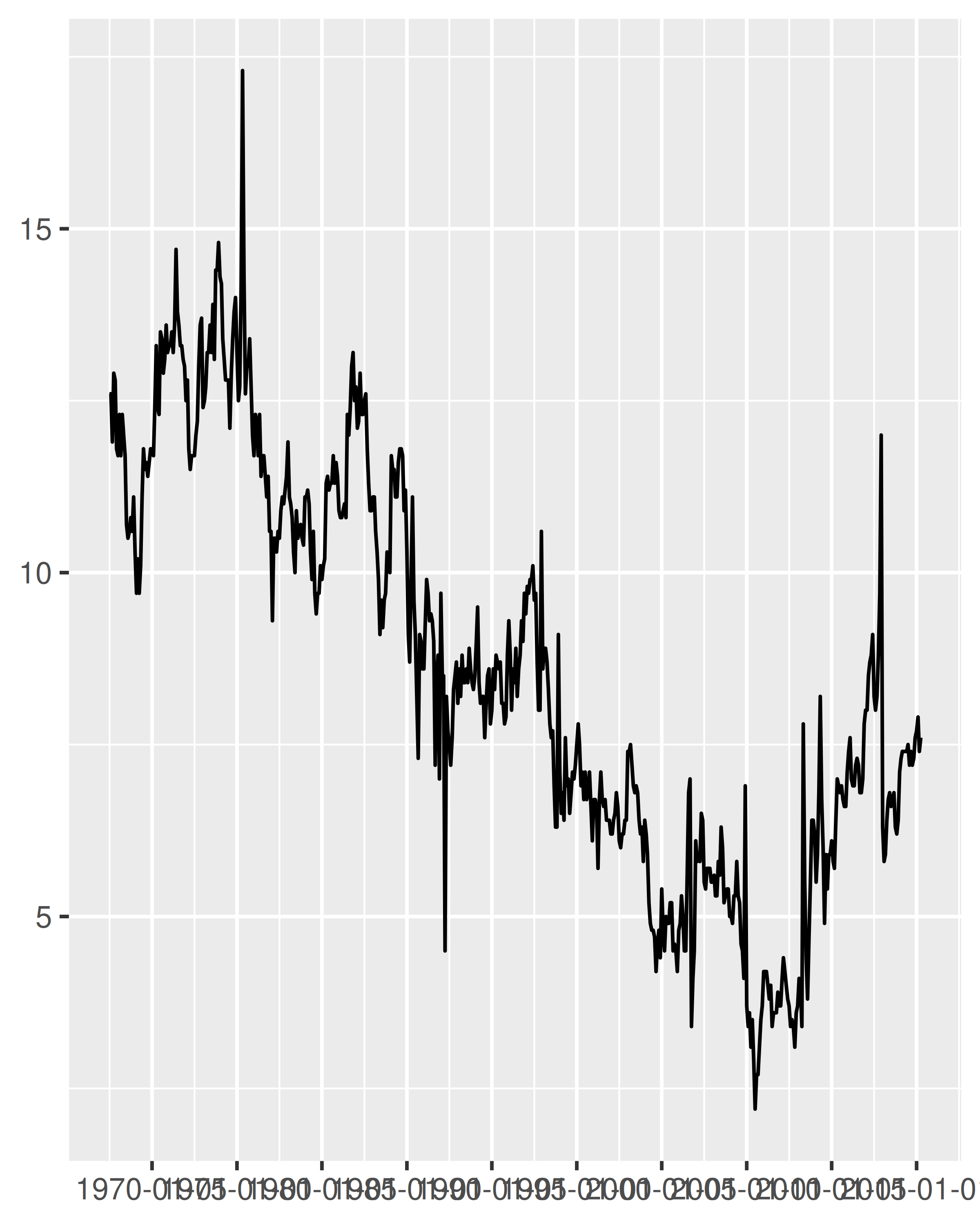
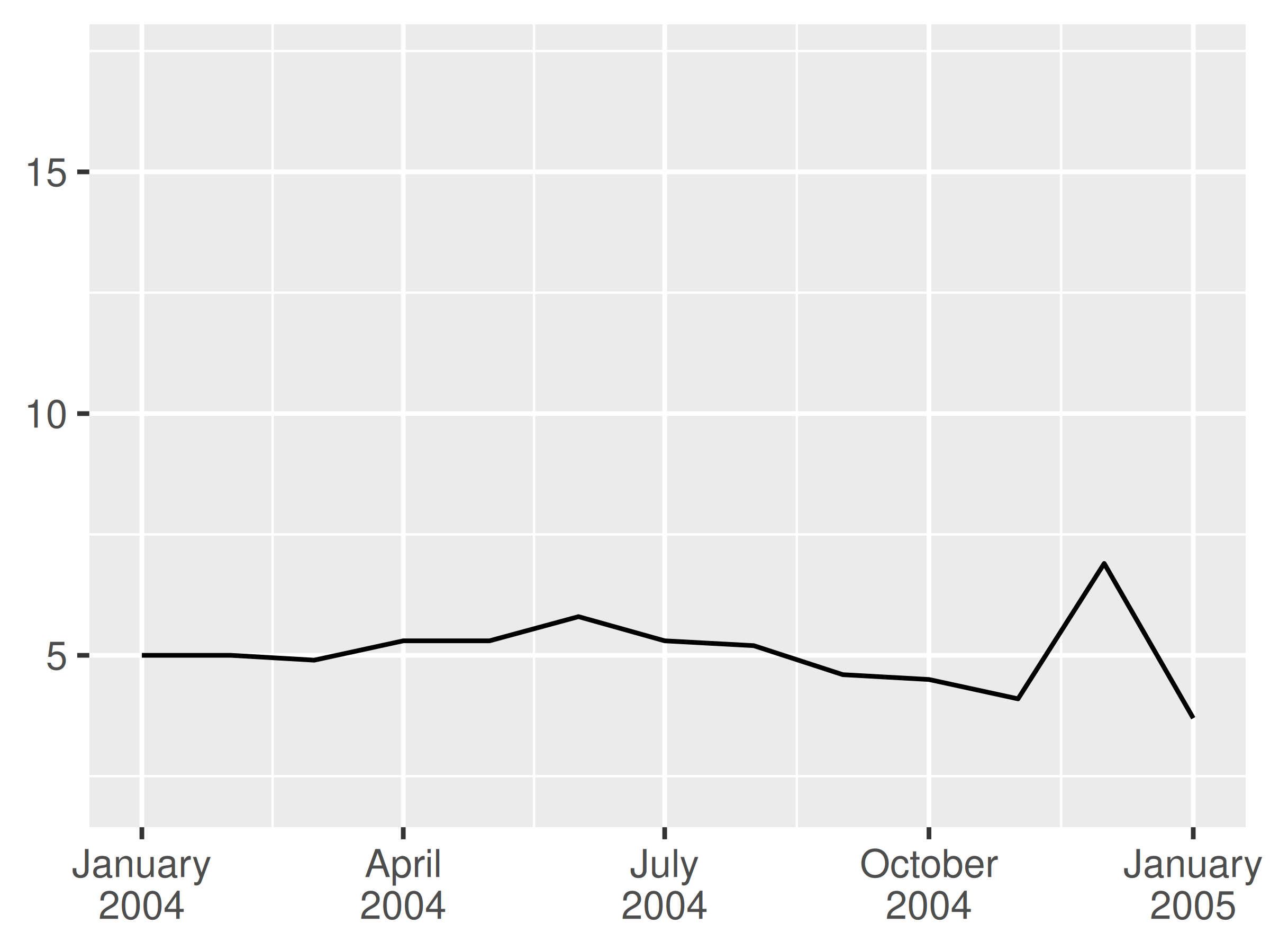
Puede resultar útil incluir el carácter de salto de línea \n en una cadena de formato, especialmente cuando se incluyen nombres completos de meses:
lim <- as.Date(c("2004-01-01", "2005-01-01"))
base + scale_x_date(limits = lim, date_labels = "%b %y")
base + scale_x_date(limits = lim, date_labels = "%B\n%Y")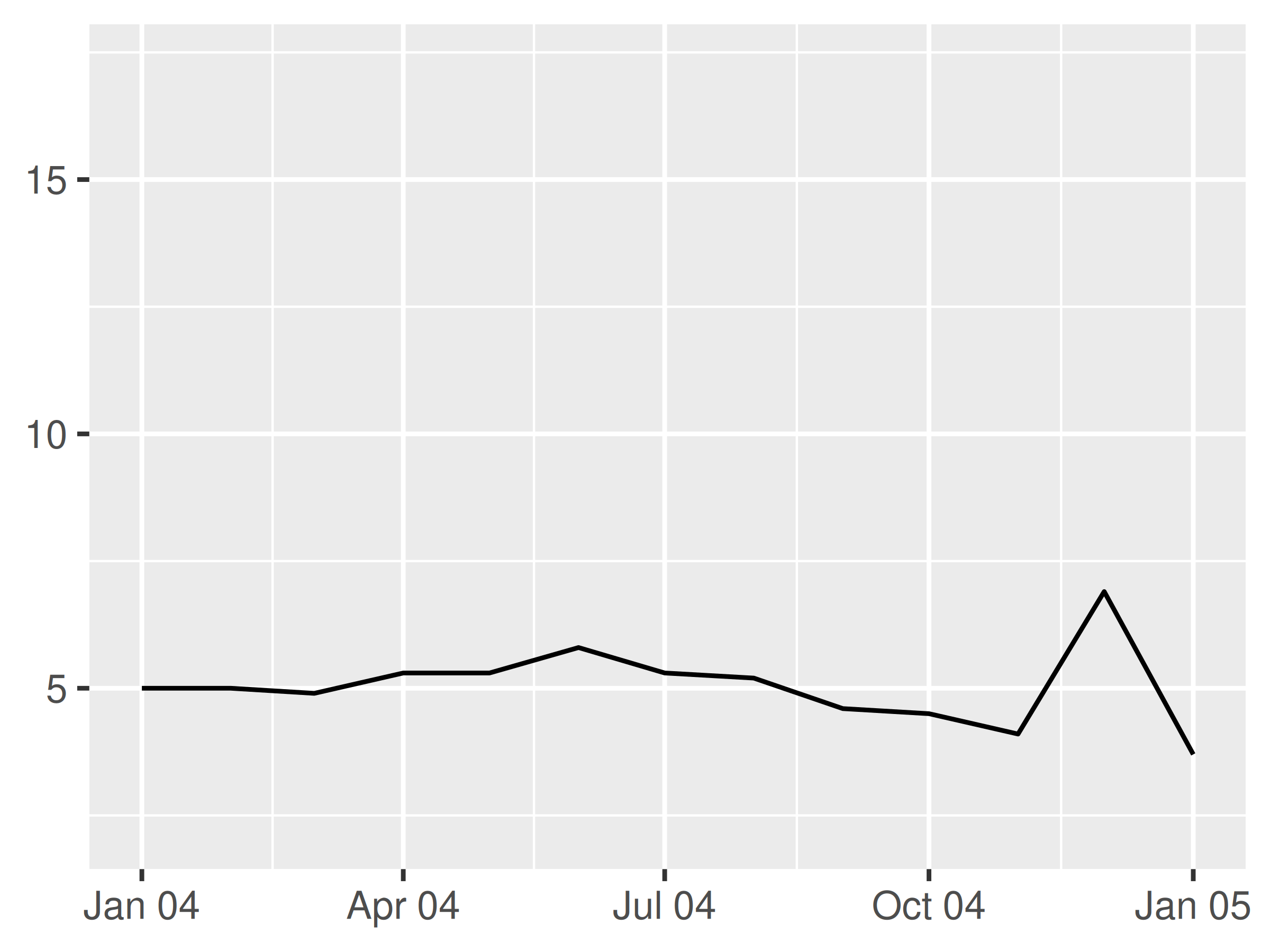
En estos ejemplos hemos especificado las etiquetas manualmente mediante el argumento date_labels. Un enfoque alternativo es pasar una función de etiquetado al argumento labels, de la misma manera que describimos en Sección 10.1.6. Puede escribir su propia función de etiquetado personalizada, pero esto suele ser innecesario. El paquete scales proporciona funciones convenientes que pueden generar etiquetas para usted, en particular scales::label_date() y scales::label_date_short(). Rara vez necesitas llamar a scales::label_date() directamente, porque esa es la función que usa date_labels. Sin embargo, si desea utilizar scales::label_date_short() deberá hacerlo explícitamente. El objetivo de label_date_short() es construir automáticamente etiquetas cortas que sean suficientes para identificar de forma única las fechas:
base +
scale_x_date(
limits = lim,
labels = scales::label_date_short()
)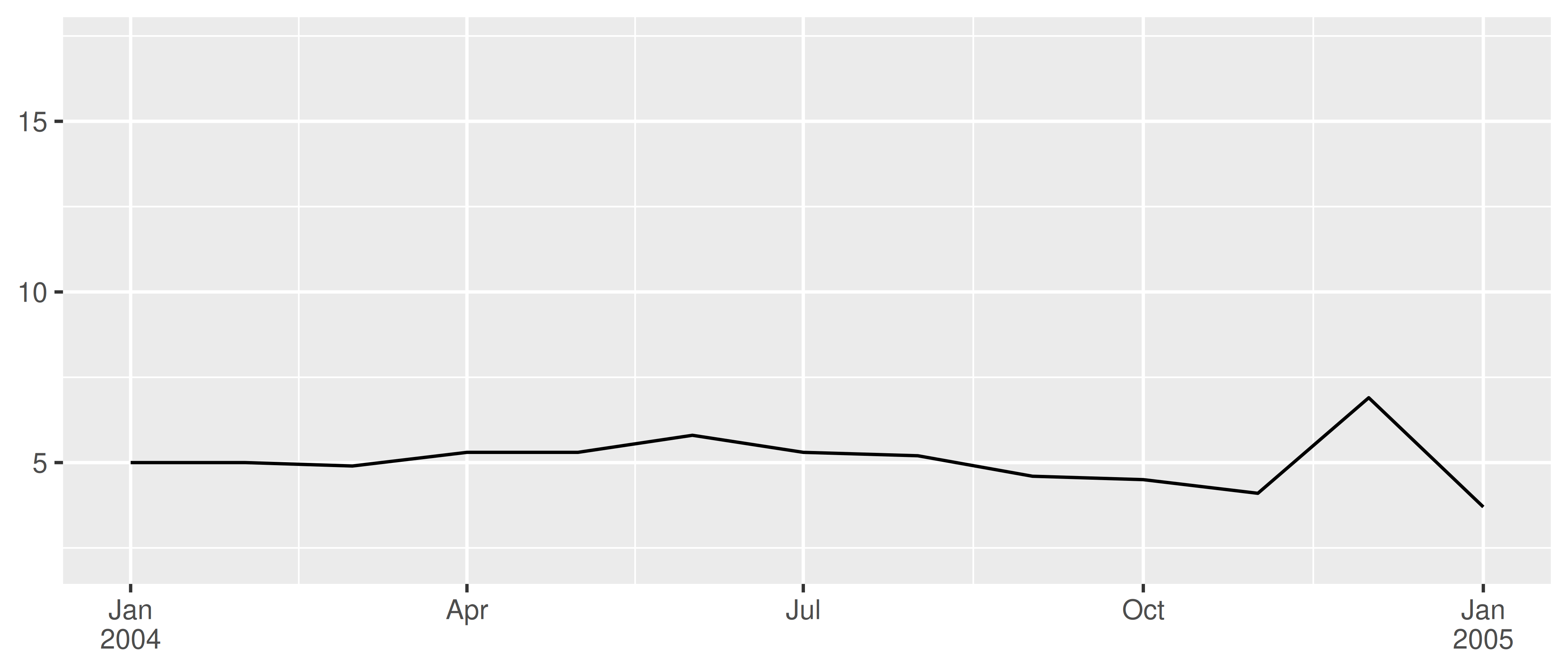
A menudo, esto puede producir gráficas más claras: en el ejemplo anterior, cada año se etiqueta solo una vez en lugar de aparecer en cada etiqueta, lo que reduce la cantidad de desorden visual y facilita al espectador ver dónde comienza y termina cada año.
10.3 Escalas de posición discreta
También es posible asignar variables discretas a escalas de posición, siendo las escalas predeterminadas scale_x_discrete() y scale_y_discrete(). Por ejemplo, las siguientes dos especificaciones de trazado son equivalentes
ggplot(mpg, aes(x = hwy, y = class)) +
geom_point()
ggplot(mpg, aes(x = hwy, y = class)) +
geom_point() +
scale_x_continuous() +
scale_y_discrete()Internamente, ggplot2 maneja escalas discretas asignando cada categoría a un valor entero y luego dibujando la geom en la ubicación de coordenadas correspondiente. Para ilustrar esto, podemos agregar una anotación personalizada (consulte Sección 8.3) al gráfico:
ggplot(mpg, aes(x = hwy, y = class)) +
geom_point() +
annotate("text", x = 5, y = 1:7, label = 1:7)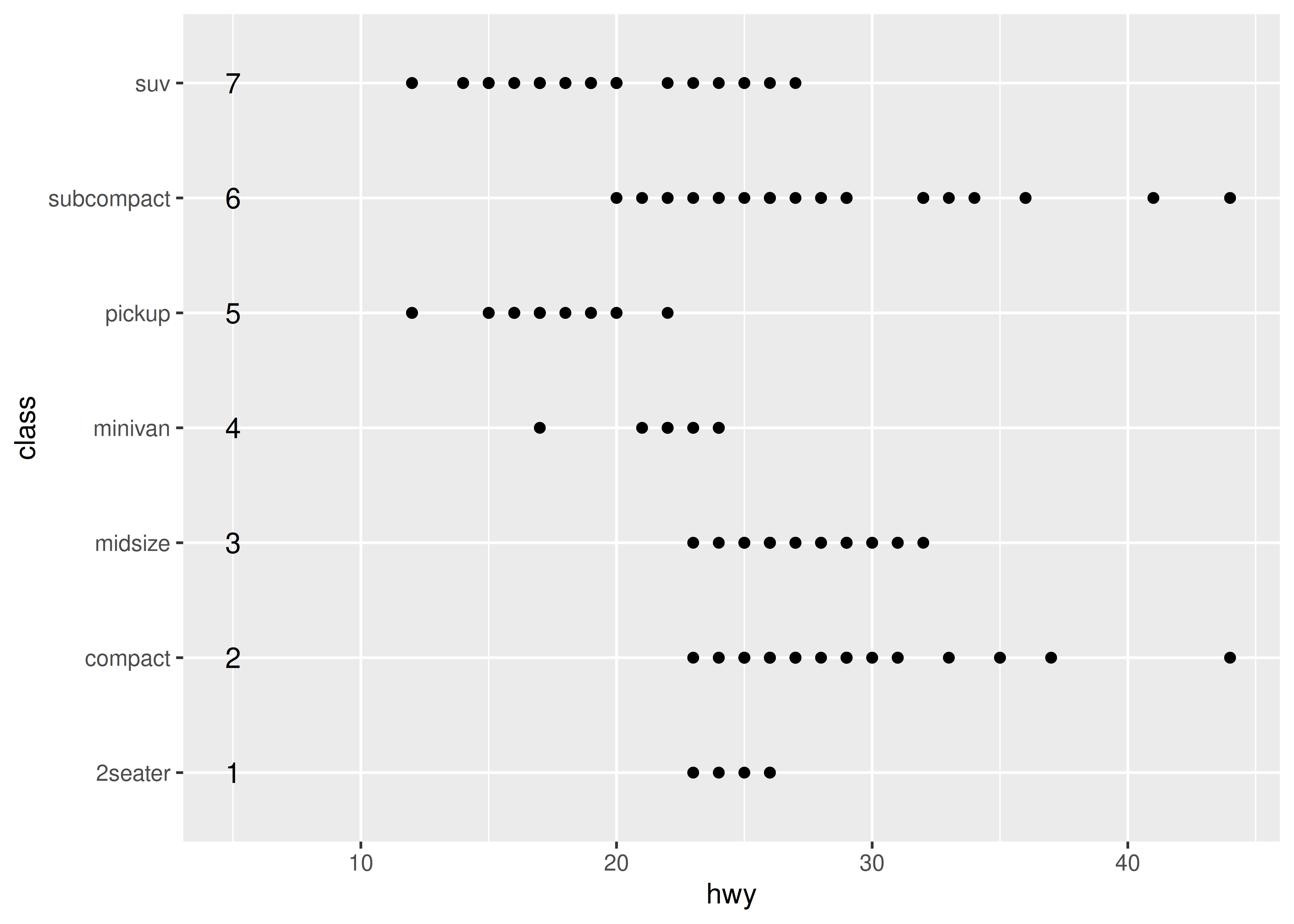
Mapear cada categoría a un valor entero es útil porque significa que se pueden especificar otras cantidades de ancho como una proporción del rango de categorías. Por ejemplo, en el gráfico anterior, podríamos especificar una fluctuación vertical para cada punto que abarque la mitad del ancho del contenedor de categorías implícito:
ggplot(mpg, aes(x = hwy, y = class)) +
geom_jitter(width = 0, height = .25) +
annotate("text", x = 5, y = 1:7, label = 1:7)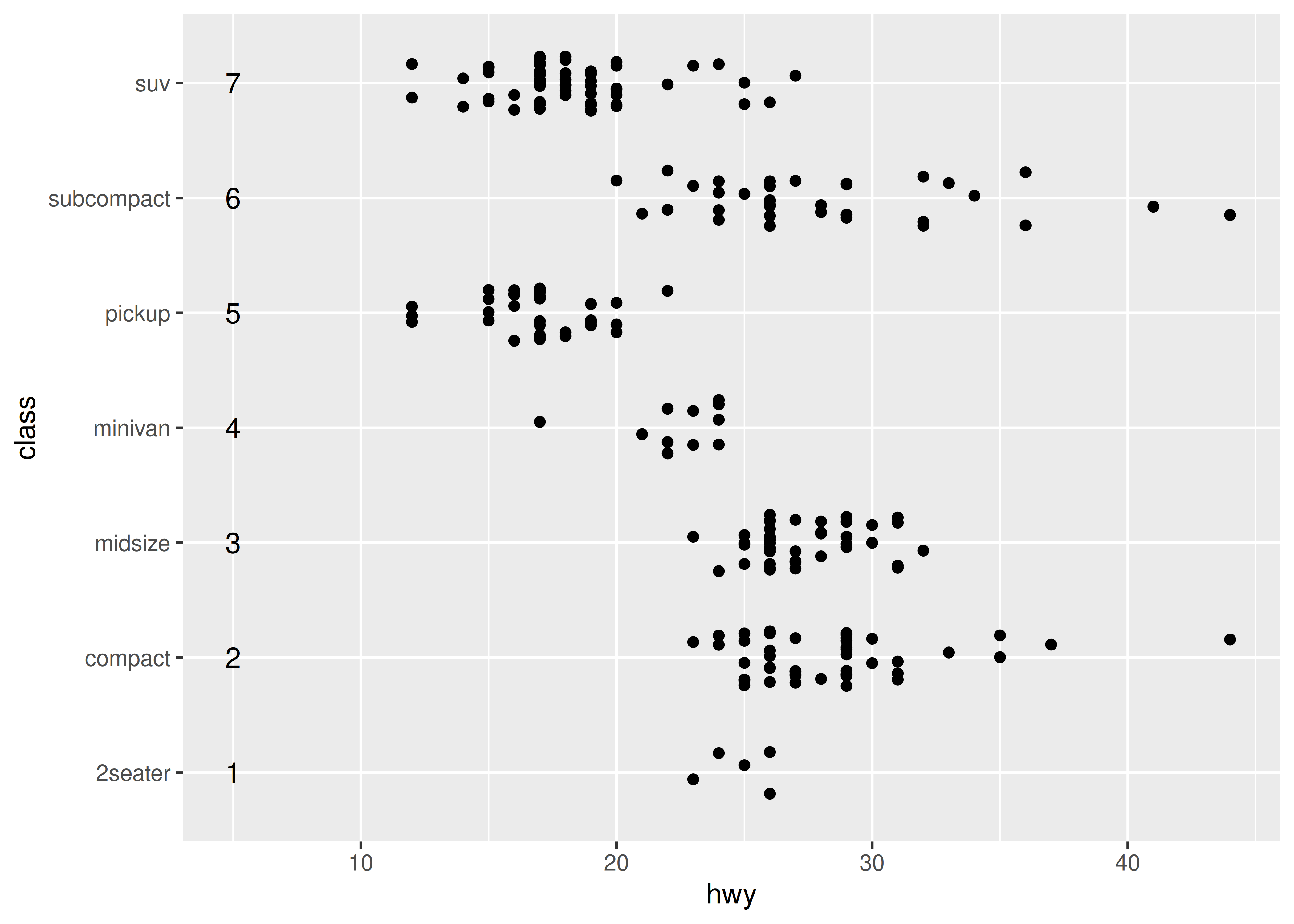
El mismo mecanismo sustenta los anchos de las barras y los diagramas de caja. Debido a que cada categoría tiene un ancho de 1 en una escala discreta, establecer width = .4 cuando se usa geom_boxplot() garantiza que el cuadro ocupe el 40% del ancho asignado a la categoría:
ggplot(mpg, aes(x = drv, y = hwy)) + geom_boxplot()
ggplot(mpg, aes(x = drv, y = hwy)) + geom_boxplot(width = .4)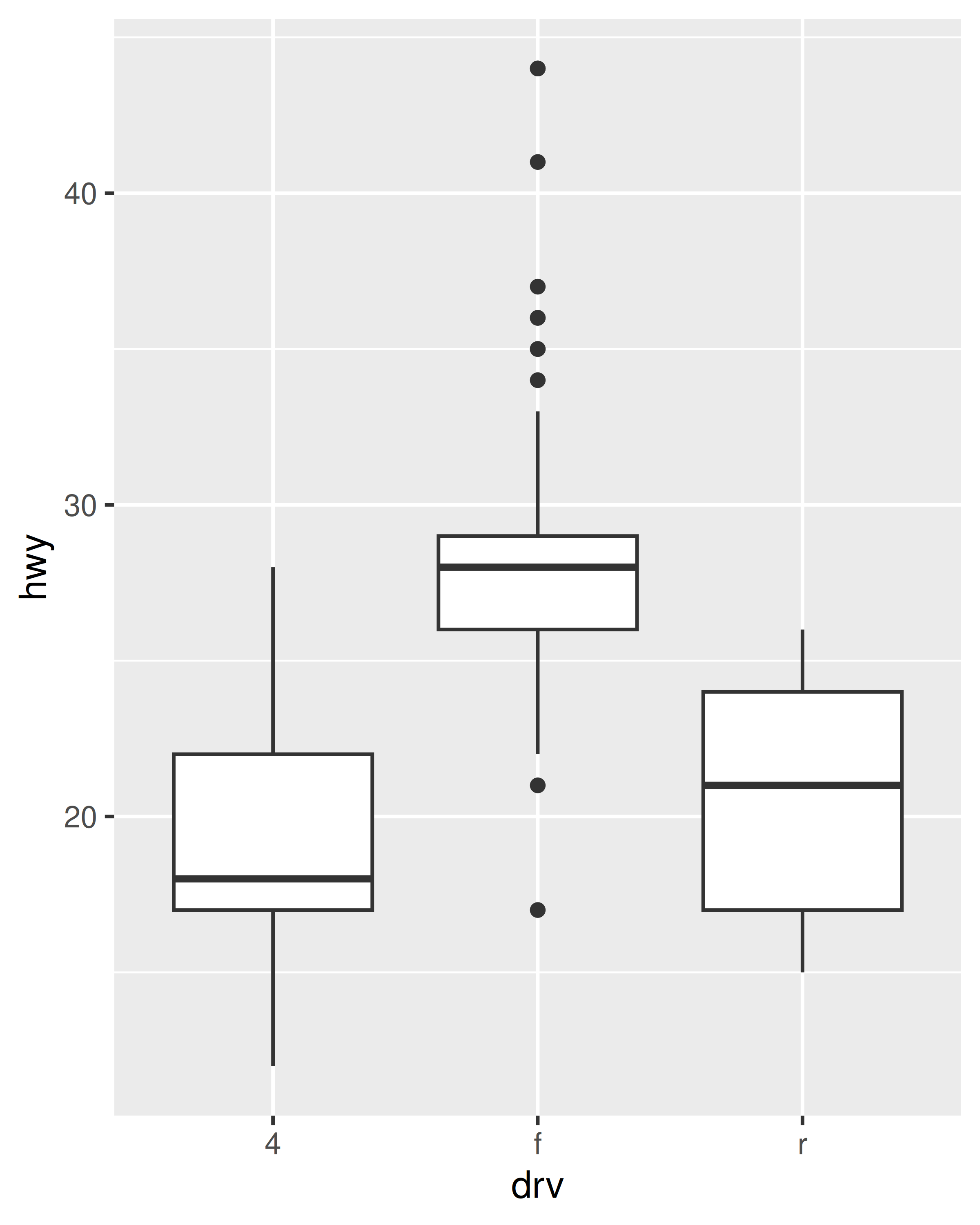
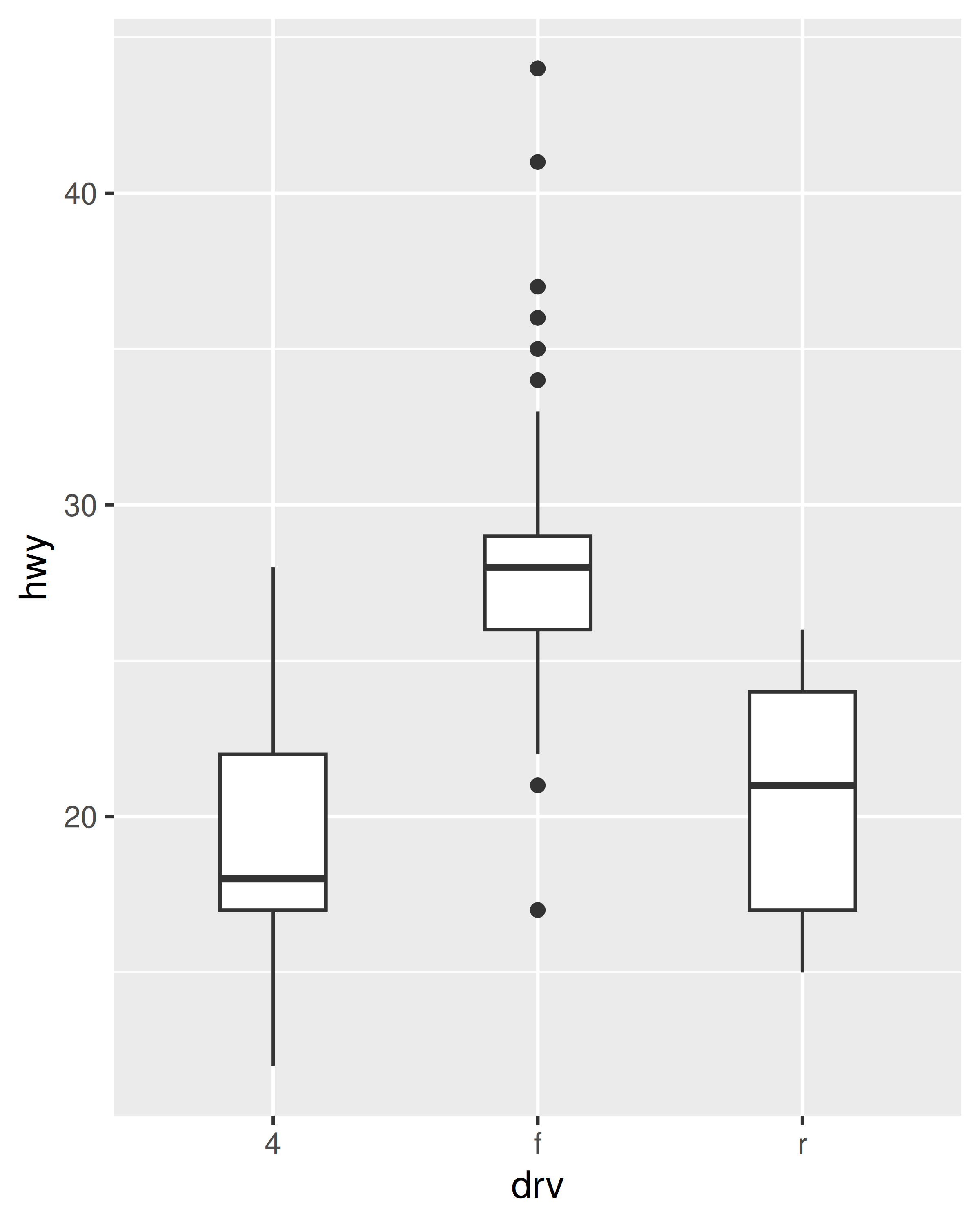
10.3.1 Límites, rupturas y etiquetas
Los límites, se rompe. y las etiquetas para una escala de posición discreta se pueden establecer usando los argumentos limits, breaks y labels. En su mayor parte, estos se comportan de manera idéntica a los argumentos correspondientes para escalas numéricas (Sección 10.1), aunque existen algunas diferencias. Por ejemplo, los límites de una escala discreta no se definen en términos de puntos finales, sino que corresponden al conjunto de valores permitidos para esa variable. En consecuencia, ggplot2 espera que los limits de una escala discreta sean un vector de caracteres que enumere todos los valores posibles en el orden en que deberían aparecer:
base <- ggplot(toy, aes(const, txt)) +
geom_label(aes(label = txt)) +
scale_x_continuous(breaks = NULL) +
labs(x = NULL, y = NULL)
base
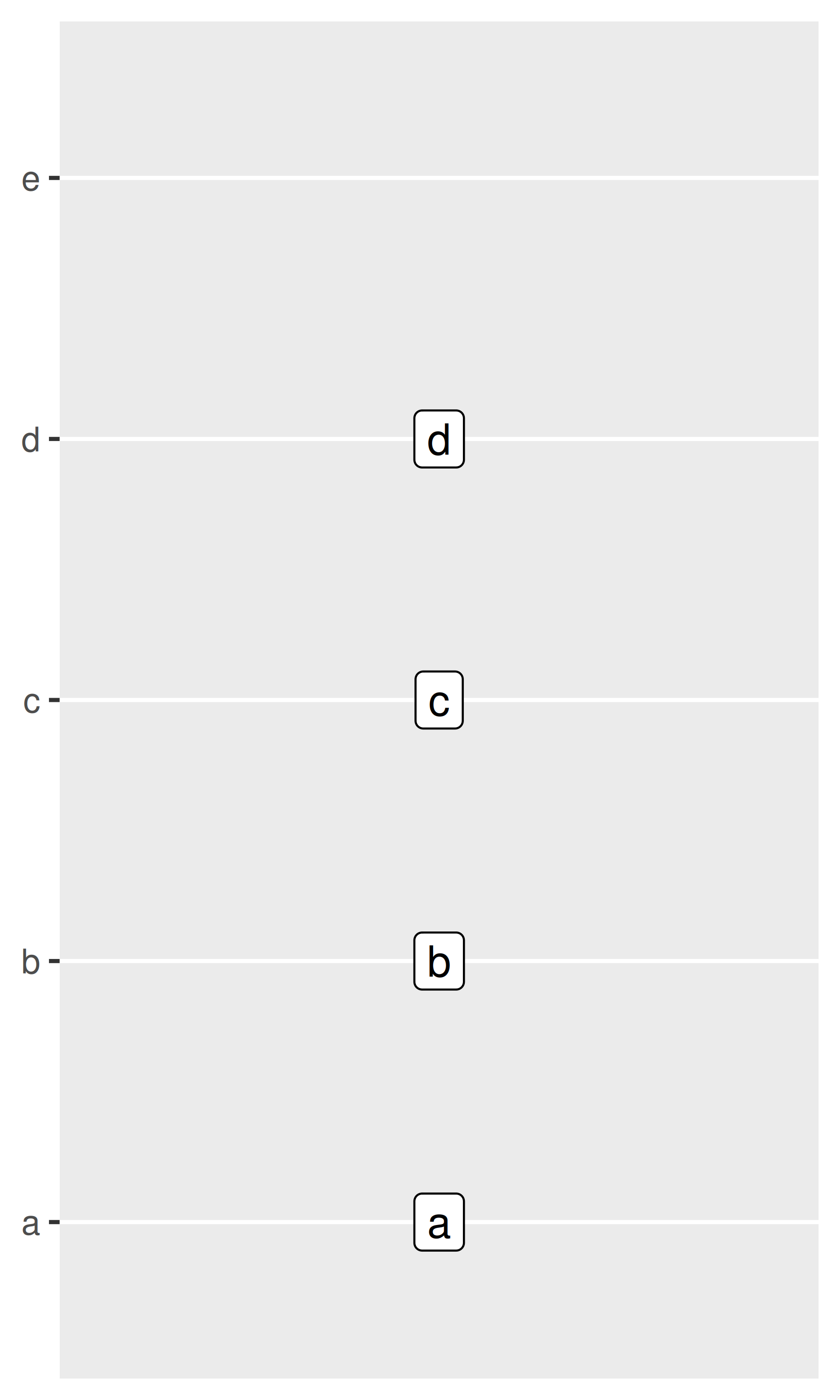
base + scale_y_discrete(limits = c("a", "b", "c", "d", "e"))
base + scale_y_discrete(limits = c("d", "c", "a", "b"))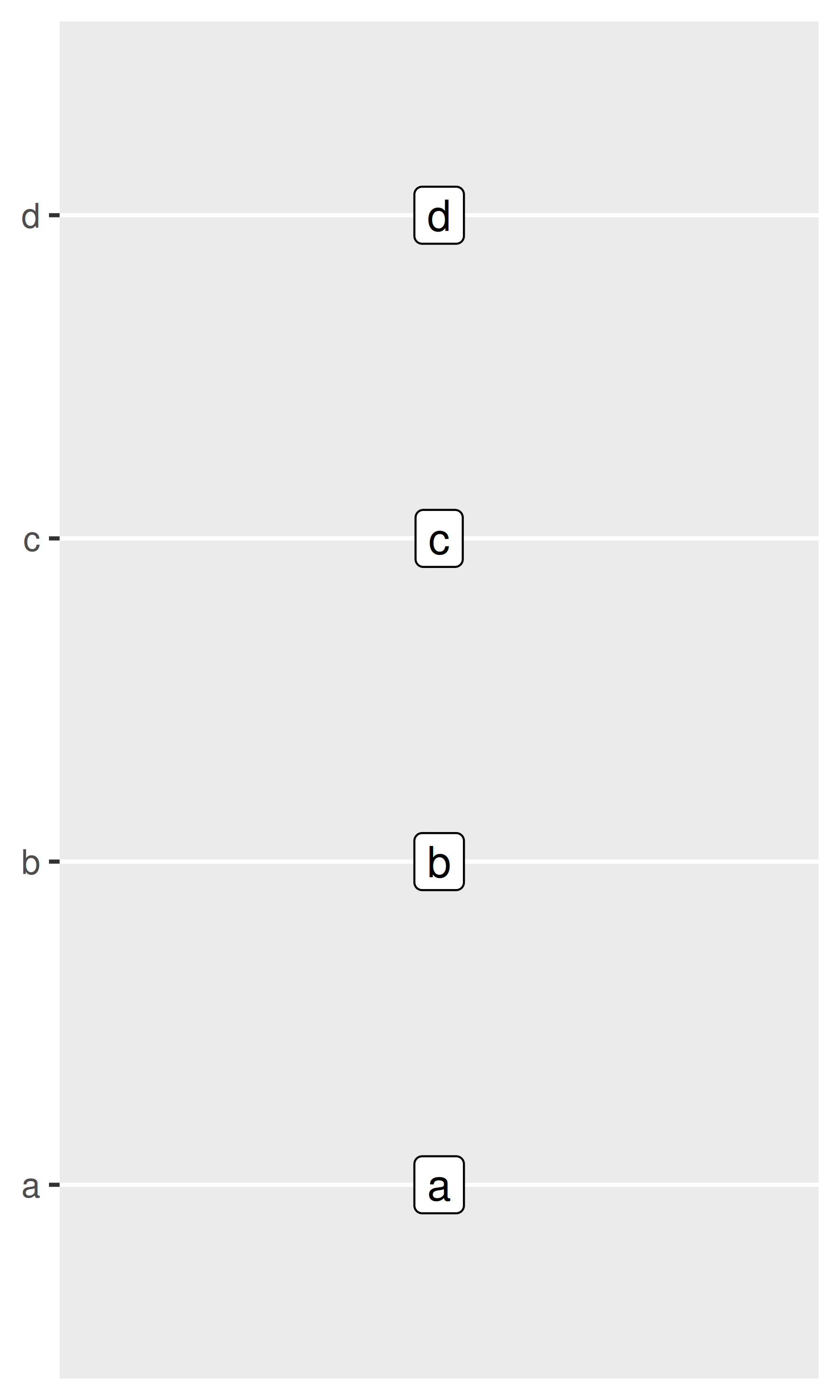
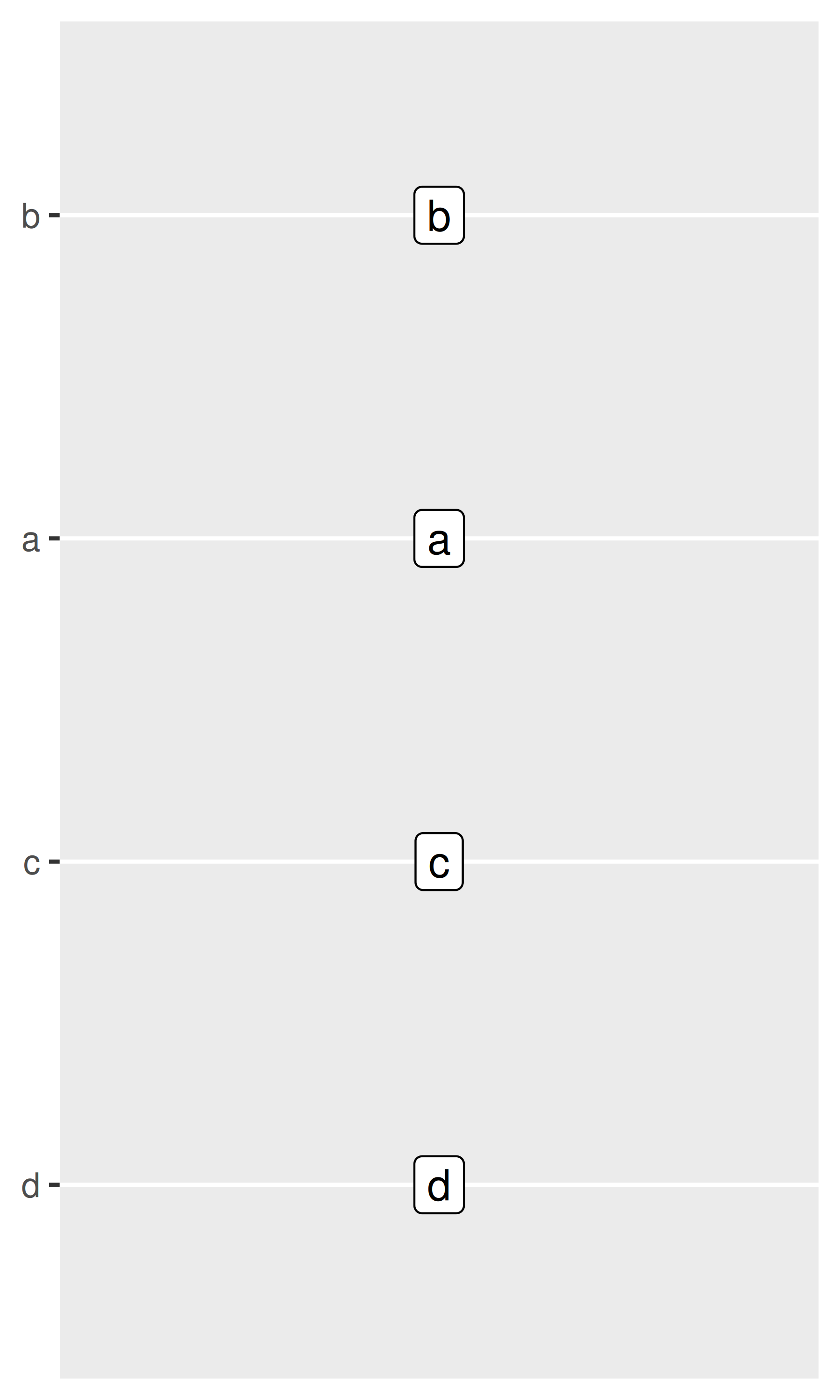
El argumento breaks prácticamente no ha cambiado y enumera un conjunto de valores que se mostrarán en las etiquetas de los ejes. El argumento labels para escalas discretas tiene alguna funcionalidad adicional: también tiene la opción de usar un vector con nombre para establecer las etiquetas asociadas con valores particulares. Esto permite cambiar unas etiquetas y otras no, sin alterar el orden ni las rupturas:
base + scale_y_discrete(breaks = c("b", "c"))
base + scale_y_discrete(labels = c(c = "carrot", b = "banana")) 
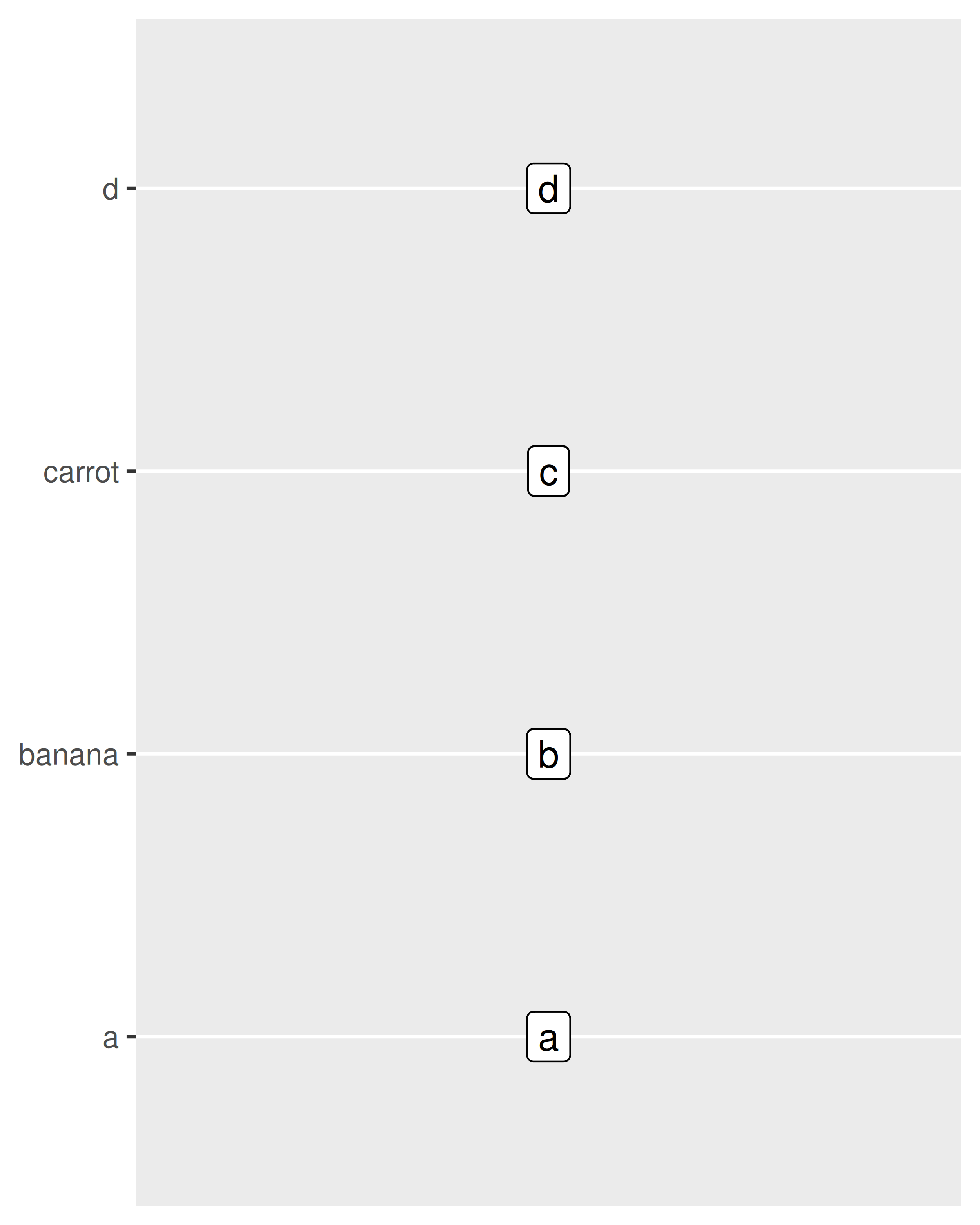
Al igual que con otras escalas, las escalas de posición discreta le permiten pasar una función al argumento labels. La función scales::label_wrap() puede ser particularmente valiosa para datos categóricos, ya que le permite ajustar cadenas largas en varias líneas.
10.3.2 Posiciones de etiquetas
Al trazar datos categóricos, a menudo es necesario mover las etiquetas de los ejes de alguna manera para evitar que se superpongan:
base <- ggplot(mpg, aes(manufacturer, hwy)) + geom_boxplot()
base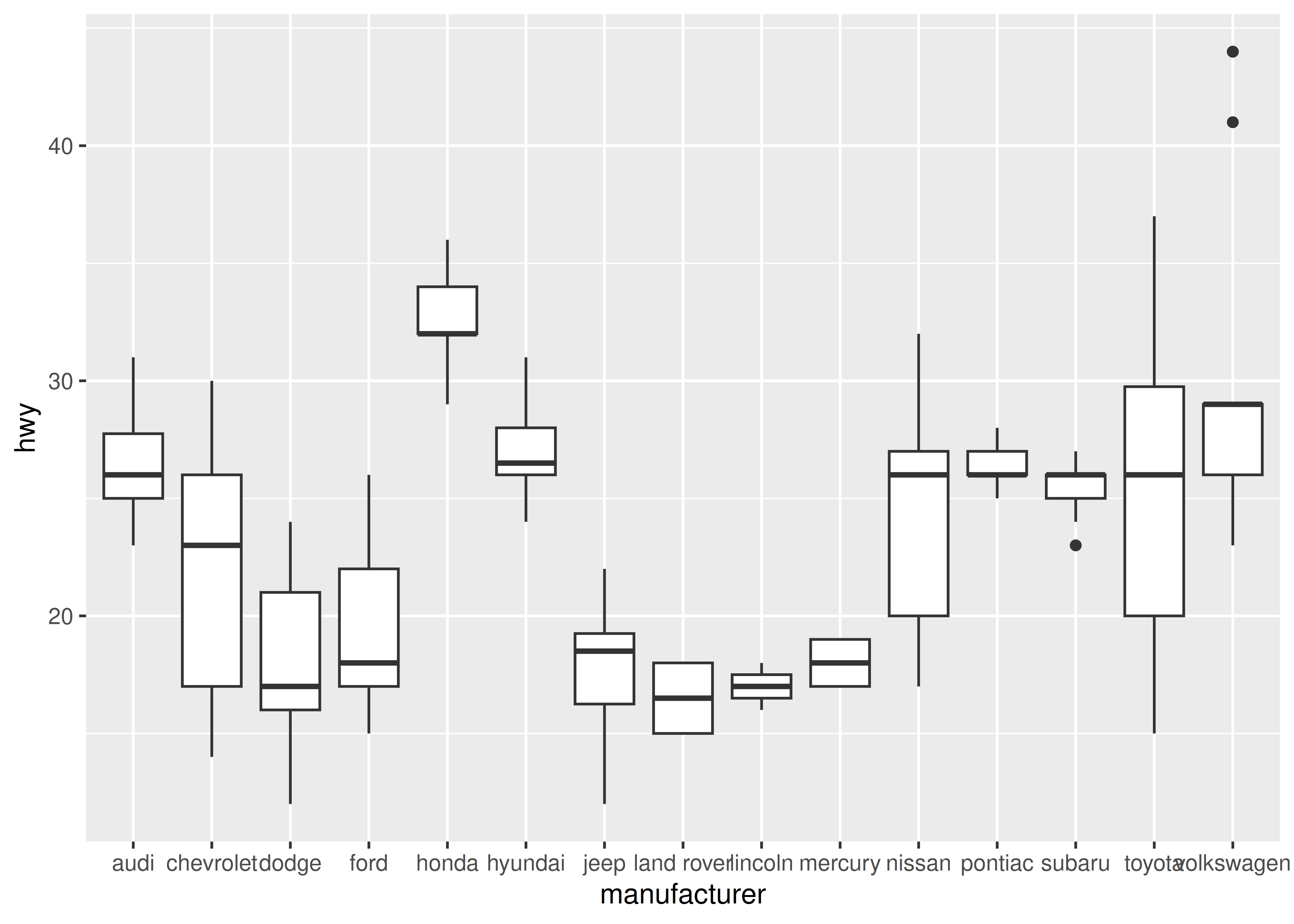
Incluso cuando se le asigna mucho espacio horizontal, las etiquetas de los ejes se superponen considerablemente en este gráfico. Podemos controlar esto con la ayuda de la función guides(), que funciona de manera similar a la función auxiliar labs() descrita en Sección 8.1. Ambos toman el nombre de diferentes estéticas (por ejemplo, color, x, relleno) como argumentos y le permiten especificar su propio valor. Para una estética de posición, usamos guide_axis() para indicarle a ggplot2 cómo queremos modificar las etiquetas de los ejes. Por ejemplo, podríamos decirle a ggplot2 que “esquive” la posición de las etiquetas configurando guide_axis(n.dodge = 3), o que las rote configurando guide_axis(angle = 90):
base + guides(x = guide_axis(n.dodge = 3))
base + guides(x = guide_axis(angle = 90))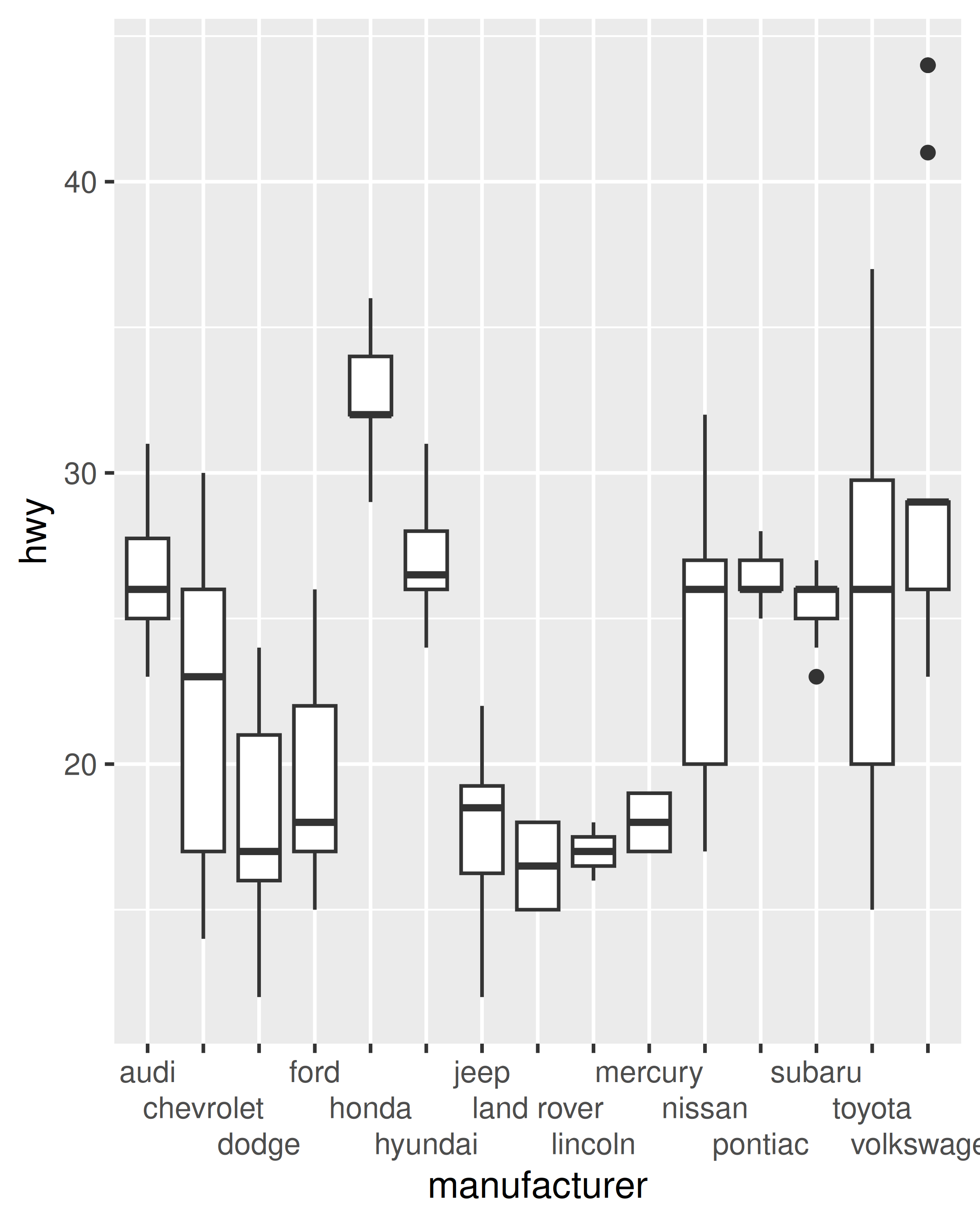
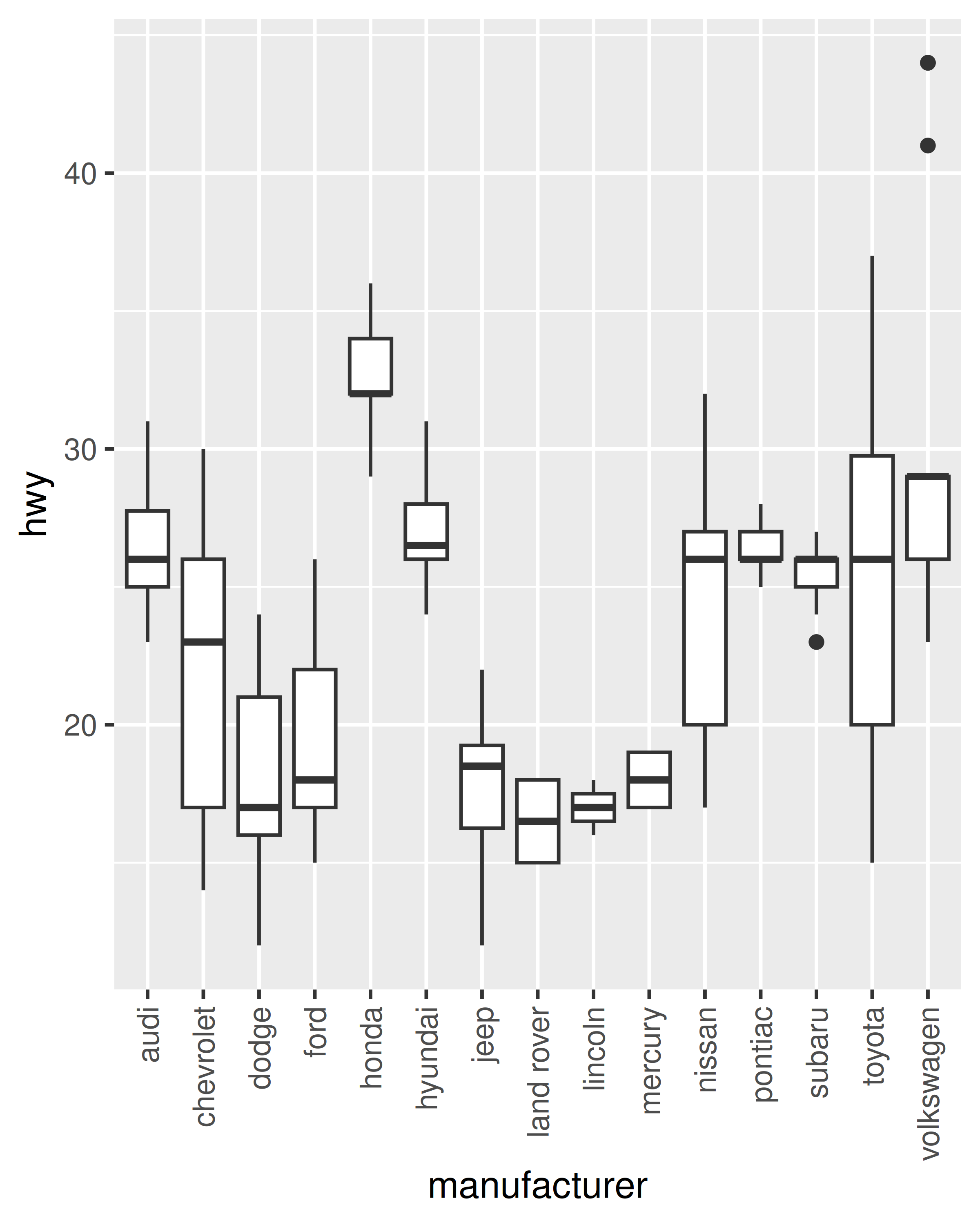
Tenga en cuenta que, de la misma manera que labs() es una forma abreviada de especificar el argumento name en una o más escalas, la función guides() es una forma abreviada de establecer los argumentos guide en una o más escalas. Entonces el siguiente código logra el mismo resultado:
base + scale_x_discrete(guide = guide_axis(n.dodge = 3))
base + scale_x_discrete(guide = guide_axis(angle = 90))Para obtener más información sobre las funciones de guía, consulte Sección 14.5.
10.4 Escalas de posición agrupadas
Una variación de las escalas de posición discretas son las escalas agrupadas, donde una variable continua se divide en varias ubicaciones y se traza la variable discretizada. Para la estética de la posición, las escalas agrupadas se utilizan principalmente para crear histogramas y gráficos relacionados. El siguiente ejemplo muestra cómo aproximar el comportamiento de geom_histogram() usando geom_bar() en combinación con una escala de posición agrupada:
ggplot(mpg, aes(hwy)) + geom_histogram(bins = 8)
ggplot(mpg, aes(hwy)) +
geom_bar() +
scale_x_binned() 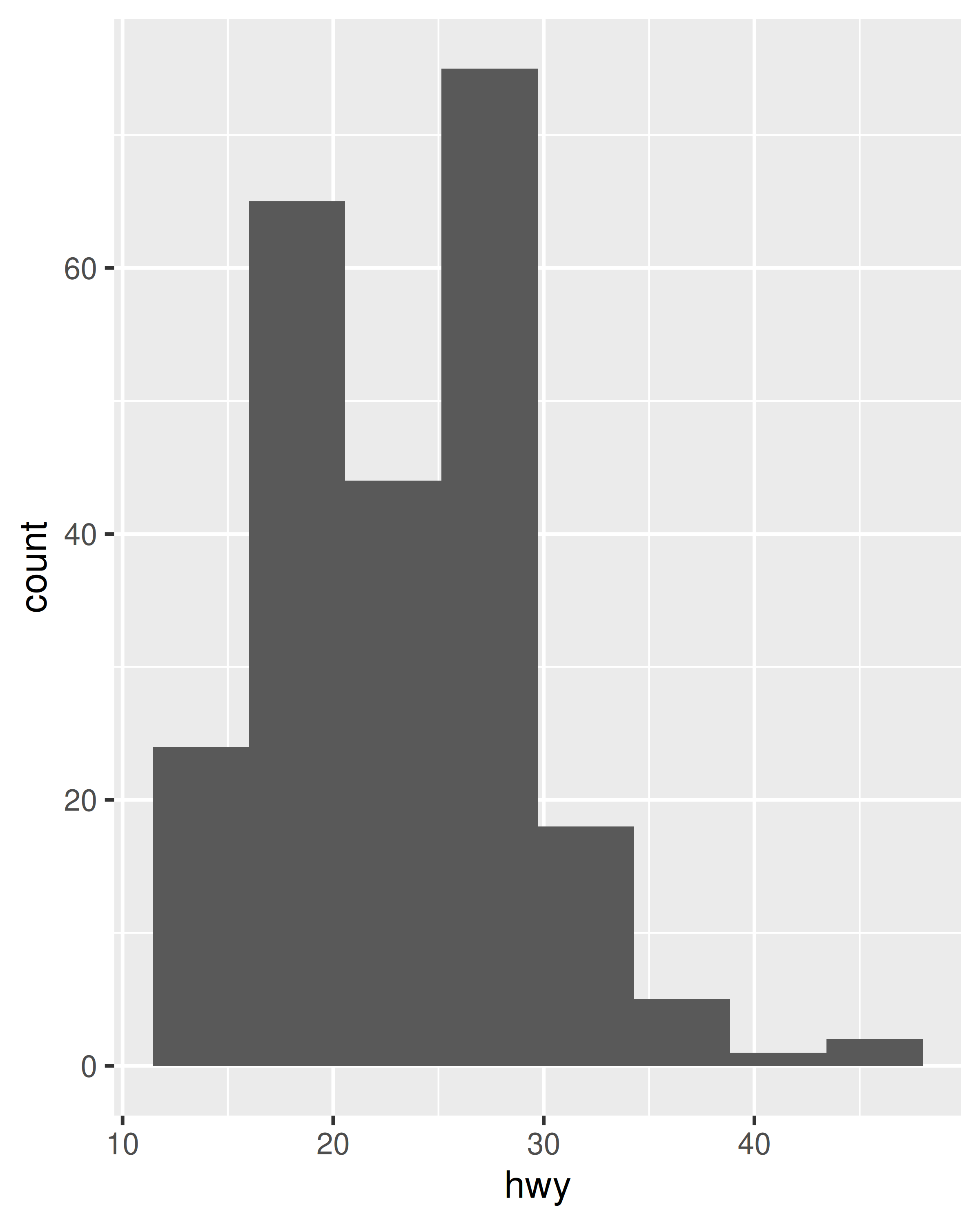
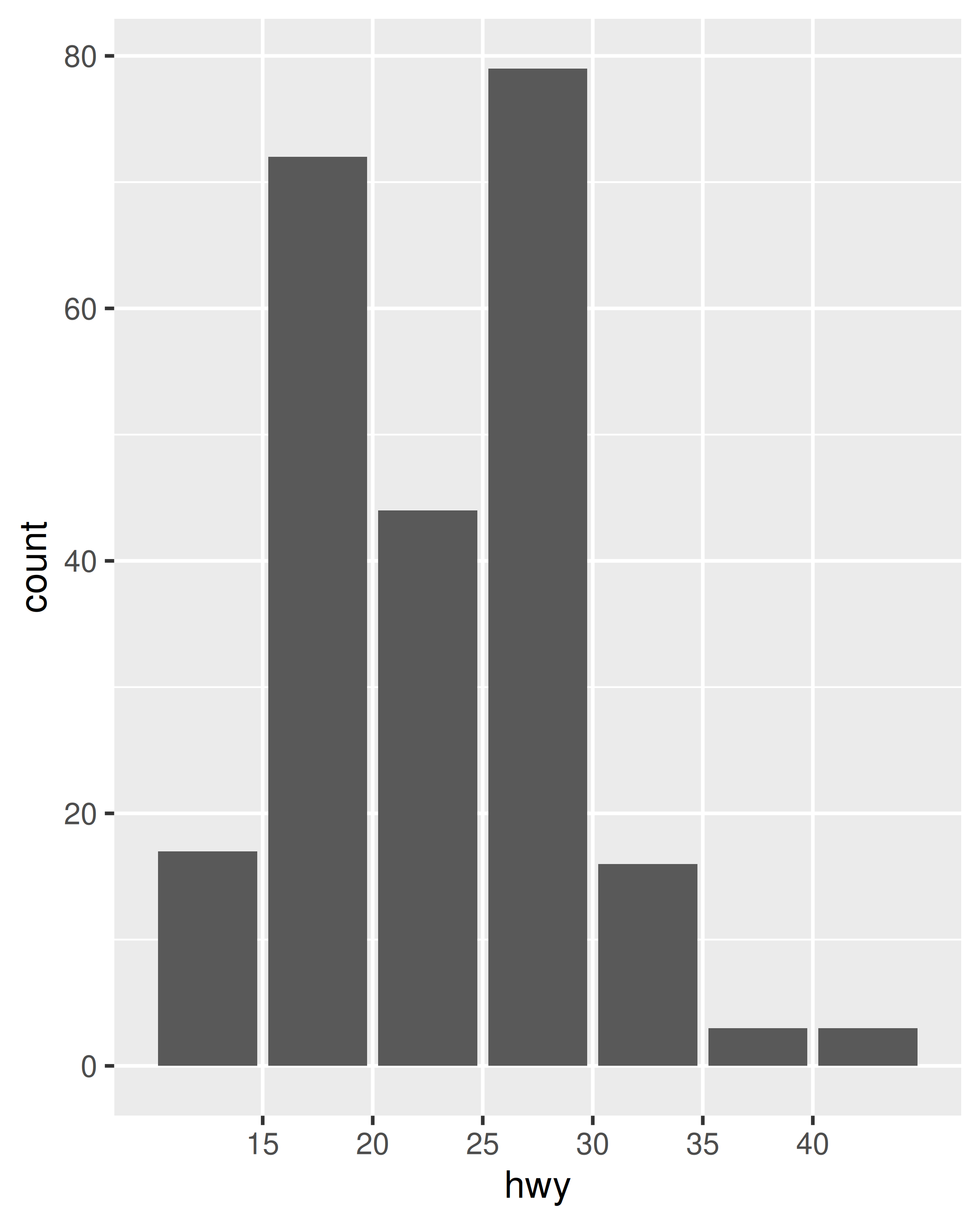
En la práctica, este no es el ejemplo más útil, ya que geom_histogram() ya existe y proporciona valores predeterminados que generalmente son más apropiados para histogramas, pero la técnica se puede ampliar. Supongamos que queremos usar geom_count() en lugar de geom_point() para mostrar el número de observaciones en cada ubicación. La ventaja de geom_count() es que el tamaño de cada punto aumenta con el número de observaciones en cada ubicación, pero como ilustra la siguiente figura, este método no funciona muy bien cuando los datos varían continuamente:
base <- ggplot(mpg, aes(displ, hwy)) +
geom_count()
base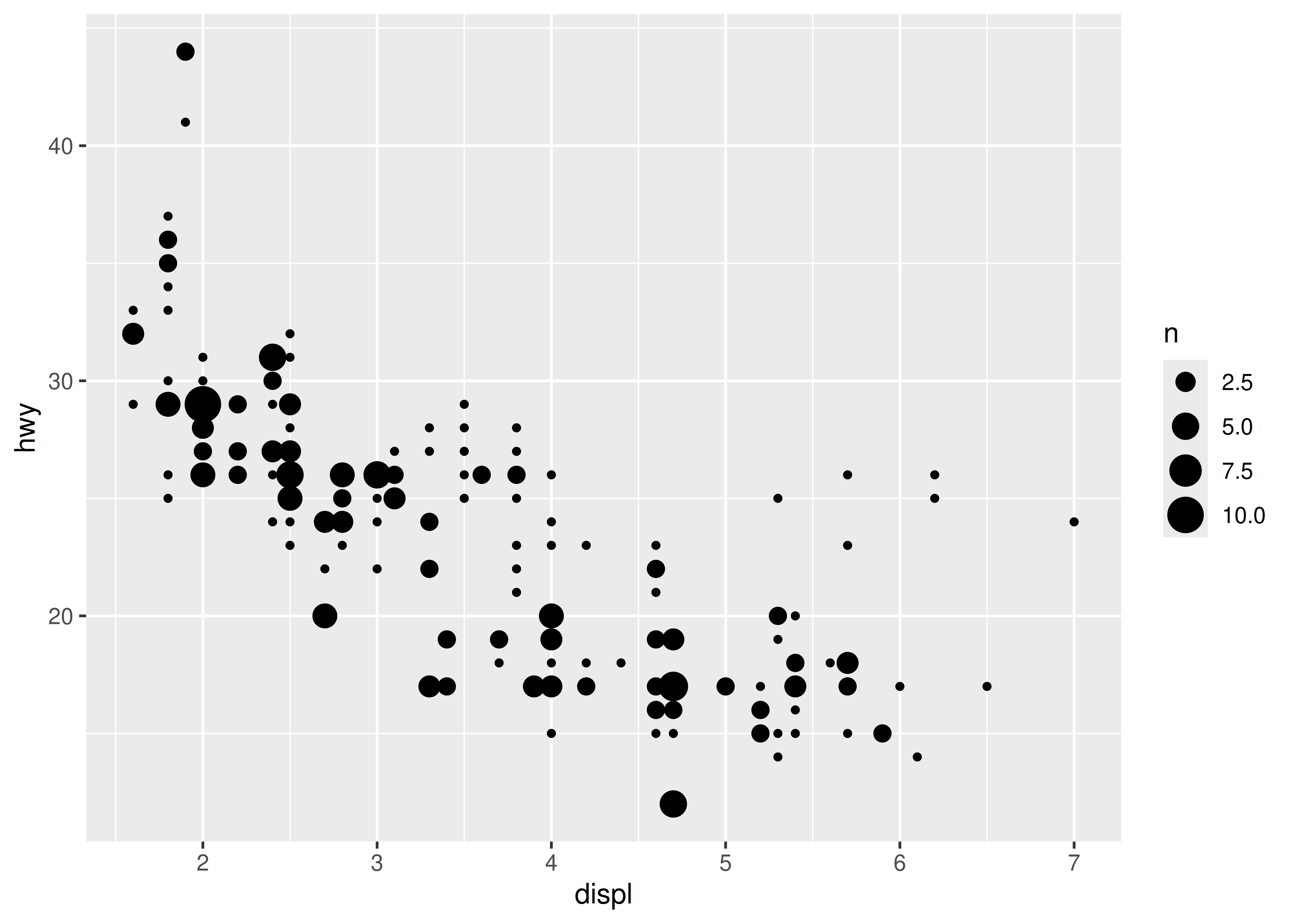
Esta gráfica está bastante desordenada y no es particularmente fácil de leer. Para mejorar esto, podemos usar scale_x_binned() para cortar los valores en contenedores antes de pasarlos a la geom:
base +
scale_x_binned(n.breaks = 15) +
scale_y_binned(n.breaks = 15)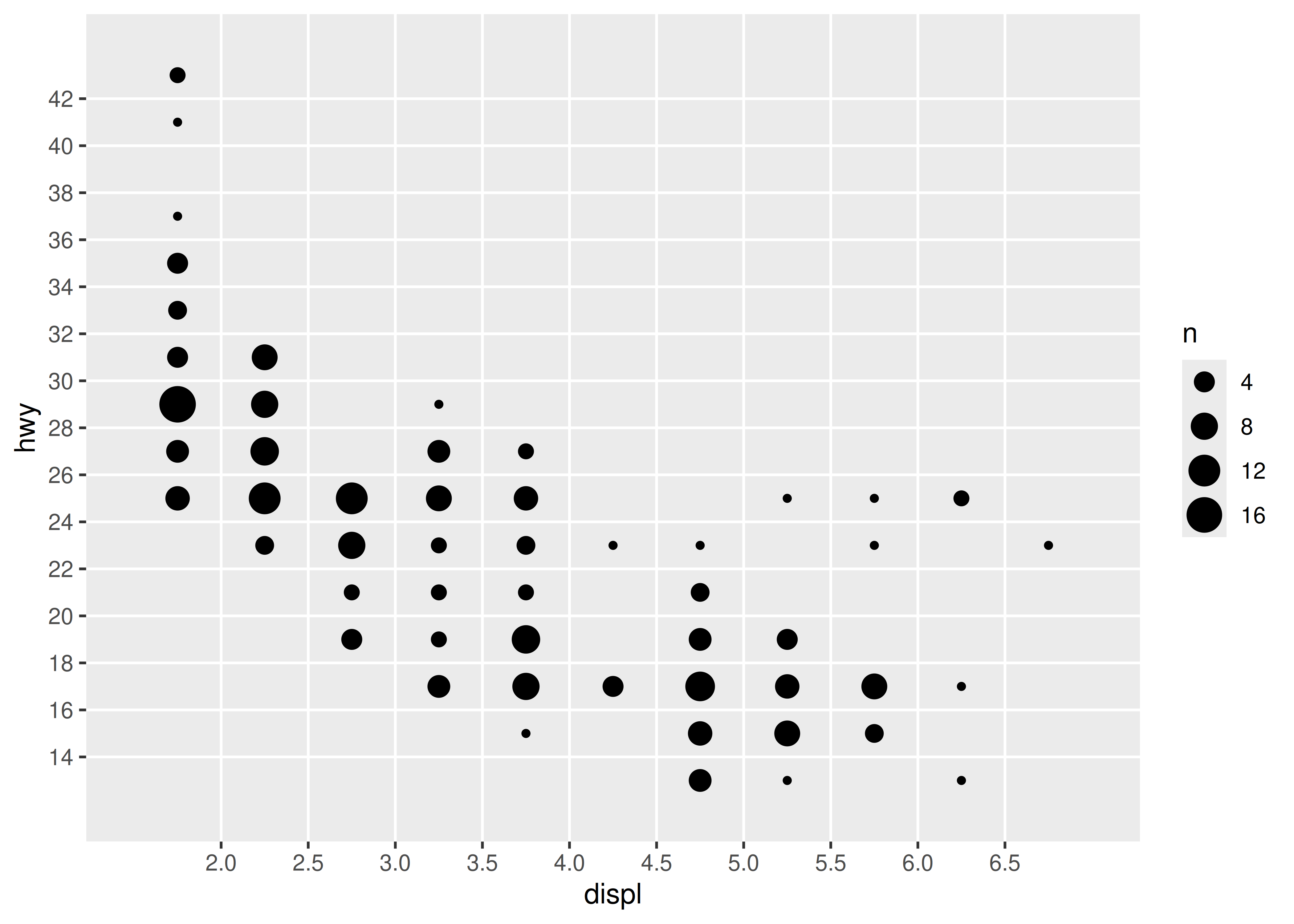
Puede leer más sobre cómo se utilizan las escalas agrupadas para la estética sin posición en ?sec-binned-color y Sección 12.1.2.
Grolemund, Garrett, y Hadley Wickham. 2011. «Dates and Times Made Easy with lubridate». Journal of Statistical Software 40 (3): 1-25. http://www.jstatsoft.org/v40/i03/.
Wickham, Hadley, y Dana Seidel. 2020. scales: Scale Functions for Visualization. https://CRAN.R-project.org/package=scales.